NLP
EMNLP 2020 - 다국어 번역 논문 2편을 소개합니다

2020-12-17
카카오엔터프라이즈 AI Lab(이하 AI Lab)이 낸 3편의 논문이 EMNLPEmpirical Methods in Natural Language Processing에 게재 승인됐습니다. 자연어처리에서 경험적 방법론을 다루는 이 학회는 ACLAssociation for Computational Linguistics, NAACLNORTH American Chapter of the ACL과 함께 전산언어학 분야에서는 인지도가 높습니다. 올해에는 총 3,677편의 논문 중 754편이 통과됐습니다.
이번 글에서는 EMNLP에 게재된 자사 논문 중, 신경망 기반 다국어 기계 번역 모델(MNNTMultilingual Neural machine Translation)에 관한 최신 기법을 다룬 2편의 논문[1][2]을 상세히 다뤄보고자 합니다. 두 논문을 저술한 AI Lab AI기술실 컨택스트팀 소속의 류성원 연구원과 손보경 연구원을 만나봤습니다.
※보다 명확하고 간결한 방식으로 대상을 지칭하기 위해 본문에서는 다국어 번역을 수행하는 모델을 MNMT로, 두 언어 간의 번역을 수행하는 모델을 NMT라고 명명했습니다.
∙ ∙ ∙ ∙ ∙ ∙ ∙
다국어 번역을 위한 모델 아키텍처
두 논문에서 공통적으로 언급하는 다국어 번역 아키텍처에 대한 배경부터 짚어보겠습니다.
인코더encoder와 디코더decoder 기반 seq2seqsequence to sequence1 아키텍처의 NMT는 기계 번역에 큰 혁신을 안겼습니다. 서로 다른 두 언어의 문장으로 구성된 대량의 병렬 코퍼스parallel corpus로부터 단어 의미와 단어 순서, 문장 구조, 단어 간의 의존 관계 등번역에 필요한 모든 정보(문장 벡터)[3]를 스스로 학습하기 때문입니다. 이로써 인간이 기계에 세세한 번역 규칙을 하나씩 가르칠 필요가 없게 됐습니다.
기존에는 다국어 번역(\(N\)개 언어)을 위해 \(N×(N-1)\)개의 NMT를 각기 따로 두었습니다(Single NMT, [그림 1-(1)]). 영어, 한국어, 스페인어를 번역해야 한다면 [영→한, 한→영, 한→스, 스→한, 영→스, 스→한] 이렇게 총 여섯 개의 NMT를 만드는 식이죠. 다만 문제는 언어 수가 늘어나는 만큼 훈련해야 할 모델 수, 좀 더 자세히 말하면 매개변수parameter 수가 제곱으로 커진다(\(O\)(\(N^{2}\)))는 겁니다.
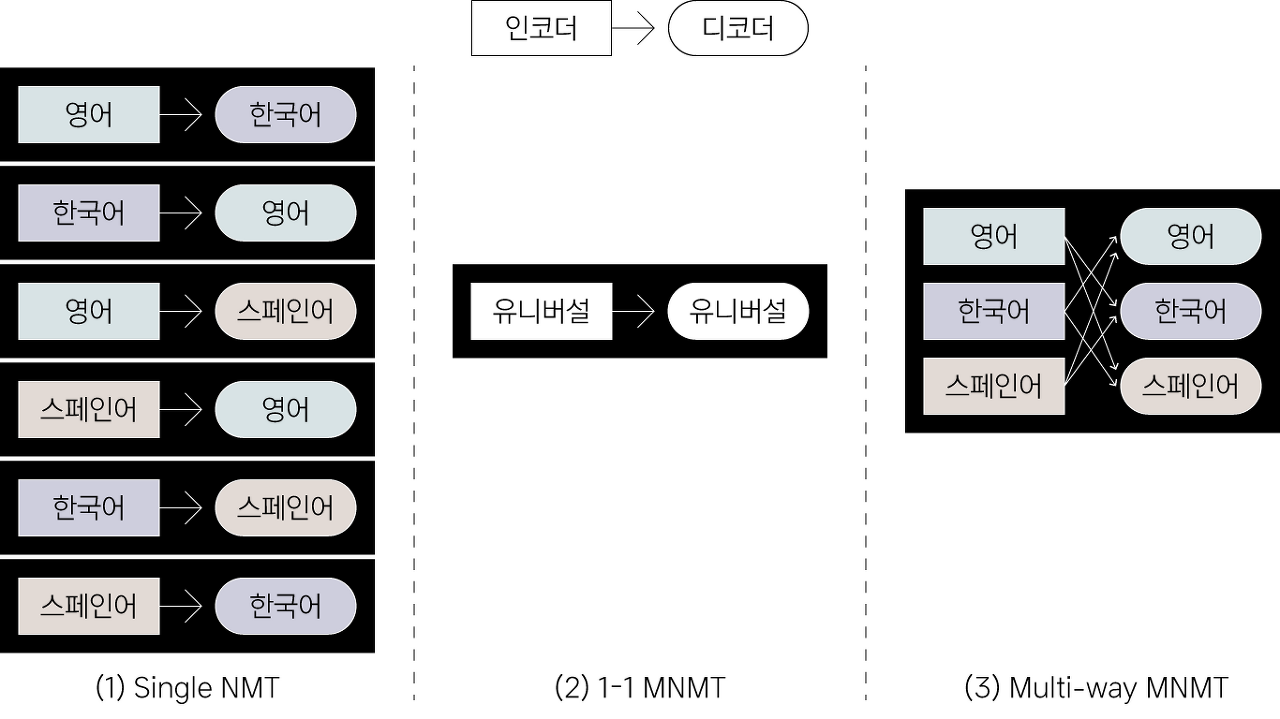
[ 그림 1 ] 3개국 언어 간 번역 태스크를 해결하는 3가지 방식
