NLP
텍스트 요약 모델 성능 평가를 위한 새로운 척도, RDASS를 소개합니다.
2021-07-29
인터넷 뉴스, 블로그, 카페, SNS 등을 통해 매일같이 홍수처럼 쏟아지는 정보로 인해 현대인은 자신이 원하는 정보를 찾는 데 큰 어려움을 느끼고 있습니다. 이에 따라 선별된 양질의 정보에 대한 사용자 요구가 점차 늘어나면서, 이를 충족하기 위한 다양한 큐레이션 서비스가 전보다 더 크게 주목받고 있습니다. IT업계 실무 담당자가 읽은 양질의 콘텐츠를 요약 정리하는 플랫폼인 커리어리나 디지털 콘텐츠와 콘텐츠 비즈니스 업계에 관한 최신의 뉴스와 도서 내용을 큐레이션하는 뉴스레터 프로젝트 썸원 등이 대표적이죠.
하지만 새롭게 생성되는 콘텐츠의 양은 사람이 통제할 수 없을 정도로 매우 방대합니다. 대단히 많은 문서를 빠르고 효과적으로 처리하기 위한 목적으로 본문의 핵심 내용을 자동으로 요약해주는 기술의 중요성이 점차 강조되는 건 바로 이 때문입니다. 관련 자연어처리 연구 과제로는 원본 문서를 참고해 짧은 분량의 텍스트를 생성하는 텍스트 요약text summarization이 있습니다.
텍스트 요약 모델의 작동 방식은 크게 2가지로 나눠볼 수 있습니다. 1)문서에서 뽑은 단어를 조합해 문장을 생성하는 추출요약(extraction)과 2)의미가 바뀌지 않은 선에서 문서에서 쓰이지 않은 단어 또는 표현을 이용해 문장을 만들어내는 생성요약(abstraction), 이렇게 말이죠[1]. 추출요약 방식으로 선별된 단어가 문서를 충분히 대표하지 못하거나, 선별된 단어 간의 호응이 떨어지는 문제를 해결하기 위해 나온 생성요약 쪽의 연구가 현재는 더 활발하게 이뤄지고 있습니다.
하지만 최신의 요약 모델은 과거 추출요약의 정확도조차 달성하지 못하고 있습니다. 더 나은 성능의 요약 모델을 만들려면 모델로부터 자동으로 생성된 요약문을 어느 정도로 신뢰할 수 있는지 판별하기 위한 적절한 평가 방법이 있어야 합니다. 문제는 가장 보편적으로 쓰이는 성능 평가 척도가 모델의 성능을 제대로 평가하지 못한다는 거죠. 모델의 성능을 제대로 평가할 수 있어야 모델 성능 개선을 위한 다양한 시도를 할 수 있다는 점에서 새로운 평가 척도를 만들려는 연구 또한 자연어처리 분야에서 중요하게 다뤄지고 있습니다.
이러한 연구 흐름에 발맞춰 카카오(이동엽)와 카카오엔터프라이즈 (신명철, 조승우, 고병일, 이다니엘, 김응균), 고려대학교 (황태선), 한신대학교(조재춘)는 텍스트 요약 모델의 성능을 평가할 새로운 척도인 RDASSReference and Document Aware Semantic Score[2]를 공동 제안했습니다. 이 성과를 정리한 논문이 COLINGInternational Conference on Computational Linguistics1에 게재 승인되기도 했습니다.
이번 글에서는 기존 성능 평가 척도인 ROUGE의 한계와 새롭게 제안한 RDASS의 계산 과정, RDASS의 타당성을 검증하는 실험 결과에 대해 상세히 다뤄보고자 합니다. 논문 제1저자인 카카오 소속의 이동엽 연구원을 만나서 자세한 이야기를 들어봤습니다.
