NLP
텍스트 스타일을 바꾸는 딥러닝 기술
2021-05-25
오늘날 많은 기업에서는 챗봇을 이용한 고객 응대 서비스도 제공하고 있습니다. 콜센터를 구축하는 비용보다 훨씬 더 저렴하고, 더 많은 고객을 동시에 응대할 수 있는 효용성을 갖춘 덕분입니다. 그 결과, 고객은 대기자가 많아 상담사 연결까지 한참을 기다리거나 수많은 상품 소개 메뉴를 찾아다닐 수고를 조금은 덜게 됐습니다.
보통 이런 챗봇은 매뉴얼에 따라 질문을 입력해야만 사용자가 원하는 답을 하도록 구현돼 있습니다. 자신이 가진 문제나 질문을 해결하려는 용도로 챗봇을 이용하는 사용자에게 ‘챗봇과의 교감적 대화’는 별로 중요한 기능이 아니기 때문입니다.
하지만 과중한 업무에 치이는 상담사의 완벽한 업무 파트너로 발전하기 위해서는 챗봇에 공감적 대화 능력이 요구될 거로 보입니다. 누군가와 대화를 하고 사회적인 관계를 맺는 데 핵심 역할을 하는 ‘감정’을 보여준다면 사용자는 대화할 맛을 느끼게 되겠죠. 앵무새같이 말하는 무심한 챗봇보다는, 내가 처한 상황에 적절한 감정적 반응’도’ 보이는 챗봇에 누구라도 더 큰 호의를 가질 수밖에 없으리라는 판단은 바로 이런 이유 때문입니다.
감정 교감형 챗봇을 만드는 첫걸음은 처지와 상황이 다른 두 제자의 똑같은 질문에 각기 다른 답을 내어준 공자처럼1, 같은 질문이더라도 맥락과 상황, 또는 대화 대상자에 따라 다른 반응을 보이도록 설계하는 데 있습니다. 하지만 현재의 챗봇 시스템은 특정 문장에 항상 같은 반응을 보입니다. 모든 이에게 같은 답변을 내주는 일은 교장님 훈화 말씀처럼 소통이 쌍방향이 아닌 한방향으로만 진행된다면 사용자는 챗봇을 지루하게 느낄 수밖에 없을 겁니다.
이런 한계를 해결하고자 많은 곳에서는 챗봇의 답변 내용은 유지하되, 사용자의 나이나 인종, 성격 등 다양한 요소로 조합된 그룹을 대표하는 스타일의 문장을 생성하는 기술 개발에 힘쓰고 있습니다. 카카오엔터프라이즈 또한 이 주제에 관한 연구를 진행하고 있으며, 최근에는 INLGInternational Natural Language Generation Conference에 논문 ‘Stable Style Transformer: Delete and Generate Approach with Encoder-Decoder for Text Style Transfer[1]’을 내기도 했습니다.
이번 시간에는 텍스트 스타일 변환에 관한 선행 연구와 카카오엔터프라이즈가 제안한 모델인 SSTStable Style Transformer의 작동 원리와 성능, 그리고 향후 연구 계획에 관한 내용을 상세히 다뤄보고자 합니다. 카카오엔터프라이즈 AI기술실 자연어처리팀 소속의 이주성 연구원을 만나 이야기를 들어봤습니다.
※텍스트의 스타일을 변환하는 모델의 성능 평가에는 긍정문을 부정문으로, 또는 부정문을 긍정문으로 바꾸는 벤치마크 데이터셋이 주로 활용됩니다. 이에 따라 본문에서는 명료한 설명을 위해 스타일 속성값을 긍정 또는 부정으로만 바꾸는 태스크를 수행하는 모델로 한정했습니다.
※반복적으로 등장하는 “스타일에 해당하는 토큰”, “내용에 해당하는 토큰”은 각각 “‘스타일’ 토큰”, “‘텍스트’ 토큰”으로 보다 간단하게 표현했습니다. 아울러 두 대상을 지칭할 때는 맥락에 따라 토큰 또는 텍스트로 적었습니다.
※내용 이해를 돕기 위해 실제 모델 훈련에 쓰이는 영어 문장 대신 한글 문장을 예시로 들었으며, 모든 예문에서는 띄어쓰기를 기준으로 토큰을 나눴다고 가정했습니다.
∙ ∙ ∙ ∙ ∙ ∙ ∙
선행연구 소개
텍스트 스타일 변환(TSTText Style Transfer)은 입력 문장의 내용content은 보존하고, 스타일style2에 해당하는 텍스트를 바꾸는 태스크입니다. “그 레스토랑은 불친절해”라는 문장에서 내용에 해당하는 부분(‘그 레스토랑은’)은 그대로, 스타일에 해당하는 부분(불친절해)과는 반대되는 의미를 지닌 텍스트(‘친절해’)로 바꾸는 긍·부정 전환이 대표적인 예입니다. 최근에는 여러 스타일 속성을 동시에 변환하는 연구[2]도 활발하게 진행되고 있습니다.

[ 표 1 ] 텍스트 스타일 변환 예시 문장. (슬픔), (기쁨), (화남), (크리스마스)처럼 텍스트로 표현하는 이모지도 전환할 수 있다. (출처 : [2])
딥러닝 모델에 TST 태스크를 가르치기 위해서는 “그 음식 맛없어(부정)”와 “그 음식 맛있어(긍정)”처럼 한 속성에 대한 상반된 값이 쌍으로 존재하는 병렬 말뭉치parallel corpus를 이용한 감독학습supervised learning을 고려해볼 수 있습니다. 하지만 이런 형태의 병렬 말뭉치 구축에는 시간과 비용이 많이 들죠. 이에 많은 연구에서는 긍정 문장 또는 부정 문장으로만 구성된 단일 말뭉치를 이용한 비감독학습unsupervised learning을 시도합니다.
