NLP
지식그래프에서 경로를 탐색하는 모델 AttnIO를 소개합니다
2020-12-14
이상형에 관한 설문조사를 보면 상위권에 오르는 유형 중 하나가 바로 ‘대화가 통하는 사람’입니다. 끊임없이 말을 주고받는 시간이 즐거워서 또 만나서 이야기를 나누고 싶다는 감정이 드는 상대를 의미하겠죠. 소개팅 자리에서 본인을 할리우드 영화감독 스티븐 스필버그(Steven Spielberg)의 팬이라 소개하며 대화 포문을 열었을 때, “그래요?”, “그렇군요…”, “아 네…”라기보다는, “저도요! 레오나르도 디카프리오가 주연을 맡은 ‘캐치 미 이프 유 캔’은 여러 번 봤을 정도로 음악도, 연기도, 연출도 모두 멋진 작품이었어요”라고 말하는 사람이 바로 여기에 해당할 겁니다.
사람과 대화를 나누는 기계를 만들 때도 위에서 언급한 ‘대화가 잘 통한다’는 느낌을 제공하는 게 중요합니다. 물론 지금 당장은 감정적 교감을 나누는 기계의 구현은 먼 미래의 일입니다. 이에 현재 산학계에서는 대화 맥락에 어울리는 유일한 정보를 제공하는 과제부터 순차 해결하는 데 집중하고 있습니다.
오늘날의 많은 대화 시스템은 언어 모델language model을 이용해 문장을 생성합니다. 특정 대상에 대한 지식을 보다 원활하게 획득하고자 최근에는 외부 지식 베이스knowledge base1를 활용하는 방식도 고려되고 있습니다. 올해 EMNLPEmpirical Methods in Natural Language Processing2에 게재된 카카오엔터프라이즈 AI Lab(이하 AI Lab)의 논문에서는 바로 이 지식 베이스 상에서 대화 맥락에 어울리는 (답변) 경로를 효과적으로 탐색하는 모델path retrieval model인 AttnIO[1]를 제안했습니다. 자연어처리에서 경험적 방법론을 다루는 올해 이 학회에서는 총 3,677개 중 754개의 논문이 통과됐습니다.