※카카오엔터프라이즈는 인공지능 기술의 공동 연구를 위해 공동체(카카오의 계열사 및 자회사를 이르는 말)와 다자간 업무 협약(MOU)을 체결한 바 있습니다. 이 연구는 이런 긴밀한 협력하에 이뤄진 카카오엔터프라이즈와 카카오 양사의 공동 연구임을 다시 한번 밝힙니다.
※신명철 연구원은 기존 연구의 문제점 고찰과 이를 해결할 새로운 아이디어의 고안을 함께했습니다. 이후 실험 및 논문 작성은 이동엽 연구원이 맡았습니다. 황태선 연구원, 조승우 연구원은 논문에 삽입되는 표, 그림, 성능 평가 작업을 지원했습니다. 고병일 연구원은 S-BERT를 훈련했으며, 이다니엘 연구원, 김응균 연구원, 조재춘 교수가 논문을 검토했습니다.
∙ ∙ ∙ ∙ ∙ ∙ ∙
선행 연구
자연어처리 모델의 성능은 사람이 문장을 직접 읽고 산출한 점수(manual)나 알고리즘으로 계산한 값(automatic)으로 비교해볼 수 있습니다. 많은 연구에서는 상대적으로 저렴한 비용에 빠르게 성능을 비교할 수 있다는 이유로 자동화 방식을 선호합니다. 문서 요약 분야에서도 관련 전문가가 일일이 검토하는 대신, 자동화 방식으로 모델의 성능을 평가하는 방법이 제안됐습니다.
자동화 방식 중 가장 널리 쓰이는 ROUGE[3]는 전문가가 만들어 놓은 정답 요약문과 모델이 생성한 문장의 유사도를 비교합니다. 이를 위해 두 문장 간에 n-gram2이 얼마나 많이 겹치는지를 계산합니다. 일반적으로 0~1 사이의 숫자나, 여기에 100을 곱해준 값을 이용해 유사도를 나타내며, 이 숫자는 두 문장의 철자의 일치하는 정도를 나타냅니다. 따라서 숫자가 클수록 모델의 성능이 좋다고 보면 됩니다.