이에 매개변수 수를 획기적으로 줄인 multi-way MNMT[4]가 새로 제안됐습니다([그림 1-(3)]). 여러 NMT를 각기 따로 두는 대신, 언어별 인코더와 디코더를 두고 여러 방향에서 이를 공유하는 구조2를 마련했습니다. N×(N-1)개의 모델, 다시 말해 N×(N-1)개의 인코더-디코더를 훈련해야 하는 Single NMT와 비교해, multi-way MNMT는 2N개의 인코더-디코더만 훈련하기만 하면 됩니다. 관련된 언어의 인코더와 디코더만 활용할 수 있어 추론 시간과 비용도 효과적으로 낮출 수 있습니다. 또한, 새로운 언어를 추가하고 싶다면 해당하는 인코더와 디코더 쌍만 따로 추가 훈련시키면 됩니다.
하지만 오늘날에는 전체 매개변수 수 대비 더 나은 성능을 내는 1-1 MNMT[5]에 대한 연구가 주류로 자리하고 있습니다([그림 1-(2)]). 이 모델 아키텍처의 이름은 하나의 인코더(1)와 하나의 디코더(1)로만 구성됐다는 부분을 표현하고 있죠. 이처럼 매우 간단한 방법으로 다국어 번역 문제를 해결한 1-1 MNMT는 데이터가 상대적으로 적은 방향의 태스크low-resource environment에서도 일정 수준 이상의 성능을 냅니다. 또한, 학습 데이터가 하나도 주어지지 않은 태스크인 제로샷zero-shot 번역을 최초로 선보였습니다.
Revisiting modularized multilingual NMT to meet industrial demands (류성원, 손보경, 양기창, 배재경)[1]
1-1 MNMT가 지닌 한계
하지만 기업 환경에서는 1-1 MNMT를 사용하기가 어려운 현실적인 문제가 산재합니다[6].
우선, 훈련해야 할 번역 방향이 늘어날수록 성능은 되려 저하되는 병목 현상capacity bottleneck이 발생합니다. 이 문제는 1-1 모델 크기가 충분히 크지 않아서, 요구되는 성능 대비 수용 능력(모델 크기)이 충분히 크지 않아서 발생합니다. 그렇다고 모델 크기를 무한정 키울 수도 없습니다. 매개변수 수가 기하급수적으로 늘어난 만큼 계산 복잡성이 커져서 최적화3가 매우 어려워지기 때문입니다.
대규모 1-1 MNMT로 모든 방향의 (성능 저하가 없는) 번역이 가능해지더라도, 실용화는 여전히 먼 나라의 일입니다. 기업 환경에서는 사용자가 요청한 하나의 질의query를 처리하는 데 드는 계산량이 비용과 직결되는 만큼 추론에 사용하는 매개변수 수를 중시합니다. 그런데 딥러닝 특성상 특정 방향의 번역 태스크에 일부 매개변수만을 선택적으로 사용할 수 없다 보니 추론 비용이 굉장히 커지게 됩니다. 마찬가지 이유로 새로운 언어를 추가하거나 또는 기존 언어를 제거하기 위해 모델 전체를 재훈련하는 비용도 상당히 높죠.
이에 많은 기업에서는 비용이 상당히 저렴한 pivot NMT 방식을 좀 더 선호합니다([그림 2]). ‘회전축의 중심’이라는 본래 의미에서 착안, 다국어 번역에서 피벗pivot은 전세계적으로 가장 많이 쓰이는 언어인 영어를 매개로 하는 중간 번역을 의미합니다. 비영어→영어 NMT, 영어→비영어 NMT을 각각 N개만 훈련하면 되어서 비용을 많이 낮출 수 있습니다.