초기 연구에서는 적대적 학습adversarial learning3을 통한 해석 가능한 표현disentangled latent representation을 생성하는 데 집중했습니다[3]. 과정은 다음과 같습니다. 입력 문장이 긍정인지 부정인지를 구분하지 못할 때까지 학습을 반복하면, 생성 모델의 인코더encoder가 입력 문장에서 ‘스타일’ 토큰을 제외한 나머지를 보고 ‘내용’ 벡터를 효과적으로 표현하리라 가정했습니다([그림1]). 그러고 나면, 이 벡터와 타깃 스타일 속성값을 디코더decoder에 입력하면 사용자가 원하는 스타일의 문장이 생성할 수 있다고 본 거죠. 하지만 실제 실험에서는 적대적 학습을 통해 입력 문장에서 ‘내용’ 벡터만을 분리하기가 쉽지 않았습니다[4]. 또한, 다양한 길이의 문장을 항상 같은 크기의 벡터로 변환하는 데에도 한계가 있음이 발견됐습니다.
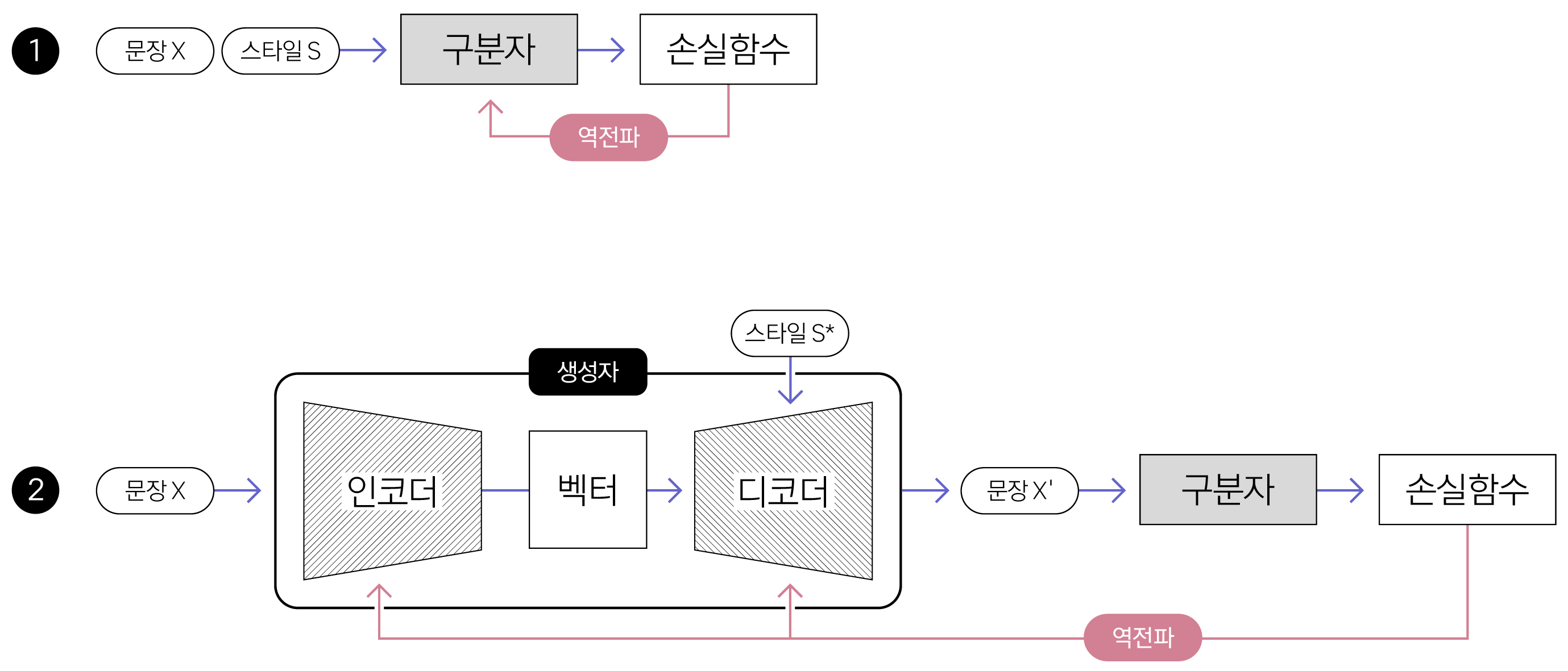
[ 그림 1 ] 적대적 학습으로 TST 모델을 훈련하는 과정
이처럼 입력 문장을 보고 ‘내용’ 토큰만을 벡터로 표현하는 대신, ‘스타일’ 토큰을 아예 삭제하는 방법론[5]이 제안됐습니다. 이를 위해 ‘스타일’ 토큰을 삭제하는 모듈과 나머지 문장 요소(내용)만을 가지고 타깃 스타일 속성값에 해당하는 문장을 생성하는 모듈을 각기 따로 둡니다. 이 방식은 앞서 설명한 방식보다 ‘내용’ 토큰을 더 잘 보존하고, ‘스타일’ 토큰은 더 효과적으로 바꿨습니다. 그러나 문장을 구성하는 모든 텍스트가 상호 작용하는 그 특성상, ‘스타일’ 토큰을 효과적으로 삭제하는 데 한계가 있었습니다[6]. 이에 ‘스타일’ 토큰을 임의로 삭제하지 않고도 스타일을 변환하는 E2Eend-to-end 방식이 제안되기도 했습니다.
SST가 문제를 해결한 방식
카카오엔터프라이즈는 입력 문장에서 ‘스타일’ 토큰을 명시적으로 삭제하고, ‘내용 토큰과 타깃 스타일 속성값만을 가지고 문장 벡터를 생성하는 접근 방식에서 영감을 얻었습니다. 카카오엔터프라이즈가 고안한 SST 모델 또한 1)문장에서 ‘스타일’ 토큰을 삭제한 뒤, 2)’콘텐츠’ 토큰만을 가지고 입력 문장과는 반대되는 스타일 속성값을 가진 문장을 생성합니다. 다만 기존과는 다른 방식으로 각 모듈을 구현했는데, 이는 각 단락에서 이어 하겠습니다.