하지만 인간이 실제로 문장을 요약하는 방식을 생각해 본다면 ROGUE의 한계는 너무나 명확합니다. 요약의 핵심은 1)문서에서 핵심 내용을 잘 선택했는가(content selection), 2)문서에 쓰이지 않은 다른 표현이지만 같은 의미를 잘 나타내는가(paraphrase)입니다. 하지만 ROGUE는 주어진 두 문장의 형태학적 유사도만 높다면 의미적 유사도가 낮더라도 더 높은 점수를, 반대의 상황에서는 더 낮은 점수를 부여하며 위 2가지 핵심을 모두 놓칩니다.
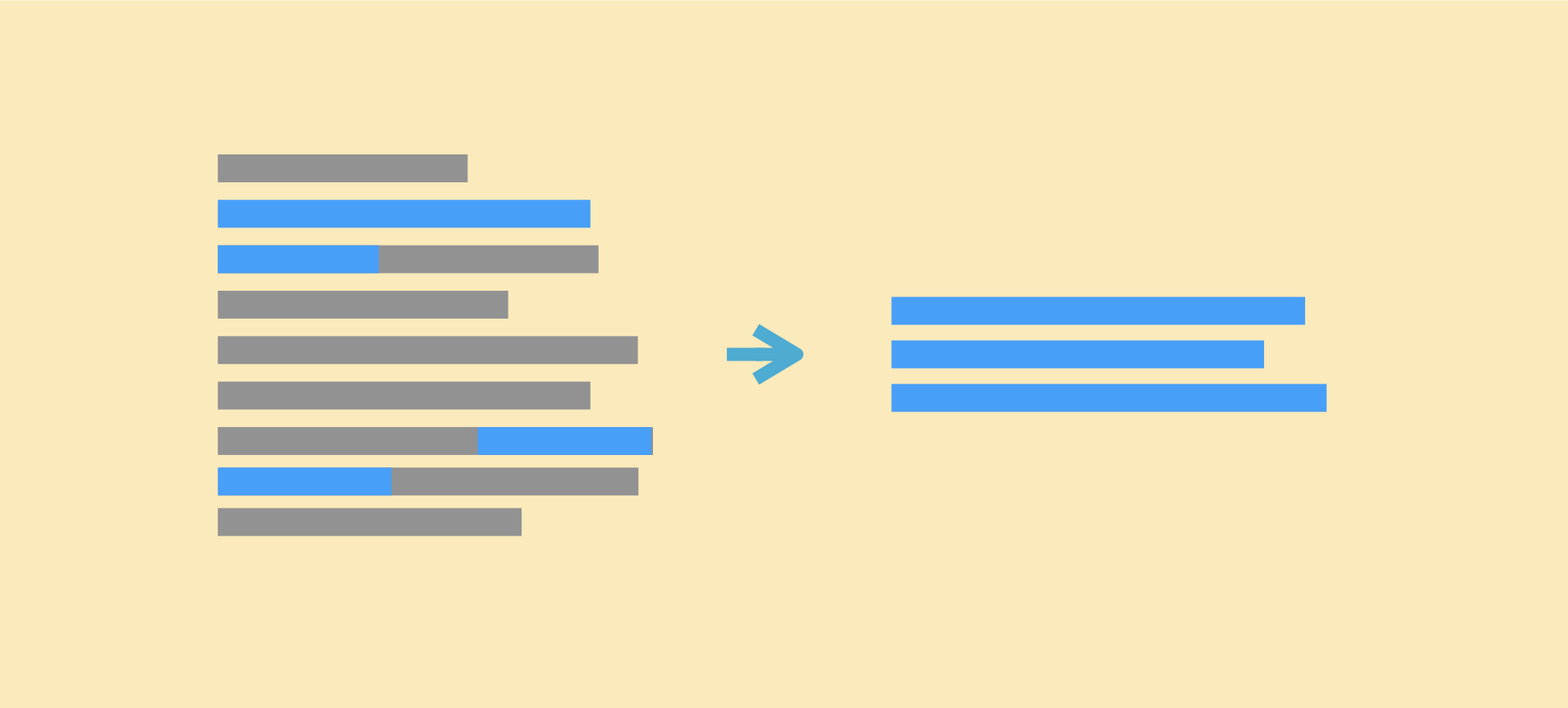
좀 더 쉽게 설명해보겠습니다. 축구선수 리오넬 메시의 생일날 일정을 소개한 기사를 요약한다고 했을 때([그림 1]), ROGUE는 모델이 생성한 문장이 정답 문장과 유사도가 매우 낮다고 평가합니다. 두 문장에서 하늘색으로 강조 표시한 부분의 의미적 유사성은 매우 높지만, 철자의 일치도가 낮아 이런 점수가 나왔습니다. 심지어 모델이 생성한 문장이 문서에 등장한 표현(하늘색)과 의미적, 형태학적 유사도가 상대적으로 더 높으나 ROUGE는 이 부분을 간과합니다. 이는 생성 문장이 문서의 내용을 얼마나 잘 표현했는지를 계산하는 부분이 반영돼 있지 않아서 발생하는 문제입니다.

[ 그림 1 ] ROGUE는 두 대상 간의 형태학적 유사성만을 평가 기준으로 삼는다.
ROGUE의 한계는 한국어 문서 요약 태스크에서 더 도드라져 보입니다. 어근3에 붙은 다양한 접사4가 단어의 역할(의미, 문법적 기능)을 결정하는 언어적 특성을 갖춘 한국어에서는 복잡한 단어 변형이 빈번하게 일어나기 때문이죠. [그림 2]는 드라마 ‘슬기로운 의사생활’ 기사를 요약한 정답 문장과 모델이 생성한 요약 문장을 비교한 예시입니다. ROGUE는 정답 문장과 비교해 철자가 겨우 3개만 다른 오답 문장에 더 높은 점수를 부여합니다.