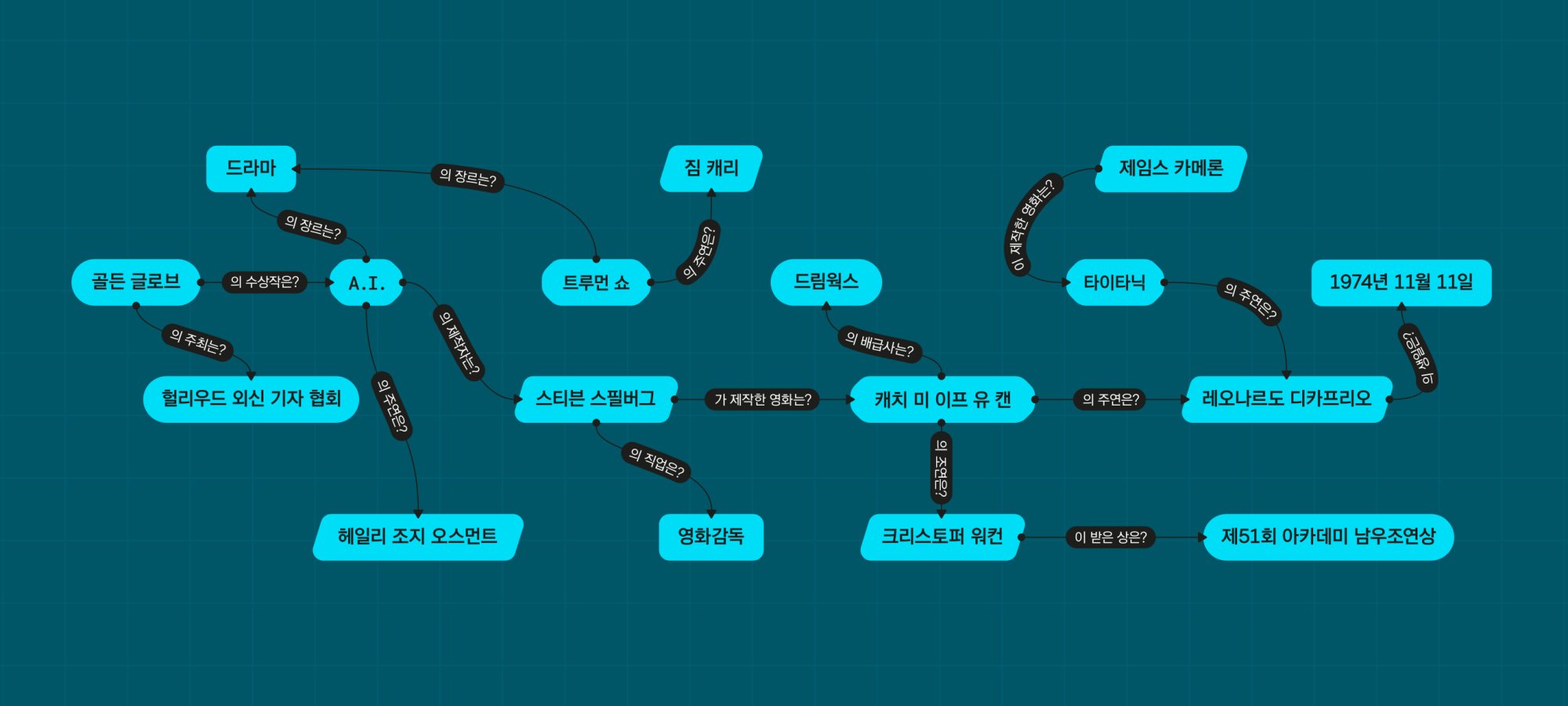
[ 그림 1 ] AttnIO가 지식 그래프에서 경로를 탐색하는 과정
이번 시간에는 바로 이 AttnIO를 자세히 소개해보고자 합니다. AI Lab AI기술실 컨텍스트팀 소속의 정재훈 연구원을 만나 기존 접근 방식의 한계, AI Lab이 제안한 AttnIO의 작동 과정과 그 성능, 그리고 향후 연구 계획에 관한 이야기를 들어봤습니다.
∙ ∙ ∙ ∙ ∙ ∙ ∙
지식 그래프를 활용하는 대화 시스템
산업 현장에서는 Seq2Seqsequence to sequence3 기반 언어 모델을 활용합니다. 이 언어 모델은 대량의 말뭉치를 사전학습하기만 해도 외부 지식external knowledge 일부를 습득할 수 있습니다. 영화에 대한 문서도 학습한 모델이라면, 스필버그 감독에 관한 지식을 내뱉을 수 있다는 의미입니다. 언어 모델 그 자체를 지식 베이스의 일종이라고 볼 수 있다고 한 ‘Language Models as Knowledge Bases?[2]‘라는 논문이 이를 뒷받침합니다.
하지만 언어 모델은 ‘스티븐 스필버그가 판타지 영화 해리포터를 연출했다’처럼 겉으로 보기엔 그럴싸해 보이나, 사실이 아닌 문장을 생성할 수 있다는 취약점을 지니고 있습니다. 언어 모델은 단어 시퀀스의 우도likelihood4를 최대화하는 방식으로 주어진 단어 다음에 올 단어를 예측합니다. 이 과정에서 모델은 스스로 문장에 포함된 의미가 사실에 근거하는지 아닌지를 구분하지 못합니다. 그래서 ‘스티븐 스필버그는 SF영화 A.I를 감독했다”라는 옳은 문장만큼이나, 위의 잘못된 예시 문장이 생성될 확률이 높아집니다.