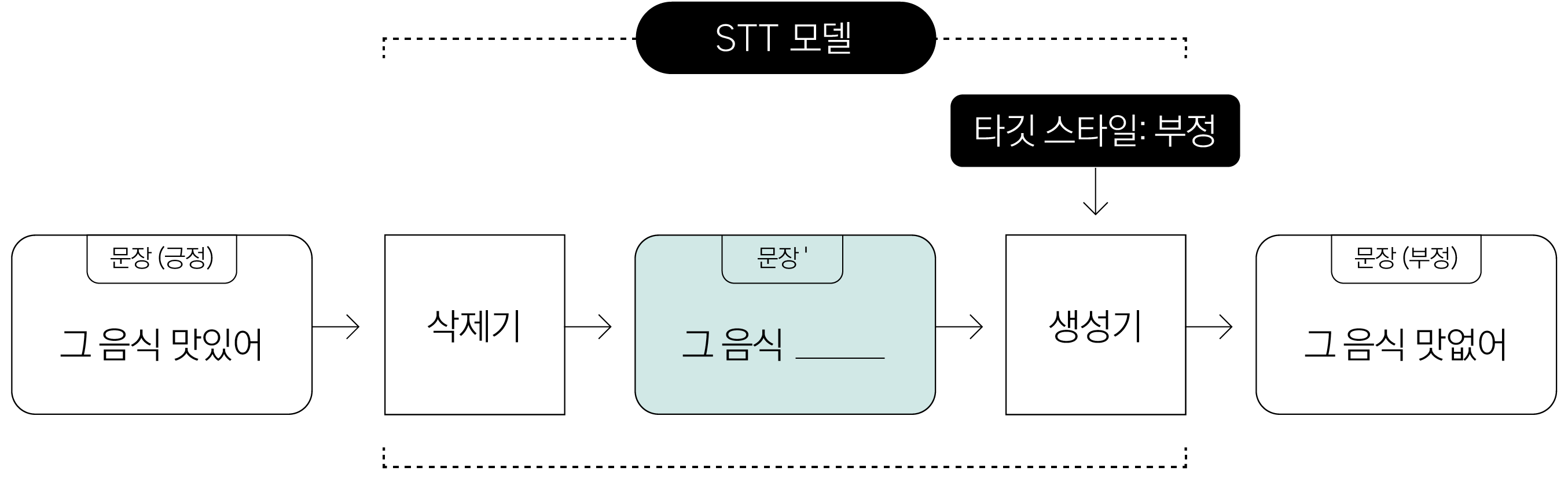
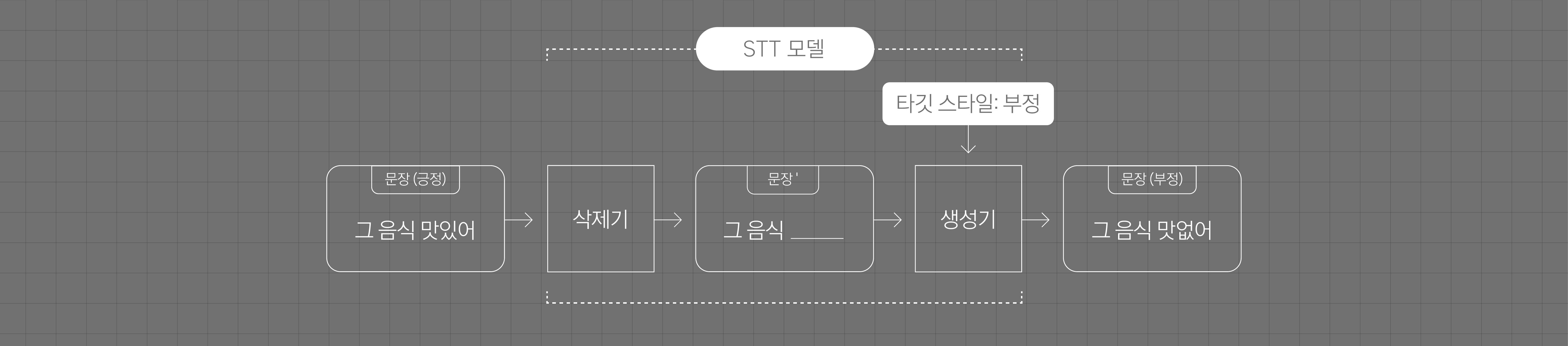
[ 그림 2 ] 문장의 스타일 속성값을 긍정에서 부정, 또는 부정에서 긍정으로 전환해 문장을 생성하는 STT 모델의 동작 과정
(1) 스타일 삭제 프로세스
카카오엔터프라이즈가 제안한 스타일 삭제기의 동작 방식을 설명하는 데 앞서, 기존에 제안한 방식의 동작 원리와 그 한계에 대해 먼저 간단하게 짚어보겠습니다.
빈도비frequency-ratio를 활용한 방식은 삭제기에 입력된 문장의 토큰 중, 사전4에 등록된 토큰과 일치한다면 이를 ‘스타일’ 토큰으로 판단해 삭제합니다. 이 방식의 한계는 사전에 등록되지 않은 ‘스타일’ 토큰을 인식하지 못할 가능성이 매우 크다는 데 있습니다. 그렇다고 해서 이 세상에 존재하는 ‘스타일’ 토큰을 모조리 찾아 등록할 수도 없습니다. 규칙 기반으로 동작하는 그 특성상 맥락을 파악해야 어느 부분이 ‘스타일’ 토큰인지 알 수 있는 문장5에서는 잘 동작하지 않을 가능성도 높습니다.