[ 그림 2 ] ROGUE는 특히 한국어 요약 모델 성능 평가에 취약하다.
이런 한계를 극복하기 위해 ParaEval[4], ROUGE-WE[5], ROGUE2.0[6] 등의 척도가 새롭게 제안됐습니다. 하지만 이 방법론을 적용하려면 사람이 직접 방대한 크기의 동의어(유의어) 사전을 따로 구축해야 한다는 제약이 따릅니다.
또 한편, 공동 연구팀은 사람마다 요약 방식이 달라 하나의 정답 요약문만을 기준으로 요약 모델을 평가하는 데에는 한계가 있다고 판단했습니다. 이에 요약 모델이 문서의 내용을 얼마나 잘 반영하는지를 참고해 성능을 평가할 필요가 있다고 봤습니다.
공동 연구팀은 1)의미적 유사도는 높으나 형태학적 유사도가 낮은 문장을 생성하는 모델의 성능이 낮다고 판단하는 문제를 해결하기 위해 정답 문장과 생성 문장의 유사도, 문서와 생성 문장 간의 유사도를 모두 참고하며, 2)방대한 유의어 사전을 따로 구축할 필요가 없는 새로운 평가 척도인 RDASS를 고안했습니다.
RDASS의 작동 과정
1.문장 임베딩 모델의 사전학습과 미세조정
기계가 생성한 문장과 정답 문장의 유사도 계산을 위해서는, 먼저 각 문장을 고정된 크기의 벡터로 전환해야 합니다. 이 전환 기법을 문장 임베딩sentence embedding이라고 부릅니다. 문장을 구성하는 각 단어를 BERT로 출력한 결과값의 평균, 또는 모든 단어의 의미를 응축한 특별 분류 토큰[CLSspecial classification token]의 출력값 문장 임베딩으로 활용하는 방식이 보편적입니다.
하지만 이렇게 생성한 문장 임베딩이 요약 모델이 안정적인 성능을 내는 데 항상 유효하지는 않습니다. 입력 질의query와 유사한 문서를 찾아주는 검색retrieval과 같은 태스크에서 GLOVE[7]5로 생성한 단어별 임베딩 벡터의 평균값보다 되려 더 낮은 성능을 낼 수 있다는 연구 결과가 이를 뒷받침하죠6. 이에 현재는 BERT보다 문장의 의미를 더 잘 추출하는 Sentence-BERT(이하 SBERT)[8]의 출력값을 문장 임베딩으로 많이 활용합니다.
공동 연구팀은 병렬 말뭉치로 구성된 NLINatural language Inference7와 STSSemantic Textual Similarity8 벤치마크 데이터셋을 이용해 SBERT를 사전훈련했습니다. 그러고 나서, 정답 문장과 생성 문장의 유사도와 문서와 생성 문장 간의 유사도를 모두 고려할 수 있도록 사전훈련된 SBERT(이하 P-SBERT)와 요약 모델을 동시에 미세조정fine-tuning했습니다. 학습에 이용되는 트리플렛 손실 함수triplet loss function는 범주가 같은 두 문장 벡터와 범주가 다른 두 문장 벡터 간의 상대적인 관계를 고려하는데, 이 과정을 좀 더 자세히 설명하면 다음과 같습니다.
- 요약 모델이 생성한 문장의 벡터(Hp), P-SBERT로 추출한 정답 문장 벡터(Vpr), P-SBERT로 추출한 임의의 오답 문장9 벡터(Vnr)로 구성된 트리플렛을 구성합니다.
- 모델이 생성한 요약 문장과 정답 문장간의 거리인 d(Hp,Vpr)와 모델이 요약한 문장과 오답 문장의 거리 d(Hp,Vnr)를 계산합니다.