앞서 설명한 학습 방식으로 인해 언어 모델은 입력된 문장과 관계없는 상투적인 표현을 내뱉기도 합니다[3]. 이는 훈련 데이터셋에 “안녕하세요”, “잘 몰라요”, “감사합니다”, “미안합니다”와 같은 표현의 높은 등장 빈도에 기인한 현상으로 분석됩니다. 또는 자주 함께 등장하는 주어와 동사, 또는 목적어를 포함한, 구체성이 떨어지는 문장이 생성될 수도 있습니다. 스티븐 스필버그가 누군지 묻는 말에 “아니 몰라” 또는, “스티븐 스필버그는 연출했다”, “스티븐 스필버그는 태어났다”로 대답하는 식이죠.
이에 외부 지식을 언어 모델에 내재화하거나, 따로 저장한 외부 지식을 학습에 활용하는 메커니즘에 대한 필요성이 커지게 됐습니다. 2019년부터는 외부에 구축해 둔 지식 베이스를 활용한 연구가 본격적으로 제안됐습니다. 특히 지식 그래프Knowledge graph5에서 대화 맥락에 어울리는 개체entity와 관계relation를 찾는 경로 탐색에 관한 연구가 활발하게 이뤄지고 있습니다. ‘(스티븐 스필버그)→감독하다→(A.I)→장르→(SF)’와 같은 경로를 만들어낼 수 있다면, 글 도입부 예시와 같은 적절한 응답 문장을 수월하게 생성하리라는 판단에 근거한 접근입니다.
페이스북(Facebook)은 ‘OpenDialKG{%rf%}6’ 논문에서 RNN 디코더decoder를 제안했습니다. \(n\)단계에서의 출력값을 이용해 \(n+1\)단계에서의 상태를 예측하는 재귀적 구조를 이용해, 탐색 각 단계에서 가장 최고의 답을 만드는 하나의 노드를 선택하는 탐욕적 탐색Greedy Search을 진행합니다. 바이두(Baidu)는 강화학습reinforcement learning7 기반 에이전트로 탐욕적 경로 탐색을 구현했습니다{%rf%}.
기존 접근 방식의 한계점
하지만 이런 기존의 접근 방식에는 다음과 같은 한계가 존재합니다.
우선, 인코더가 지식 그래프의 구조 정보를 반영하지 못합니다. 오픈도메인 대화 시스템에 사용되는 지식 그래프 규모만 해도 노드 11만 개, 관계 100만 개 이상일 정도로 그 규모가 상당합니다. 따라서 실제 대화에서 사용되는 극소수의 지식을 매우 효과적으로 찾기 위해서는 노드와 이웃 노드 간의 관계를 함축적으로 표현하는 인코딩 기법이 필요합니다. 하지만 기존의 그래프 임베딩graph embedding8은 각 노드의 주변 정보를 효과적으로 반영하는 데 한계가 있습니다.
두 번째, 탐색 방식의 한계입니다. “누가 영화 A.I.를 감독했어?”라는 질문에 대한 답이 “스티븐 스필버그” 하나인 예시처럼, 정답이 정해진 닫힌 질문에서는 기존의 탐욕적 탐색 방식만으로도 적합합니다. 이 때문에 “스티븐 스필버그가 누구야?”라는 질문처럼 “미국인” 또는 “영화감독”, “케이드 캡쇼의 남편”과 같은 여러 답변이 존재하는 열린 질문에는 적합하지 않습니다. 매 탐색의 순간 가장 높은 확률값이 할당된 간선과 연결된 노드를 선택하는 방식으로 단일 경로를 생성하기 때문입니다.
세 번째, <대화 말뭉치, 지식 경로>로 구성된 대규모 병렬 코퍼스 구축에 큰 비용과 많은 시간이 필요합니다. 앞에서 계속 예시로 언급한 스티븐 스필버그와 그가 연출한 작품을 두고 대화를 나누는 모델을 만들기 위해서는 라벨링된 학습 데이터로 감독학습supervised learning을 진행해야 합니다. 이미 구축된 지식 그래프를 토대로 사람이 직접 학습에 이용할 대화 말뭉치와 지식 경로를 하나하나 만들어야 한다는 의미죠.