이런 한계를 극복하고자 어텐션attention6을 활용해 스타일 토큰을 삭제하는 방식[7]이 고안됐습니다. 과정은 다음과 같습니다. 먼저, BERT에 문장을 입력해 [CLSSpecial Classification token]7에 해당하는 벡터를 얻습니다. 그다음, 입력 문장의 각 토큰이 CLS 디코딩에 영향을 미친 정도(어텐션)를 점수로 환산합니다. 가장 높은 점수를 낸 토큰을 문장을 긍·부정으로 분류하는 데 영향을 미친 ‘스타일’ 토큰이라고 판단하고, 이를 삭제합니다.
하지만 어텐션 점수를 사용하는 방식도 문장 전체의 의미를 파악하는 데 한계가 있습니다. “음식이 맛있다고 하는데 나는 그닥(부정)”이라는 문장을 한 번 보겠습니다. 이 문장은 부정의 의미를 담은 주절(나는 그닥)과 긍정의 의미를 담은 종속절(음식이 맛있다)로 이뤄져 있습니다. 모델은 핵심 내용을 담고 있는 주절에 집중해서 스타일 속성값을 파악해야 합니다. 하지만 어텐션 기반 모델은 ‘맛있다’와 [CLS]와의 관계, ‘그닥’과 [CLS]와의 관계를 각각 독립적으로 파악하고서는 ‘맛있다’에 더 많은 어텐션 값을 배정, 이 문장을 ‘긍정’으로 오 분류할 가능성이 높습니다.
더불어 위 방식에서는 CLS 벡터를 출력하는 BERT 계열의 모델만을 분류기로 사용할 수 있다는 제약이 따릅니다.
이에 카카오엔터프라이즈는 ‘스타일’ 토큰을 직관적으로 구분하면서도 특정 모델의 구조에 구애받지 않는model-agnostic 삭제 프로세스를 제안했습니다. 문장을 구성하는 각 토큰을 차례대로 누락한 토큰 시퀀스를 분류기pre-trained classifier8에 입력한 후, 확률값 변화에 큰 영향을 미친 토큰을 ‘스타일’로 인식하고 이를 삭제9합니다. 예를 들어 좀 더 쉽게 설명해보겠습니다.
앞에서 언급한 예시 문장 x(음식이 맛있다고 하는데 나는 그닥)를 다시 보겠습니다([그림 3]). 문장을 구성하는 토큰을 순차적으로 누락한 문장을 분류기에 입력합니다. 그다음, 본래 문장 x를 입력해서 얻은 값과의 차이를 계산(IS)합니다. 여기서는 확률값 변화에 많은 영향을 미친 토큰은 ‘그닥’입니다. 따라서 삭제기는 이 토큰을 스타일로 인식하고 이를 삭제한 문장인 x’(음식이 맛있다고 하는데 나는)를 출력합니다.
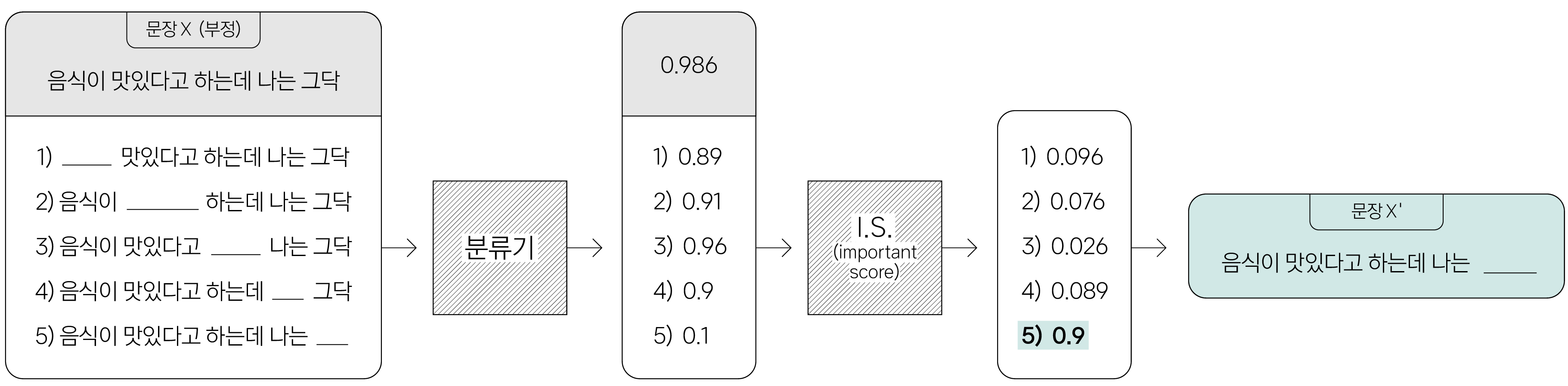
[ 그림 3 ] 입력 문장에서 ‘스타일’ 텍스트를 삭제하는 과정
(2) 스타일 전환 문장 생성 프로세스
생성기는 RNN 기반의 모델보다 더 좋은 성능을 내는 Transformer의 인코더와 디코더로 구현했습니다. ’스타일’ 토큰을 삭제한 문장 x’ 앞에는 문장의 시작을 알려주는 [start]와 스타일 속성을 표현하는 [style]10 두 스페셜 토큰special token이 붙습니다. 생성기는 문장의 끝을 알리는 [end]가 출력될 때까지 동작합니다.

[ 그림 4 ] ‘스타일’ 토큰을 삭제한 문장과 타깃 스타일 속성값을 이용해 원하는 스타일의 문장을 만드는 생성기의 작동 과정
(3) 모델 훈련
SST 또한 선행 연구에서와 마찬가지로 긍정 또는 부정의 말뭉치로 각각 구성된 비병렬 데이터셋만을 이용해야 합니다. 다시 말해, “그 레스토랑은 맛없어(부정)”라는 문장만 주어지고, 반대 속성의 문장인 “그 레스토랑은 맛있어(긍정)”가 없어서 감독학습을 불가능한 상황입니다.