- 트리플렛 손실 함수는 d(Hp,Vpr)가 0에 수렴하도록, d(Hp,Vnr)는 1에 수렴하도록, 동시에 그 상대적인 거리 차(d(Hp,Vnr)-d(Hp,Vpr))가 임의로 정한 마진값보다는 커지도록 합니다.
결과적으로 P-SBERT와 요약 모델은 미세조정에 쓰이는 트리플렛 손실 함수값을 최소화하는 방향으로 훈련되는 거라 볼 수 있겠습니다. 정답 문장과 관련이 있는 문서와 그렇지 않은 문서를 S-BERT로 추출한 벡터로도 마찬가지의 학습을 진행합니다. 생성 요약모델과 SBERT를 함께 미세조정한 효과는 뒤의 성능 비교 실험 결과에서 이어서 설명하겠습니다.
2.문서와 정답 문장, 생성 문장 모두의 관계를 고려한 유사도 계산
RDASS는 <본문, 정답 요약 문장, 예측 요약 문장> 세 개의 관계를 동시에 고려하도록 고안됐습니다. RDASS도 0~1 사이의 숫자 값을 가지며 숫자가 높을수록 더 높은 성능을 가리킵니다. 계산 과정([그림 3])은 다음과 같습니다.
사전훈련과 미세조정을 모두 마친 버전인 FWA-SBERT를 이용해 문서(d), 정답 요약 문장(r), 모델이 생성한 요약 문장(p) 각각의 벡터 Vd, Vp, Vr를 추출합니다. 그런 뒤, < Vp, Vr >와 < Vp, Vd > 각각의 코사인 유사도cosine similarity10인 s(p, r), s(p, d)를 계산합니다. 마지막으로, 두 유사도의 평균값을 냅니다.
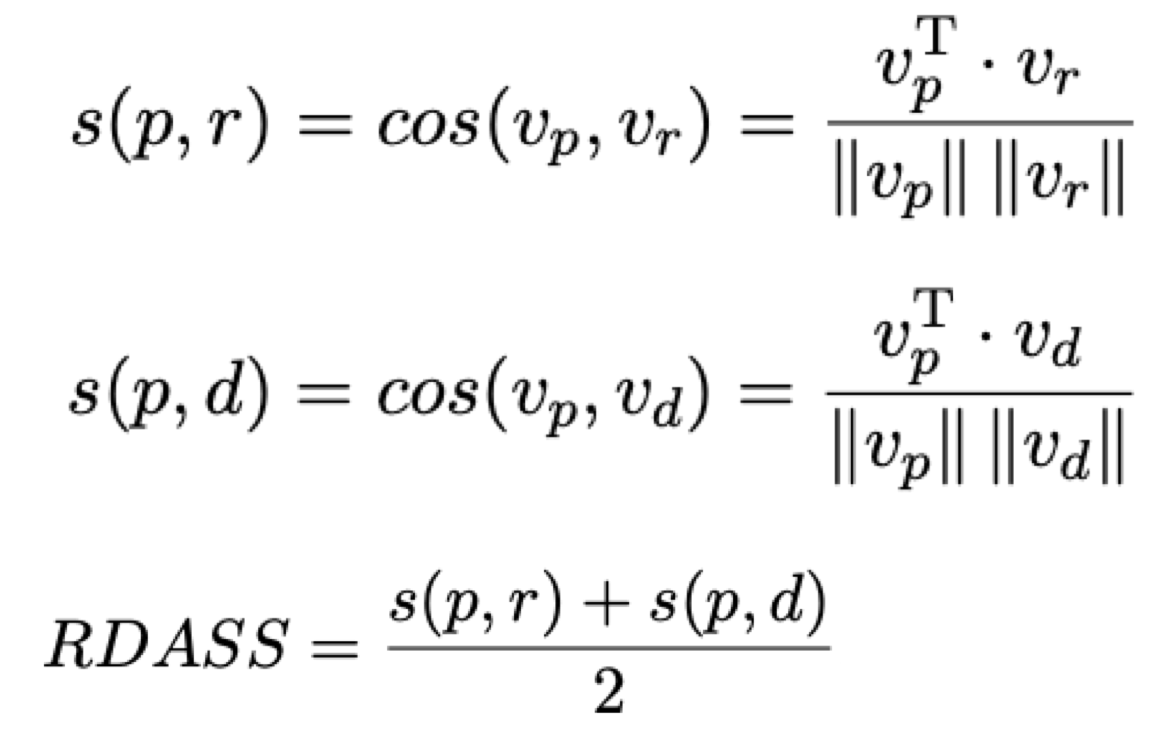
[ 그림 3 ] <본문, 정답 문장, 예측 문장> 세 개의 관계를 동시에 고려하는 평가 척도 RDASS의 계산 과정
실험 환경
공동 연구팀은 사전학습된 BERT를 인코더로, Transformer를 디코더로 구현하고 여러 태스크11에서 SOTA(현재 최고 수준의) 성능을 달성한 BERTSUMABS12를 생성 요약 모델로 사용했습니다.