AI Lab이 제안한 AttnIO의 동작 방식
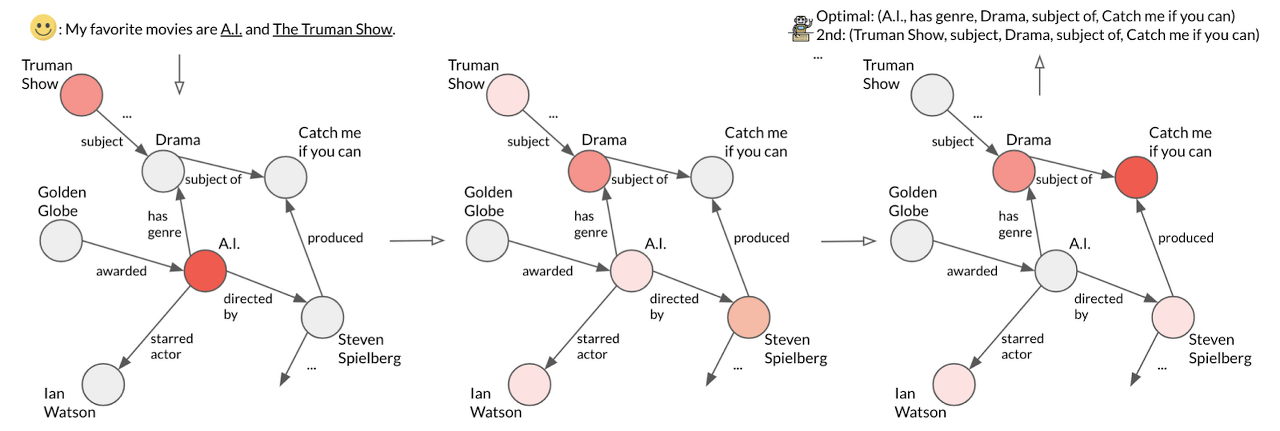
AI Lab은 1)인코딩 과정에서 지식 그래프의 구조 정보를 반영하고, 2)대화 맥락에 따라 경로를 생성하며, 3)정답 경로의 첫 번째 노드와 마지막 노드만을 이용한 약감독학습weakly-supervised learning으로도 감독학습에 버금가는 성능을 달성한 새로운 지식 경로 탐색 모델인 AttnIO를 제안했습니다. in-flowincoming attention flow에서 각 노드는 자신과 연결된 이웃 노드와 그 관계를 표현하는 벡터를 생성하며, out-flowoutgoing attention flow에서는 대화 맥락에 따른 최적의 경로를 탐색합니다. 자세한 설명은 각 단락에서 이어서 하겠습니다.
[ 그림 2 ] AttnIO의 아키텍처
dialog encoder
대화의 맥락과 질문의 의도를 효과적으로 반영한 컨텍스트 벡터(context vector)를 생성하는 모듈로, 사전학습을 마친 ALBERTA Lite BERT[4]9의 인코더로 구현됐습니다. AI Lab은 문장을 구성하는 모든 토큰의 응축된 의미를 가진 CLSSpecial Classification token에 해당하는 벡터를 컨텍스트 벡터로 활용했습니다.
in-flow
in-flow는 그래프 신경망Graph Neural Networks10을 이용합니다. 우선, 각 노드와 간선에 해당하는 데이터를 벡터로 변환합니다. 그런 뒤, 특정 노드는 진입 간선incoming edge으로 연결된 이웃 노드와 이 간선을 합쳐 새로운 값으로 업데이트됩니다11. 이 업데이트 과정을 반복하면 특정 노드는 그래프 구조상의 주변 정보도 표현할 수 있게 됩니다.
A에서 나가는 간선이 2개인 ‘\(C\)(학생)←이다←\(A\)(해리포터)→사랑한다→\(B\)(지니 위즐리)’를 예로 들어보겠습니다. 시작 노드가 \(A\)라고 한다면, \(C\) 노드는 “해리포터는 학생이다”, \(B\) 노드는 “해리포터는 지니 위즐리를 사랑한다”라는 정보를 표현하는 벡터를 갖게 되는 겁니다.