이에 카카오엔터프라이즈는 가장 확실하게 알고 있는 유일한 정보가 입력 문장의 스타일 속성값(부정)이라는 점을 고려해, 스타일 속성과 관련된 두 손실 함수를 정의하고 두 함수를 최소화하는 방향으로 생성기의 인코더와 디코더를 훈련11했습니다. 두 손실 함수를 이용해 학습을 마친 모델은 ‘콘텐츠’ 토큰을 활용해 타깃 스타일 속성값으로 전환된 문장을 생성할 수 있게 됩니다.
우선, ‘스타일’ 토큰을 삭제한 문장(“그 레스토랑은”)과 입력 문장의 스타일 속성값(부정)을 입력받은 디코더가 본래 스타일로 분류될 수 있도록 하는 학습을 진행합니다. 여기에서는 크로스 엔트로피Cross Entropy를 이용한 재구성 손실 함수reconstruction loss function을 사용했습니다. 학습을 마치고 나면 디코더는 원래 주어진 스타일 속성값인 ‘부정’으로 분류되는 문장을 생성합니다.
하지만 재구성 손실 함수만으로는 디코더가 스타일 속성값을 반전하는 데에는 한계가 있습니다. 모델이 입력 문장을 다시 복구하는 법만 익혔기 때문입니다. 원래 스타일 속성값과 반대되는 문장(긍정)을 생성하는 학습도 중요합니다. ‘콘텐츠’ 토큰(“그 레스토랑은”)과 원래 주어진 스타일 속성의 반대되는 값인 ‘긍정’으로 분류될 수 있도록 모델을 훈련합니다. 여기에는 스타일 손실 함수style loss function을 이용했습니다.
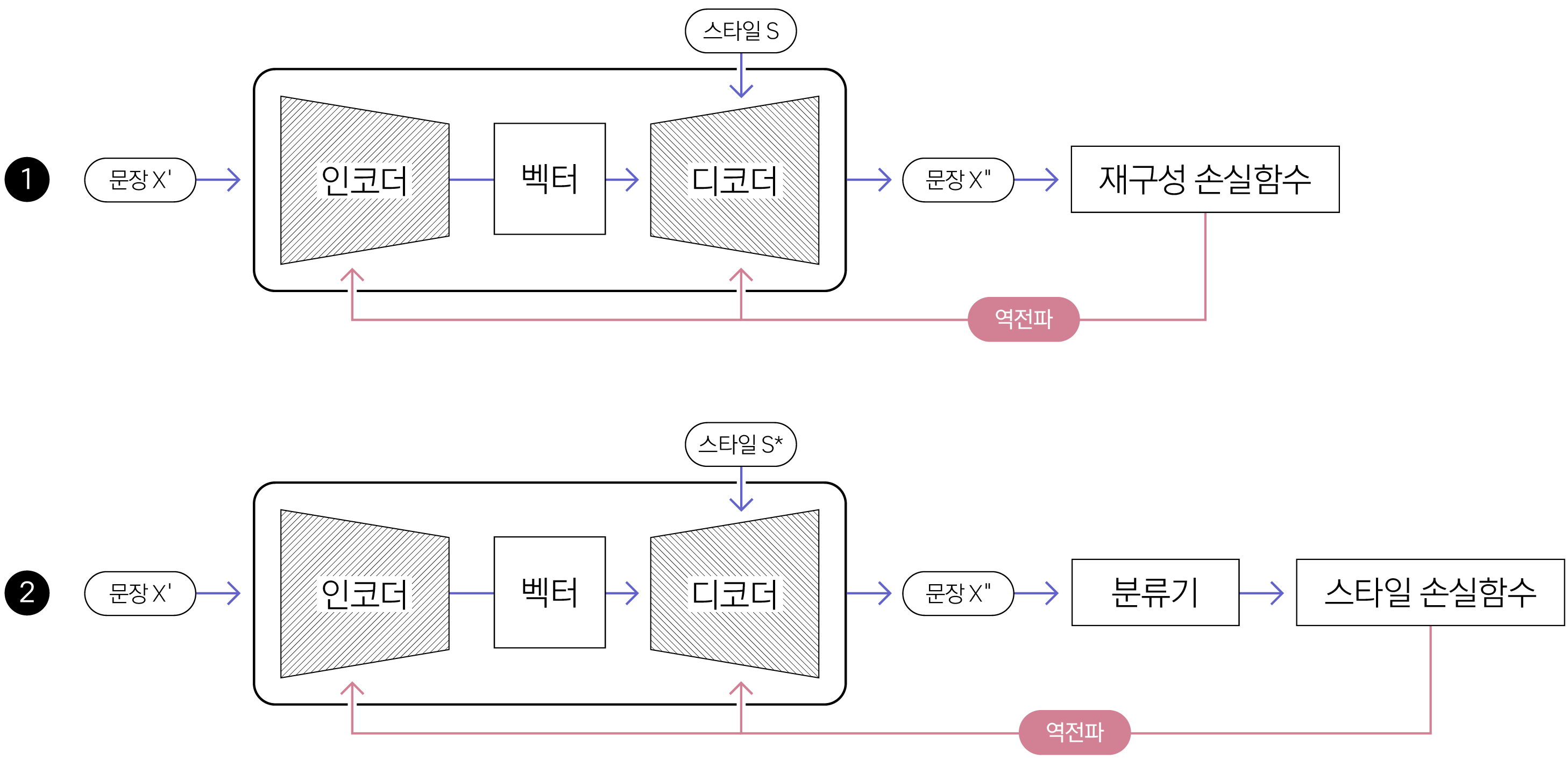
[ 그림 5 ] STT 모델에서 두 손실 함수를 이용한 훈련 과정
성능 평가 및 결과
카카오엔터프라이즈는 음식점 리뷰를 모아 놓은 옐프(Yelp)와 상품 리뷰를 모아놓은 아마존(Amazon), 두 벤치마크 데이터셋[5]을 이용해 최신의 TTS 모델의 성능을 비교했습니다. ‘콘텐츠’ 토큰을 얼마나 잘 보존했는지(content), 스타일이 제대로 전환됐는지(style), 말이 자연스러운지(fluency), 그리고 두 문장(출력 문장, 정답 문장)의 의미가 얼마나 유사한지(semantic)를 판단하는 총 4가지의 평가 항목을 마련했습니다.