[ 그림 2 ] 한국어→중국어 번역을 위한 pivot NMT 구조
하지만 두 단계에 걸쳐 번역이 이뤄지는 구조 상 추론에 더 많은 시간이 걸립니다. 피벗에 사용되는 두 NMT의 구조가 동일하다고 가정했을 때, 전체 추론 시간은 한 방향 번역에 걸리는 시간의 2배가 되는 셈이죠. 두 NMT 중 하나라도 성능이 낮으면 전체 번역 성능도 낮아지는 점 역시 구조에 기인합니다.
이에 AI Lab은 1-1 MNMT와 pivot NMT, Single NMT의 단점을 극복한 실용적인 번역 모델을 새롭게 탐색하는 과정에서 multi-way MNMT가 지닌 가치를 재발견하는 연구를 진행하게 됐습니다. 그럼 이전에 제안된 서로 다른 아키텍처를 갖춘 번역 모델의 성능을 직접적으로 비교하는 실험 결과에 대해 상세히 설명해보겠습니다.
모델 구현
본래 multi-way MNMT는 인코더와 디코더를 LSTM으로 구현했습니다. 하지만 LSTM과 같은 RNN 계열의 아키텍처에서는 문장이 길수록 계산 속도가 느려지고 거리가 먼 단어 간 관계를 제대로 표현하지 못하는 문제가 발생합니다. 이런 한계를 극복하고자 나온 최신 아키텍처가 바로 Transformer입니다. Transformer는 컨볼루션convolution이나 순환recurrence 기법을 사용하지 않고 어텐션attention4만으로도 거리가 먼 단어 간의 관계를 효과적으로 표현해 높은 추론 성능을 달성했습니다. AI Lab은 이런 특장점을 갖춘 Transformer로 구현해 훈련한 버전을 M2NMT[1]라 명명했습니다.
실험 결과
AI Lab은 다국어 번역 태스크를 위한 세 방법론(Single NMT, 1-1 MNMT, M2MNT)의 감독학습supervised learning5 성능을 비교하는 실험을 진행했습니다. 그 결과([그림 3]), 1-1 MNMT는 성능 병목 현상으로 인해 Single NMT보다 더 낮은 성능을 냈습니다. 반면, M2NMT는 셋 중 가장 높은 성능을 선보였습니다. 한 매개변수가 여러 방향의 번역에 공유되는 구조로 인해 다국어 학습 시너지 효과data-diversification, and regularization effect가 난 거로 분석됩니다. 한편, 앞서 설명한대로 1-1 MNMT의 크기를 키우면 성능 병목 현상이 크게 개선된다는 점도 확인할 수 있습니다([그림 4]).