Entity-Context Fusion이라는 모듈에서 in-flow의 출력인 각 노드 벡터와 dialog encoder의 출력인 컨텍스트 벡터를 합치면, 각 노드 벡터는 대화의 맥락과 질문의 의도까지 표현할 수 있게 됩니다. 예를 들어, 스티븐 스필버그와 관련된 여러 지식 중 그가 감독한 영화 관련 지식을 노드 벡터에 더 많이 반영하게 되는 거죠.
out-flow
대화에 따라서는 “해리포터는 지니 위즐리를 사랑한다”는 지식이 필요할 수도 있고, “해리포터는 학생이다”는 지식이 필요할 수도 있습니다. 이처럼 현재의 대화 맥락에 따라 경로의 중요도를 계산하는 게 out-flow의 역할입니다.
out-flow는 어텐션attention을 전파하는 방식으로 경로를 탐색합니다. 어텐션은 특정 시퀀스를 디코딩할 때 관련된 인코딩 결과를 참조하게 만드는 기법을 일컫습니다. 여기서는 특정 노드에 연결된 진출 간선outgoing edge 중 대화 맥락에 더 어울리는 쪽에 더 높은 어텐션 값을 전파하는 걸 의미합니다. 우선, 대화의 첫 발화 문장과 관련된 노드의 어텐션을 초기화initial attention computation하고 나서, 연속해서 어텐션을 전파합니다. 어텐션 전파를 완료한 이후에는 각 탐색 단계에서 어텐션이 가장 많이 전파된 노드와 간선을 선택해 최종 경로를 생성합니다.
위의 예시를 다시 예로 들어보겠습니다. 대화 맥락에 따라 ‘\(A\)→사랑한다→\(B\)‘라는 지식이 필요하면, out-flow는 \(A\)의 어텐션 값 대부분을 ‘사랑한다’는 간선을 통해 B로 보냅니다. 반대로 ‘\(A\)→이다→학생’이 필요한 대화에서는 ‘이다’라는 간선을 통해 \(C\)쪽 방향 쪽 위주로 어텐션 값을 보냅니다.
모델 성능 평가 기준
AI Lab은 지난 2019년 페이스북이 ‘유익한 응답 생성을 위한 지식 그래프 탐색’ 평가를 목적으로 만들어서 배포한 OpenDialKG[4]라는 벤치마크를 활용했습니다. 여기에는 약 10만 개의 대화12와 지식 경로로 구성된 병렬 코퍼스, 100만 개 이상의 간선으로 구성된 지식 그래프가 포함돼 있습니다.
| 질문 | 스티븐 스필버그가 누구야? |
| 정답 경로 | [스티븐 스필버그, 직업, 영화감독] |
| AttnIO가 생성한 후보 경로 | [스티븐 스필버그, 국적, 미국] (1등) [스티븐 스필버그, 직업, 영화감독] (2등) [스티븐 스필버그, 감독하다, 영화] (3등) |
[ 표 1 ] path@k와 tgt@k 설명을 위한 예시
[ 표 1 ]의 질문이 포함된 대화 말뭉치를 AttnIO에 입력하면, 전파된 어텐션 값에 따라 여러 지식 경로 후보군이 생성됩니다. \(path@k\)는 정답과 일치하는 경로를 기준으로, \(tgt@k\)는 정답 경로의 마지막 노드만을 기준으로 K등수 안에 포함되는지 여부를 기준으로 점수를 산정합니다. 등수 안에 들면 100점을, 포함되지 않으면 0점을 부과해 모든 데이터셋에 대한 평균 점수를 산술합니다. AttnIO가 생성한 1위 후보군이 정답 경로와 일치하는 상황이 가장 이상적입니다. 그래서 \(path@1\) 또는 \(tgt@1\)는 다른 태스크 평가에서 쓰이는 정확도와 동일한 지표라고 보면 됩니다.