| 입력 문장 | 출력 문장 | 평가 |
| “그 음식은 맛없어” | “그 음식은 별로야” | content는 보존, style은 못바꿈, fluency는 자연스러움 |
| “서비스가 별로고 가격이 매우 비싸” | “서비스가 매우 좋았고 가격이 매우 비싸” | content는 보존, style은 애매함, fluency는 약간 이상함 |
| “그것의 퀄리티는 꽤 괜찮아 보이는데 ” | “그 게임은 재미없어 보이는데” | content는 미보존, style은 바꿈, fluency는 자연스러움 |
| “그것의 퀄리티는 꽤 괜찮아 보이는데” | “그 나무는 맛없던데” | content는 미보존, style은 바꿈, fluency는 이상함 |
[ 표 2 ] TST 모델의 평가 결과 예시
각 항목 평가를 위해 총 8가지 자동화 평가 척도automatic evaluation metrics([표 3])를 활용했습니다. 인간 평가human evaluation가 더 정확하나, 시간과 비용이 많이 소모됩니다. 이에 카카오엔터프라이즈는 더 저렴하면서도 빠른 자동화 평가 척도를 가지고 안정적인 텍스트 스타일 변환 여부를 판단하고자 했습니다. 자동화 평가에서 상대적으로 좋지 않은 성능을 낸 모델이 인간에게도 좋은 평가를 받지 못한 실험적 결과가 이 선택을 뒷받침합니다.
| Content | self-BLEU | 입력 문장과 (시스템이) 생성 문장 간의 n-gram12 중첩 정도를 이용한 평가 |
| human-BLEU | 인간이 생성한 문장과 시스템이 생성한 문장 간의 n-gram 중첩도를 이용한 평가 | |
| geometric mean-BLEU | self-BLEU와 human-BLEU의 기하평균geometric mean13 | |
| Style | classification accuracy | 기학습된 분류기로 평가한 성능 |
| Fluency | d-PPLperplexity14 | 평가 데이터셋에서 미세조정한 언어 모델을 이용한 지표 |
| g-PPL | 사전학습된 언어 모델인 GPT를 이용한 지표 | |
| t-PPL | d-PPL과 g-PPL의 기하평균 | |