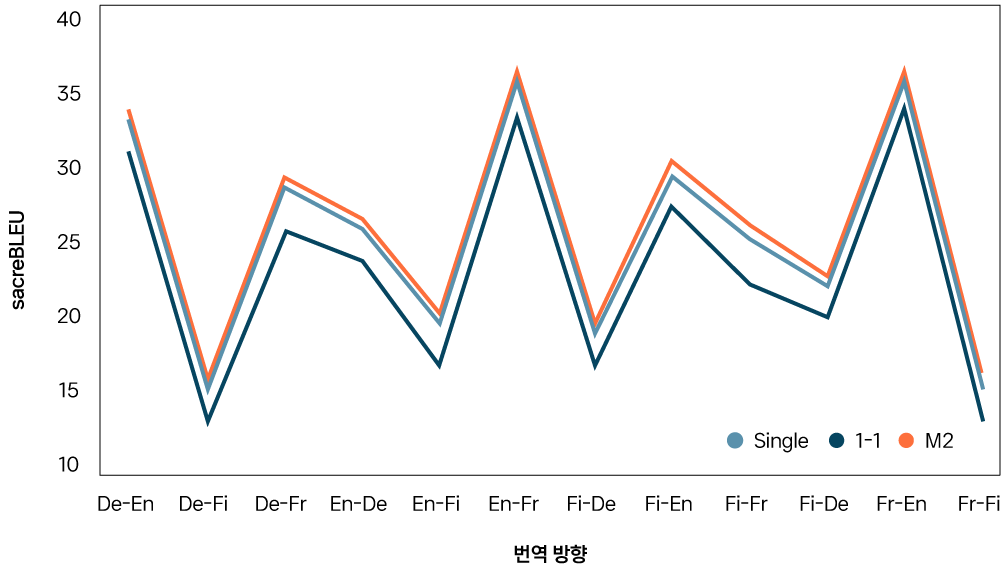
[ 그림 3 ] 12방향의 번역 태스크에서 Single NMT, 1-1 MNMT, M2NMT의 성능
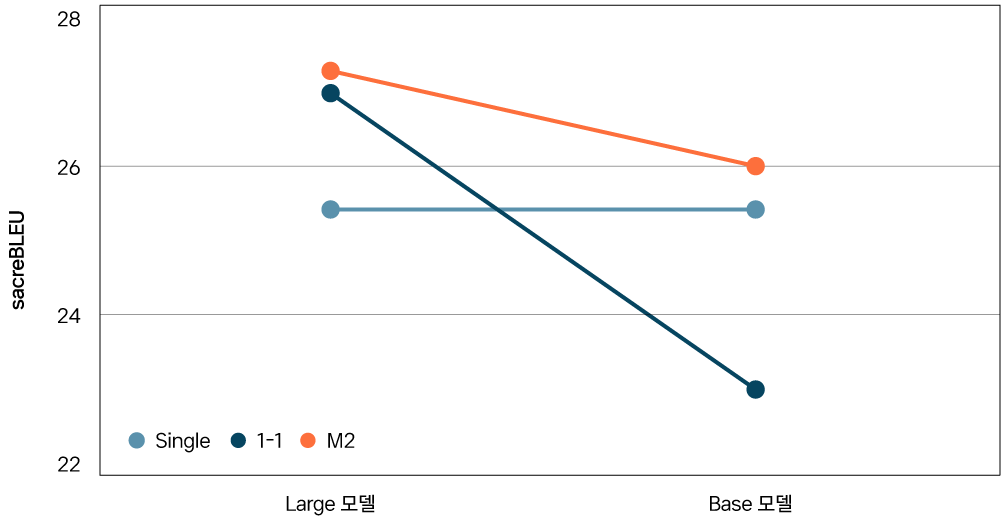
[ 그림 4 ] 모델 크기가 상대적으로 더 클수록 성능 병목 현상이 완화됨을 확인할 수 있다.
두번째 실험에서 AI Lab은 4개의 언어 간 번역(En, De, Es, Ni 기준) 태스크를 익힌 M2(4)에, 아직 학습하지 않은 새로운 언어(Fr)를 담당하는 인코더와 디코더 쌍을 점진적으로 훈련해나갈 때의 제로샷 성능을 비교했습니다6. 그 결과[ 표 1-(2) ], M2(4)는 제로샷 태스크에서 Single(5)보다 더 좋은 성능을 보였습니다. 아울러, M2(4)가 더 많은 *↔︎Fr 방향의 태스크를 배울수록(ID 1→2→3→4), M2(4)의 En↔︎Fr 간 번역 성능이 조금씩 늘어나며, 모든 번역 태스크를 추가 학습한 M2(4)의 성능이 M2(5)에 버금간다는 점을 볼 수 있습니다. pivot(4)와 비교해서도, M2NMT가 거의 모든 제로샷 태스크에서 pivot NMT 대비 더 좋은 성능(빨간색 글씨)을 달성했음을 ([표 1-(1)])에서 확인했습니다.
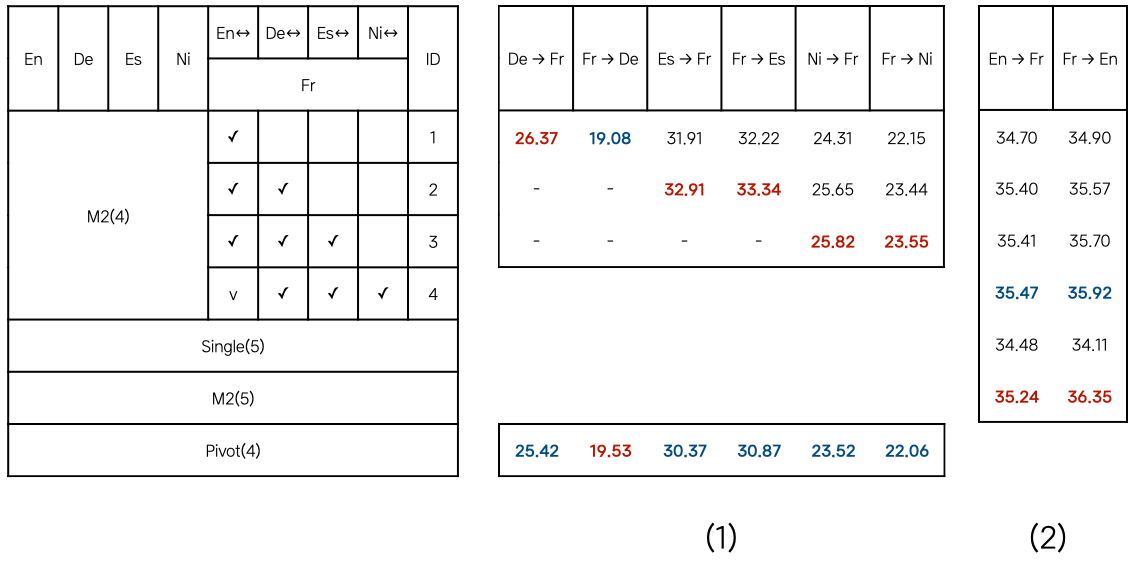
[ 표 1 ] (1) 제로샷에서 pivot NMT와 M2NMT 성능 비교 (2) 새로운 언어(Fr)에 대한 번역 태스크를 추가한 모델의 성능 비교
AI Lab은 M2NMT가 생성한 문장 벡터가 언어에 독립적인 공간interlingual space에 사상된다고 가정했습니다. 그 구조상 각 인코더는 모든 디코더가 해석할 수 있는 정보를 제공해야 하며, 각 디코더는 모든 인코더가 제공한 정보를 해석할 수 있어야 하기 때문입니다. 학습을 마친 모델에 새로 추가된 인코더와 디코더가 약간의 훈련을 거치기만 해도 각각 언어에 독립적인 표현력과 해석력을 갖췄음을 보여준 두번째 실험은 이 가정을 실험적으로 증명했습니다.