실험 결과
지식 경로를 라벨링한 데이터를 감독학습한 여러 모델의 성능을 비교한 결과, AttnIO-AS는 OpenDialKG에서 현재 최고 수준의(SOTA) 추론 성능을 달성했습니다. 특히 k가 작을수록 그 성능 격차가 더 크다는 부분은 눈여겨서 볼만 합니다. AttnIO가 생성한 1위 후보 경로와 경로상 마지막 노드가 정답과 일치할 확률이 다른 모델보다 높다는 점을 시사하기 때문입니다. 이는 탐색 각 단계에서 노드를 미리 선택하는 RNN 디코더를 갖춘 모델과는 달리, 대화 맥락에 따라 가장 많은 어텐션 값을 전파받은 경로를 선택하는 구조에 기인한 효과로 분석됩니다. 주변 노드와의 관계를 잘 표현하는 노드 인코딩 기법도 유효한 영향을 미쳤습니다.
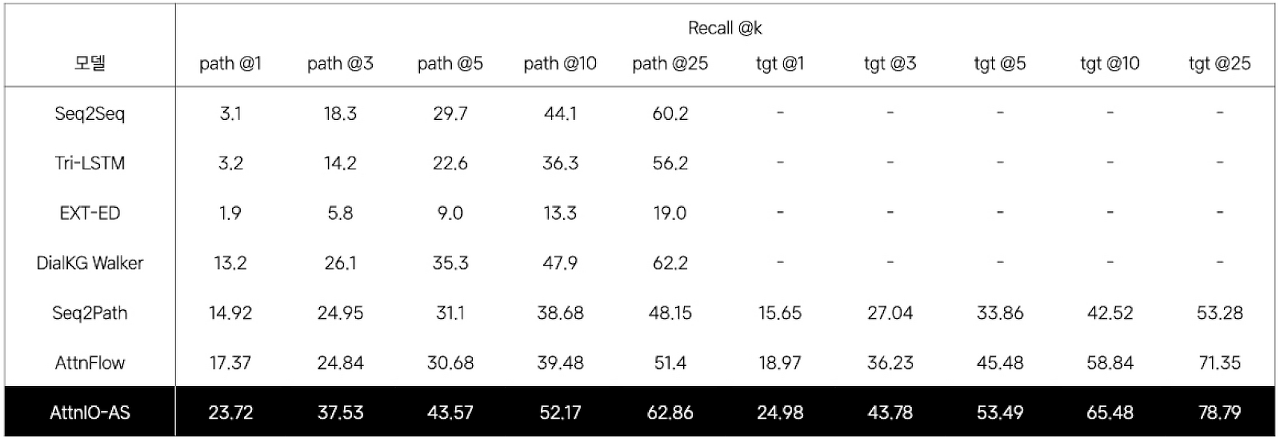
[ 표 2 ] 대화 말뭉치에 지식 경로를 라벨링한 데이터를 학습한 모델의 성능 비교
정답 경로의 첫 번째 노드와 마지막 노드만을 이용한 약감독학습 버전인 AttnIO-TS도 기존 모델과 비견할 만한 수준의 성능을 보였습니다.
다만 \(path@k\)에서는 감독학습한 모델과 약감독학습한 모델 간 점수 차가 더 크게 벌어졌습니다. 이는 경로에 포함된 모든 노드와 관계를 다 맞춰야만 정답으로 처리하는 평가 방식의 한계입니다. 예를 들어, 사용자가 “스티븐 스필버그가 어떤 영화를 감독했어?”라고 물으면, [스티븐 스필버그, 감독하다, (모든 스필버그 영화)]가 정답이어야 합니다. 하지만 \(path@k\)는 정답 경로에서 언급되지 않은 다른 영화 제목은 모두 오답으로 처리하죠.
이를 보완하고자 [감독하다]와 같은 관계 정보만을 제대로 포함하는지를 평가relation path accuracy하는 실험([표 3])을 진행했습니다. 그 결과, 정답 경로를 배우지 않은 AttnIO-TS가 노드 간의 관계 정보를 배운 AttnIO-AS에 상응하는 수준의 성능을 선보였습니다. 모델이 생성한 경로의 적합성을 사람이 직접 평가하는 실험([표 4])에서는 AttnIO-TS가 좀 더 나은 점수를 받기도 했습니다. 이는 대화 맥락에 따라 어텐션을 전달하는 과정에서 경로를 스스로 탐색한 거로 보입니다.