| Semantic | BERTScore15 | 사전학습된 BERT를 이용한 평가 |
[ 표 3 ] 성능 평가에 활용한 8가지 자동화 평가 척도16
카카오엔터프라이즈는 8가지 자동화된 평가 척도를 이용해 여러 TST 모델의 성능을 비교했습니다([표 4], [표 5]). 핵심은 다른 모델에 표시된 빨간색 숫자입니다. 이 숫자는 다른 모델과 비교해 해당 평가 척도에서 현저히 낮은 성능을 의미합니다. 아주 단적인 예로, 문장은 이진 분류binary classification이기 때문에 확률상 최소 50%의 성능은 나와야 합니다. 하지만 실제로는 이에 훨씬 못 미치는 성능을 내고 있죠. 이런 점에서 카카오엔터프라이즈가 고안한 STT 모델이 모든 평가 척도에서 두루 안정적인 결과를 냈다는 점에 주목할 만합니다.
물론 이런 안정성 판별은 상대적인 척도라서 완벽하다고 할 수는 없습니다. 특정 척도만을 이용한 평가로 어느 시스템의 절대적인 우수성을 말할 수 없을 뿐만 아니라, 자동화 평가에서 좋은 성능을 시스템을 선별해 인간 평가를 진행한다고 하더라도 좋은 결과를 기대할 수 없기 때문입니다. 향후 모델의 성능을 다각도로 측정할 수 있는 평가 척도가 나온다면, 여러 환경에 더 적합한 시스템 개발 및 평가가 한결 더 수월해질 거로 보입니다.
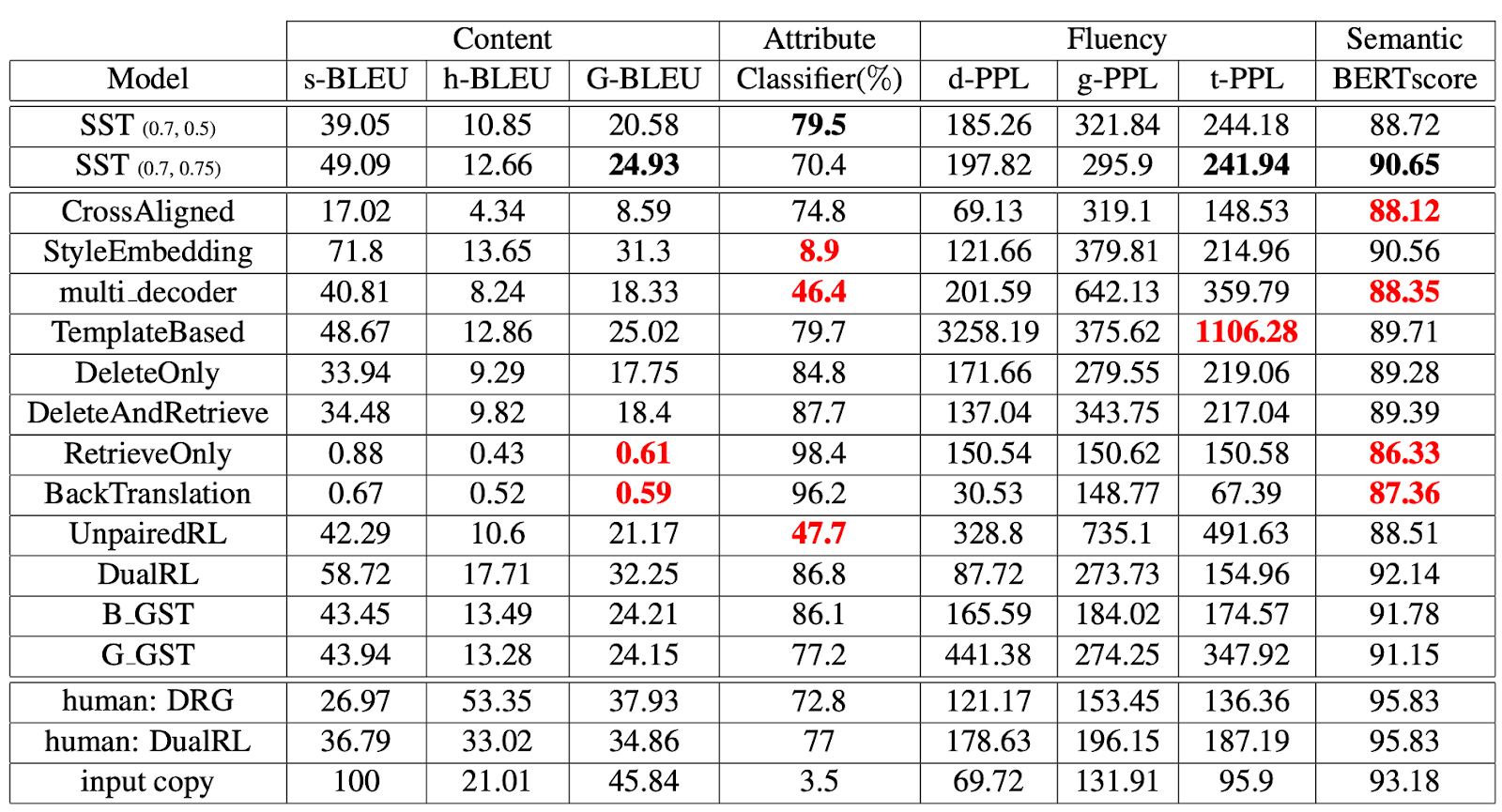
[ 표 4 ] 옐프 데이터셋에서의 성능 평가 실험
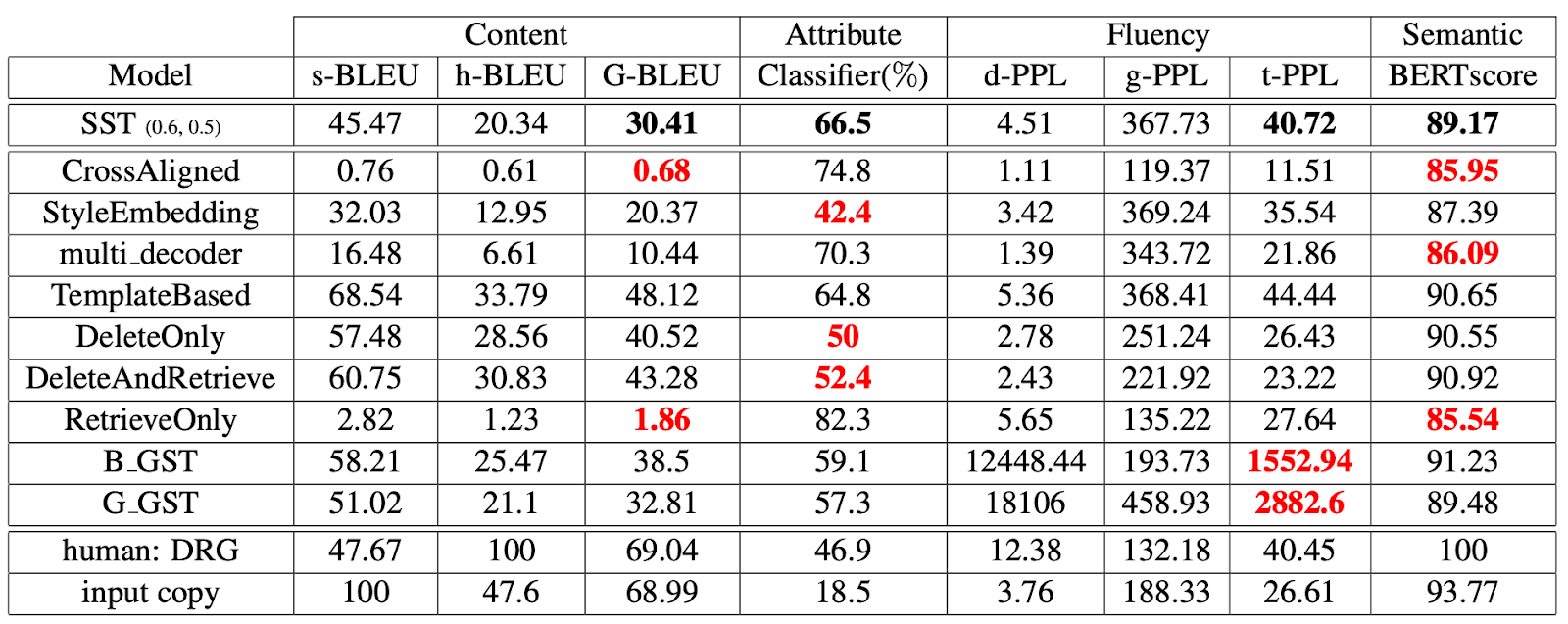
[ 표 5 ] 아마존 데이터셋에서의 성능 평가 실험
한편, 카카오엔터프라이즈는 ‘스타일’ 벡터를 부정에서 긍정 또는 긍정에서 부정으로 조금씩 바꾸면서 생성되는 문장을 확인하는 잠재 공간 탐색latent space walking에 관한 실험도 진행했습니다. 텍스트 스타일 변환 모델이 문장의 스타일 속성값을 긍정과 부정을 전환할 수 있다면, 그 중간에 중립neutral 문장도 생성되리라는 가정을 증명하려는 목적이었습니다. 하지만 아쉽게도 중립 문장이 생성됨을 확인하지는 못했습니다. 이런 측면을 고려해 모델링을 한다면 문장 스타일을 좀 더 세밀하게 조절할 수 있을 거로 보입니다.