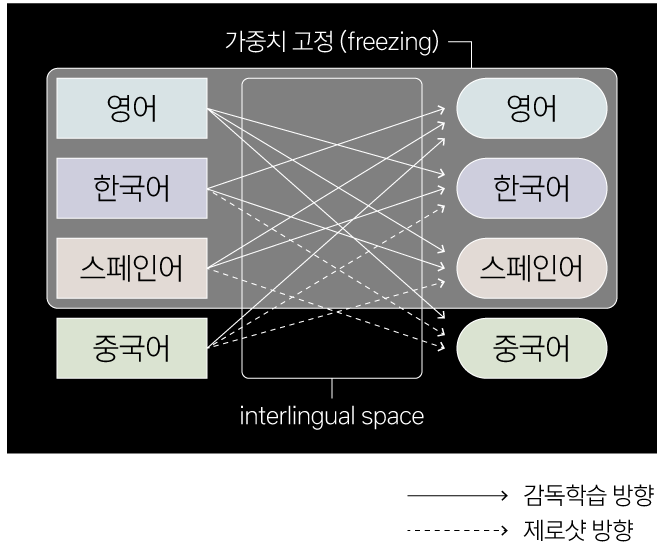
[ 그림 5 ] M2MNT에서 생성되는 언어에 독립적인 특징 공간
Sparse and Decorrelated Representations for Stable Zero-shot NMT(손보경, 류성원)[2]
1-1 MNMT의 제로샷 성능이 낮은 이유
MNMT 성능 향상의 핵심 전략이 두 언어의 문장으로 구성된 대량의 병렬 말뭉치 확보에 있다고 해도 과언이 아닙니다. 하지만 한 언어쌍에 대해, 유명한 벤치마크 중 비교적 작은 규모인 160,000개7 수준의 병렬 말뭉치를 구축하는 일조차 하늘에 별따기만큼 쉽지가 않습니다. 이런 이유로 제로샷에서도 충분한 성능을 내는 모델 아키텍처에 관한 연구가 이전보다 더 활발하게 이뤄지고 있습니다.
서론에서는 다국어 학습으로 인한 시너지 효과를 충분히 기대할 수 있으며, 모델 규모 대비 기대 이상의 성능을 내는 1-1 MNMT를 주로 활용한다는 점을 밝힌 바 있습니다. 1-1 MNMT는 어떤 언어로 번역할지를 안내하는 메타 토큰(token)을 입력해 원하는 언어의 문장을 생성합니다.
하지만 1-1 MNMT를 이용한 제로샷 번역에서는 비영어 문장을 입력하면 토큰 종류와 관계없이 항상 영어 문장을 생성하려는 경향이 커지는 문제가 생깁니다. 이처럼 특정 결과만을 도출하려는 현상을 학계에서는 ‘얽힘entanglement’이라고 표현합니다. 전세계적으로 가장 많이 쓰이는 언어인 영어로 작성된 문장이 반드시 포함된 병렬 말뭉치English-centric data가 원인으로 보이지만, 이는 아직 수학적으로 증명된 바 없습니다.
배치 크기batch size, 드롭아웃dropout, 가중치 초기화weight Initialization와 같은 초매개변수hyperparameter 조정은 얽힘 문제 해결에 도움이 되지 않았습니다. 제로샷 번역의 성능은 초매개변수 값에 매우 민감하게 반응하기 때문입니다. 그렇다고 이 값을 고정해버리면 감독학습에서의 번역 성능이 되려 낮아질 위험도 높아집니다.
1-1 MNMT의 구조적 한계를 극복하려는 시도
이에 빔 탐색beam search으로 다음에 올 단어를 예측할 때, 목표로 하는 언어에 해당하는 어휘만 남겨두고 나머지는 걸러내[7] 얽힘 문제를 해결하려는 시도가 있었습니다. 빔의 모든 탐색 단계에서 의도하는 언어의 단어를 선택해야 그 다음에도 목표로 하는 언어의 단어가 생성된다는 아이디어로부터 착안됐습니다.