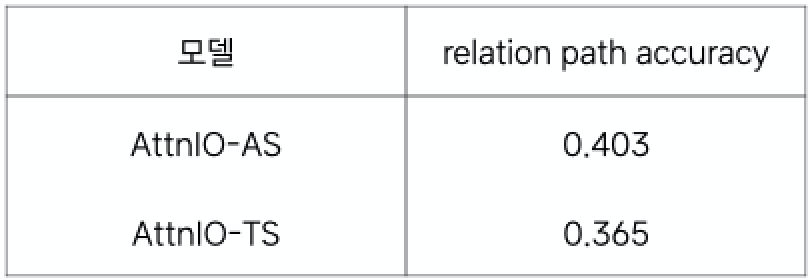
[ 표 3 ] AttnIO-AS와 AttnIO-TS의 관계 경로 일치성 여부를 (자동) 평가한 결과
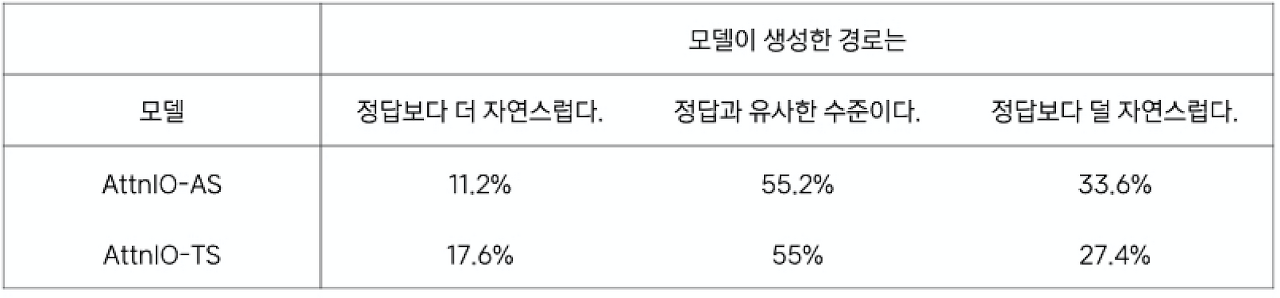
[ 표 4 ] AttnIO-AS와 AttnIO-TS가 생성한 경로의 적합성에 대한 인간 평가 결과
아울러 AI Lab은 AttnIO가 해석력interpretability도 갖추고 있음을 확인했습니다([그림 3]). 각 추론 단계에서 특정 노드가 어떤 간선을 통해 얼마나 많은 어텐션을 받았는지를 볼 수 있다는 의미입니다. “AttnIO가 열린 질문과 닫힌 질문 사이의 차이를 경로 탐색 과정에서 반영하는가?”를 분석한 결과, “스티븐 스필버그가 누구야?” 식의 열린 질문에는 여러 후보 노드에 어텐션 값을 골고루 전파했습니다. 반면, “누가 영화 A.I.를 감독했어?” 식의 닫힌 질문에는 정답이 될 수 있는 한, 두 가지의 개체에만 어텐션이 전파됐음을 확인할 수 있었습니다.

[ 그림 3 ] AttnIO가 추론한 어텐션 값 분포를 분석하면 AttnIO가 대화 맥락에 따라 탐색한 지식 경로를 살펴볼 수 있다.
향후 계획
이번 글에서는 기존 대화 모델에서 발견된 한계를 극복하고자 지식 그래프를 활용하는 방법을 소개했습니다. 대화 시스템뿐만 아니라, 텍스트 생성과 관련된 거의 모든 태스크에서는 사실이 아닌 문장이나 지나치게 단순한 문장이 생성되는 현상이 꾸준히 보고되고 있습니다. AI Lab은 AttnIO의 방법론을 활용해 더 다양한 NLP 태스크에서 외부 지식을 효과적으로 이용하는 방안을 탐색하는 한편, 텍스트에서 지식을 추출하는 모델과 언어 모델의 합동훈련joint-training을 위한 일반화된 프레임워크를 연구할 계획입니다.