향후 계획
카카오엔터프라이즈는 이후 텍스트 스타일 변환뿐만 아니라 사람의 감정이나 대화 상황을 이해하는 공감적 대화empathetic conversation, 데이터를 문장으로 표현하기data-to-text, 페르소나 채팅persona chat17처럼 원하는 조건에 따라 문장을 생성하는 자연어 생성에 관한 다양한 연구를 계속해서 진행할 계획입니다.
참고 문헌
[1] Stable Style Transformer: Delete and Generate Approach with Encoder-Decoder for Text Style Transfer (2020) by Joosung Lee in INLG
[2] Multiple-Attribute Text Style Transfer (2019) Guillaume Lample, Sandeep Subramanian, Eric Michael Smith, Ludovic Denoyer, Marc’Aurelio Ranzato, Y-Lan Boureau in ICLR
[3] Style Transfer in Text: Exploration and Evaluation (2018) by Zhenxin Fu, Xiaoye Tan, Nanyun Peng, Dongyan Zhao, Rui Yan in AAAI
[4] Multiple-attribute text rewriting (2019) by Sandeep Subramanian, Guillaume Lample, Eric Michael Smith, Ludovic Denoyer, Marc’Aurelio Ranzato, Y-Lan Boureau in ICLR
[5] Delete, Retrieve, Generate: A Simple Approach to Sentiment and Style Transfer (2018) by Juncen Li, Robin Jia, He He, Percy Liang in NAACL
[6] A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer (2019) by Fuli Luo, Peng Li, Jie Zhou, Pengcheng Yang, Baobao Chang, Xu Sun, Zhifang Sui in IJCAI
[7] Transforming Delete, Retrieve, Generate Approach for Controlled Text Style Transfer (2019) by Akhilesh Sudhakar, Bhargav Upadhyay, Arjun Maheswaran in EMNLP
각주
논어 ‘선진' 편을 보면, 제자 자로와 유의 똑같은 질문에 공자는 서로 다른 답변을 준다. 이에 또 다른 제자 공서화가 이를 보고 왜 그런지 묻자, 공자는 유에게는 성정을 억누를 신중함을 심어주고, 자로에게는 결단력을 북돋아 줄 필요가 있다고 답했다. ↩
성별, 감정, 나이(세대), 인종 등 화자에 따라 달라지는 발화의 스타일을 의미한다. ↩
새로운 데이터를 생성하는 생성자generator와 이 데이터를 평가하는 구별자discriminator가 서로 대립하며 각각의 성능을 높이는 목적을 달성하는 경쟁 끝에 진짜와 같은 가상의 새로운 데이터를 만들어낸다. 적대적 학습은 바로 이 두 주체가 충돌해서 발전이 이뤄지는 대립쌍 프로세스adversarial process라는 점에 기인했다. ↩
긍∙부정 레이블을 단 데이터셋에 자주 등장하는 스타일 토큰을 모아둔 데이터베이스 ↩
“이렇게 만들면 잘도 맛있겠네요" 문장이라면, ‘맛있겠네요'에만 집중했을 때 이 문장을 자칫 긍정(맛있다)으로 인식할 수 있다. 하지만 전체 맥락을 살펴보면, ‘맛없다'를 반어적으로 표현한 문장임을 알 수 있다. ↩
특정 시퀀스를 디코딩할 때 관련된 인코딩 결과를 참조하게 만드는 기법 ↩
Special Classification Token의 약자로, 입력 문장을 구성하는 모든 토큰의 의미를 응축하고 있다. ↩
STT 모델 훈련에 쓰인 같은 데이터로 미리 훈련해준다. ↩
삭제 프로세스는 1)부정 확률이 적정 수준으로 떨어지거나, 2)전체 문장에서 일정 비율의 토큰이 삭제됐을 때 종결된다. ↩
학습 단계에서 어떤 손실 함수를 이용하느냐에 따라 [style]은 입력 문장의 속성값 또는 타깃 스타일 속성값 둘 다 될 수 있다. 모델 훈련 과정에서 이를 상세히 설명해두었다. 반면, 테스트 단계에서는 스타일 속성을 얼마나 잘 바꾸는지를 평가해야 하므로 타깃 스타일 속성값을 나타낸다. ↩
두 손실 함수를 합쳐서 학습을 진행해도 성능 면에서 큰 차이가 없다. 다만 카카오엔터프라이즈는 본 연구를 진행할 때 두 손실 함수를 번갈아가며 모델을 훈련했으며, 학습률을 서로 다르게 설정해 재구성손실 함수가 모델의 가중치를 더 많이 업데이트할 수 있도록 했다. ↩
어떤 한 입력을 처리할 때 함께 볼 N개의 입력 단위(토큰)를 뜻한다. ↩
n개의 요소를 곱한 후 그 값에 n 제곱근을 씌운 값 ↩
언어 모델의 성능을 정량적으로 평가하기 위한 지표를 의미한다. ↩
성능 격차가 크지 않아 안 좋은 시스템이 무엇인지 고르기 애매하다. 이에 이 부분은 시스템을 가우시안 분포로 가정하고 신뢰도 95% 이내에 포함되지 않는 점수를 가지는 시스템을 불안정한 시스템으로 결정했다. ↩
PPL을 제외한 나머지 척도에서는 숫자가 클수록 모델의 성능이 좋다고 할 수 있다. ↩
시스템 설계자가 미리 정의한 고유 페르소나(인격)를 가진 가상의 상대와 대화를 나누는 태스크를 가리킨다. 여기서 페르소나는 4~6문장으로 표현된다. 이를테면, 대화 중에 페르소나(예: 나는 딸기를 좋아합니다)와 관련된 주제가 언급되면(“넌 무슨 케이크를 좋아해?”), 모델은 관련 내용으로 응답한다(“나는 딸기 케이크를 좋아해.”). ↩
만든이

|

|

|