또다른 시도는 역번역back translation[8]8을 이용한 데이터 어그먼테이션augmentation9입니다. 시중에서 쉽게 구할 수 있는 비영어 단일 말뭉치를 모델에 입력해 생성한 (비영어, 비영어’) 병렬 말뭉치로 데이터 균형을 맞춰서 모델을 재훈련한다면, 영어 문장을 내뱉는 경향을 줄일 수 있다고 본 거죠. 다만, 모든 언어쌍에 대해 합성 데이터셋을 생성하는 데 드는 계산량이 큰 만큼 높은 비용이 발생합니다.
최근에는 동일한 의미를 가진 영어 문장 벡터와 비영어 문장 벡터가 언어에 독립적인 벡터를 생성할 수 있도록 인코더를 정규화하는 기법regularization10을 다룬 연구가 제안됐습니다. 이는 동일한 의미를 나타내는 비영어 문장과 영어 문장을 표현하는 두 벡터를 서로 구분할 수 없을 정도로 유사하다면, 디코더가 비영어 문장을 영어로 번역하려는 판단을 쉽게 내리지 못하리라는 가정을 전제로 합니다.
AI Lab의 제안, ‘SLNI를 이용한 인코더 정규화’
지속 학습continual learning11에서는 새로운 태스크를 가르칠 때 기존 태스크에서 배운 지식을 잊어버리는 ‘파괴적 망각catastrophic forgetting‘이라는 현상이 발생합니다. 기존 태스크에 이용된 뉴런이 활성화되며, 관련된 매개변수 값이 재조정되기 때문입니다.
SLNI[9]Sparse coding through Local Neural Inhibition은 이같은 문제를 해결하기 위한 정규화 기법입니다. 연구진은 활성 상태에 있는 뉴런이 인접한 다른 뉴런의 활성화를 억제하는 ‘측면 억제lateral inhibition’에서 아이디어를 얻었습니다. 기존 태스크에서 활성화된 중요한 뉴런값을 바꾸는 대신, 활성화되지 않은 뉴런을 새로운 태스크에 사용한다면 망각을 줄일 수 있다고 본거죠.
SLNI는 서로 무관하면서도 희소한 특징을 갖춘 벡터sparse and decorrelated representation를 만들면 측면 억제 효과를 얻을 수 있다고 설명합니다. 이에 SLNI는 국소적으로 인접한 두 차원의 값에 점진적으로 가우시안gaussian12 패널티를 줍니다.
AI Lab은 이 SLNI가 파괴적 망각 현상의 완화 외에도 활용처가 있으리라 판단, Transformer의 인코더를 구성하는 하위층sublayer에 SLNI를 적용했습니다. 그 결과, AI Lab은 바로 위에서 언급한 특징을 갖춘 벡터를 생성하는 인코더가 훈련 조건의 변화에 강건한 제로샷 모델을 만드는 데 도움이 됐음을 발견했습니다. 다음 실험 결과 항목에서 이 내용을 보다 자세히 설명하겠습니다.
실험 결과
AI Lab은 번역 모델로 Transformer를, 훈련 데이터셋으로는 IWSLT2017를 활용했습니다. 이 데이터셋은 한쪽이 영어, 다른 한쪽은 독일어(De), 이탈리아어(It), 네덜란드어(NI), 로마니아어(Ro)로 구성된 병렬 말뭉치입니다. SLNI를 적용한 번역 모델이 다양한 훈련 조건에도 안정적으로 문장을 합성하는지를 살펴보고자 4가지 실험 환경을 설정해 모델의 성능을 비교했습니다([표 2]).
| Default | 최대 2400 토큰/번역 방향 당, 0.2 드롭아웃 |
| AttDrop | attention dropout13 * 0.1 + activation dropout14 * 0.1 |
| LargeBatch | 최대 9600 토큰/번역 방향 당 |
| Compound | AttDrop + LargeBatch |
[ 표 2 ]1-1 MNMT 번역 모델의 인코더에 SLNI를 적용하면, 여러 실험 조건에서 안정적으로 제로샷 성능을 달성하는지를 확인하는 실험을 진행했다.
AI Lab은 SLNI를 적용한 번역 모델이 감독학습에서의 성능은 거의 그대로 유지하며, 특히 다양한 훈련 조건에서 안정적인 제로샷 성능을 확보할 수 있음을 확인했습니다. 이는 데이터 후처리post-processing나 사전 훈련, 데이터 어그먼테이션 없이 간단한 조치만으로도 만들어낸 성과라 큰 의의가 있다고 평가해볼 수 있습니다.