정재훈 연구원은 “외부 지식 베이스를 이용하는 언어 모델은 관계 레이블(감독하다, 사랑한다, 국적 등)을 이해만 하고 이를 생성하지 못한다”며 “특정 지식 베이스의 스키마schema에 종속되지 않고 사람처럼 개념과 개념 간의 관계를 자유롭게 구조화하는 지식 추출 모델에 관한 새로운 접근 방식을 탐색하겠다”고 말했습니다.
참고 문헌
[1] AttnIO : Knowledge Graph Exploration with In-and-Out Attention Flow for Knowledge-Grounded Dialogue (2020) by Jaehun Jung, Bokyung Son, Sungwon Lyu in EMNLP
[2] Language Models as Knowledge Bases? (2019) by Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H. Miller, Sebastian Riedel in EMNLP
[3] A Diversity-Promoting Objective Function for Neural Conversation Models (2016) by Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, Bill Dolan in NAACL
[4] OpenDialKG: Explainable Conversational Reasoning with Attention-based Walks over Knowledge Graphs (2019) by Seungwhan Moon, Pararth Shah, Anuj Kumar, Rajen Subba in ACL
[5] Knowledge Aware Conversation Generation with Explainable Reasoning over Augmented Graphs (2019) by Zhibin Liu, Zheng-Yu Niu, Hua Wu, Haifeng Wang in EMNLP
[6] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (2019) by Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut in arXiv
각주
-
지식을 구조화해서 표현해 놓은 자료 ↩
-
ACL(Association for Computational Linguistics), NAACL(NORTH American Chapter of the ACL)와 함께 전산언어학 분야에서는 인지도가 높은 학회 ↩
-
단어 시퀀스를 입력받아 임베딩 벡터를 생성하는 인코더와 이 벡터를 이용해 또 다른 단어 시퀀스를 생성하는 디코더를 갖춘 아키텍처 ↩
-
확률변수 X가 주어졌을 때 또다른 확률변수 Y가 나올 확률 ↩
-
그래프는 데이터를 노드를, 노드와 노드를 잇는 간선edge을 이용해 데이터 간 관계 정보를 나타낸다. 지식 그래프는 바로 이 그래프를 이용해 표현한 지식을 가리킨다. ↩
-
자연어처리 분야 최고 학회 중 하나인 ACL에서 연구의 시의성을 인정받아 Honorable Mention 상을 받기도 했다. ↩
-
환경과 에이전트가 상호작용하면서 시도와 실패를 통해 보상을 학습한다. 매 단계에서 에이전트가 행동 α를 수행하면 환경은 보상 r과 다음 상태 s를 반환한다. 에이전트는 한 에피소드episode에서 최대 보상을 얻을 수 있는 행동 또는 행동 순서를 선택한다. ↩
-
이웃 노드와의 관계를 고려해 그래프의 노드를 벡터로 변환하는 기법 ↩
-
토큰 시퀀스가 입력되면 ALBERT는 맥락을 반영한 토큰별 임베딩 벡터를 출력한다. AI Lab은 파이썬 NLP 라이브러리를 전문적으로 만드는 기술 스타트업 허깅페이스(HuggingFace)에서 제공한 버전을 활용했다. ↩
-
임의의 구조의 그래프 G가 들어왔을 때 이를 하나의 특징 벡터로 표현하는 모델 ↩
-
이웃 노드와 간선을 합치는 과정에서 각 노드에 부여된 어텐션 값과 노드 벡터를 곱한다. 이처럼 어텐션 값이 직접 전파되지는 않지만 어텐션을 곱한 주변 노드 벡터가 전파된다는 점에서 incoming-attention-flow라는 이름이 붙여졌다. ↩
-
대화 지문에는 오픈 도메인에서의 일상 대화 뿐 아니라 영화를 추천하는 목적 지향적 대화task-oriented dialog도 포함돼 있다. ↩
만든이

|

|

|

|

|

|