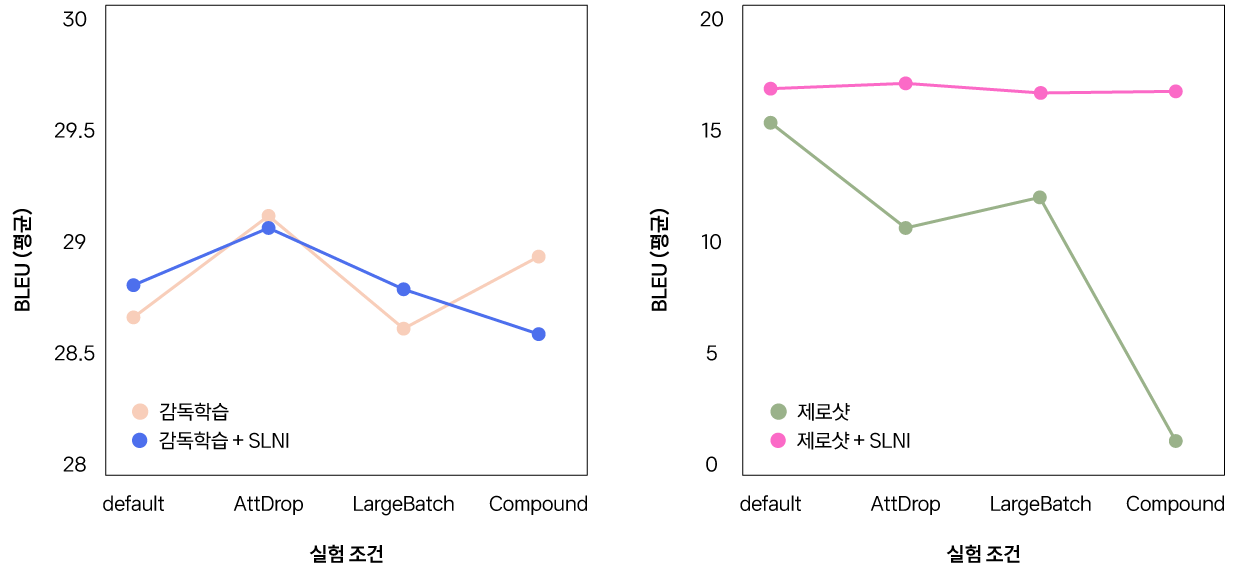
[ 그림 6 ] 감독학습(왼쪽)과 제로샷 태스크를 수행할 때 SLNI 기법의 효과를 나타내는 그래프
AI Lab은 1-1 MNMT의 인코더를 정규화하면 모든 언어의 문장 벡터가 사상된 공간의 형태가 서로 유사한지space similarity, 동일한 의미를 가진 영어 문장 벡터와 비영어 문장 문장 벡터가 비슷한 표현을 갖추는지instance similarity를 확인하는 실험도 진행했습니다. 만약 SLNI를 적용한 번역 모델이 위 두 유사성을 갖춘다면, SLNI를 적용하지 않은 버전(naive)와 비교해 더 높은 숫자를 갖춰야 합니다. 하지만 실험 결과, 두 버전 간 숫자간 격차가 크지 않음을 확인했습니다. 즉, 이 실험은 SLNI가 기존 인코더 정규화 기법을 다룬 연구에서 전제한 내용과는 다른 원리로 얽힘 문제를 해결했음을 보여줍니다.
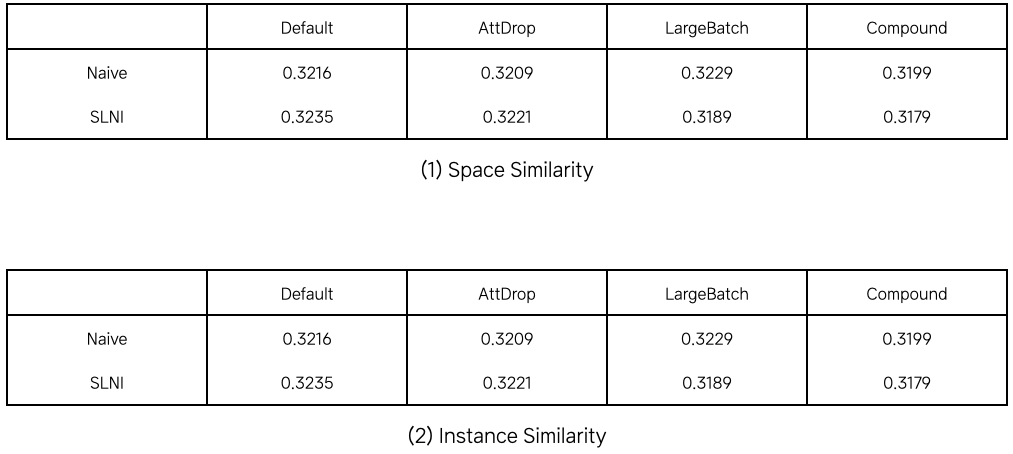
[ 표 3 ] 1-1MNMT에서 인코더를 정규화하는 접근 방식이 언어에 독립적인 특징 벡터를 생성한다는 걸 전제로 하지 않음을 실험적으로 증명했다.
향후 계획
AI Lab은 M2NMT가 생성한 언어에 독립적인 특징 공간의 여러 효용을 검증하는 연구는 물론, 제로샷 태스크에서 1-1 MNMT가 훈련 조건 변화에 취약한 원인과 새로 제안한 기법의 문제 해결 원리에 관한 새로운 탐색을 해나갈 계획입니다. 그 뿐만 아니라 도메인에 특화된 번역 모델과 지속 학습에서 안정적으로 성능을 내는 기법에 대한 연구도 진행할 계획입니다. 앞으로도 자사 기술력을 집약한 카카오 i 번역 엔진에 대한 많은 애정과 관심 부탁드립니다.
참고 문헌
[1] Revisiting Modularized Multilingual NMT to Meet Industrial Demands (2020) by Sungwon Lyu, Bokyung Son, Kichang Yang, Jaekyoung Bae in EMNLP
[2] Sparse and Decorrelated Representations for Stable Zero-shot NMT (2020) by Bokyung Son, Sungwon Lyu in EMNLP
[3] 일상생활 속으로 들어온 기계 번역 (2017) by 김준석 in 국립국어원
[4] Multi-way, multilingual neural machine translation with a shared attention mechanism (2016) by Orhan Firat, Kyunghyun Cho, Yoshua Bengio in ACL
[5] Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation Melvin Johnson (2017) by Mike Schuster, Quoc V. Le, Maxim Krikun, Yonghui Wu, Zhifeng Chen, Nikhil Thorat, Fernanda Viégas, Martin Wattenberg, Greg Corrado, Macduff Hughes, Jeffrey Dean in ACL
[6] Improving Massively Multilingual Neural Machine Translation and Zero-Shot Translation (2020) by Biao Zhang, Philip Williams, Ivan Titov, Rico Sennrich in ACL
[7] Effective strategies in zero-shot neural machine translation (2017) by Thanh-Le Ha, Jan Niehues, Alexander Waibel in Arxiv
[8] Improved Zero-shot Neural Machine Translation via Ignoring Spurious Correlations (2019) by Jiatao Gu, Yong Wang, Kyunghyun Cho, Victor O.K. Li in ACL
[9] Selfless Sequential Learning (2019) by Rahaf Aljundi, Marcus Rohrbach, Tinne Tuytelaars in ICLR
각주
먼저 단위정보 시퀀스를 인코더에 입력한다. 인코더는 이를 분석해 고정 길이의 벡터 표현vector representation을 추정한다. 디코더는 이 벡터를 활용해 또 다른 단위정보의 시퀀스를 생성한다. ↩
이를 테면, 한국어→영어, 한국어→일본어 방향의 번역에서는 하나의 한국어 인코더를 사용한다. 반대로, 영어→한국어, 일본어→한국어 번역에서도 하나의 한국어 디코더만 사용한다. ↩
모든 학습 데이터에 대해 오차를 최소화하는 가중치 값을 찾은 상태 ↩
기계 번역을 위한 seq2seq 구조의 모델의 RNN 셀에서 특정 시퀀스를 디코딩할 때 관련 인코딩 결과값을 참조할 수 있게 하는 보조적인 역할을 하는 데 처음 사용됐다. 이후 구글이 Transformer를 통해 어텐션만으로도 문장을 모델링하는 셀프어텐션self-attention 기법을 선보였다. ↩
정답label이 주어진 데이터셋으로 훈련하는 방식 ↩
새로운 언어가 포함된 방향의 번역 태스크의 훈련은 기존 언어별 인코더와 디코더의 가중치를 고정한 상태에서 진행한다. ↩
IWSLT14(En-De) ↩
기계가 생성한 문장을 다시 학습에 사용한다는 특성 때문에 역번역이라는 이름이 붙여진 거로 보인다. ↩
이미지를 좌우로 뒤집거나(flipping) 자르는(cropping) 등 데이터에 인위적인 변화를 가하는 방법론 ↩
설명력이 높으면서도 그 구조나 표현이 간단한 상태를 이르는 말 ↩
학습 중간에 또는 기존 주어진 데이터셋의 학습이 끝나고 난 상황에서 새로운 데이터나 새로운 범주의 데이터가 입력해 모델을 업데이트하는 학습 방식 ↩
평균을 중심으로 좌우 대칭의 종모양을 갖는 확률분포를 가리킨다. 여기서는 이 가우시안 분포 함수에 근사해 생성한 패널티 함수를 가리킨다. ↩
multihead attention에 주는 dropout ↩
2-layer feedforward 중간에 있는 relu activation 뒤의 dropout ↩
만든이

|

|

|

|

|

|

|