문장 임베딩 모델로 채택한 SBERT의 훈련을 위해서는 BERT의 사전학습이 필요했습니다. SBERT가 BERT의 출력값을 활용하는 구조로 이뤄져 있기 때문이죠. 다만 한글 데이터셋으로 사전학습된 BERT를 시중에서 구할 수 없었던 공동 연구팀은 160만 개의 문서에서 추출한 2,300만 개 문장의 한국어 데이터셋으로 BERT를 직접 사전학습했습니다. 그러고 나서 카카오브레인에서 최근 공개한 한국어 NLI 및 STS 데이터셋[9]13으로 SBERT를 따로 사전훈련했습니다. P-SBERT의 미세조정과 검증에는 카카오엔터프라이즈가 자체 수집한 정치, 경제, 문화 등 10개 주제와 관련된 뉴스(문서)와 각 뉴스를 요약한 문장을 한 쌍으로 구성해 만든 300만 개의 병렬 데이터셋을 이용했습니다.
공동 연구팀은 <문서, 정답 요약 문장, 예측 요약 문장>으로 구성된 200개의 데이터를 대상으로 ROGUE와 RDASS의 평가 정확도를 비교하는 실험을 진행했습니다. 이들 평가 척도의 객관성을 확보하고자 사람 평가와 얼마나 상관성이 있는지도 측정했습니다. 사람 평가에서는 예측된 요약문이 본문과 얼마나 관련도가 높은지(relevance), 사실 정보에 입각하는지(consistency)14, 문장의 완성도가 높은지(fluency) 등 세 가지 항목을 두고, 모든 사람의 점수(1~5점) 평균값을 각 항목의 점수로 활용했습니다.
인간 평가와 자동 평가의 상관성correlation 측정에는 보편적인 기법인 피어슨Pearson 상관계수, 켄달Kendall (순위) 상관계수를 이용했습니다. 두 변수(RDASS, 사람 평가)의 상관관계를 수치로 계량화한 두 상관계수는 1일수록 양의 상관관계15를, -1일수록 음의 상관관계16를, 0이면 상관관계가 없음을 나타냅니다.
연구 결과
실험 결과, 공동 연구팀은 새롭게 제안한 평가 척도인 RDASS가 사람 평가와의 상관성이 ROGUE보다 더 크다는 점을 실험적으로 증명했습니다. 이는 RDASS가 요약 모델이 생성한 문장과 실제 정답 문장 간 유사성은 물론, 문서와의 유사성도 함께 파악한 구조 덕분으로 분석됩니다. 사람의 평가 결과와 유사한 품질의 평가 척도인지를 알기 위해서는 좀 더 추가적인 실험 진행되어야 할 거로 보입니다.
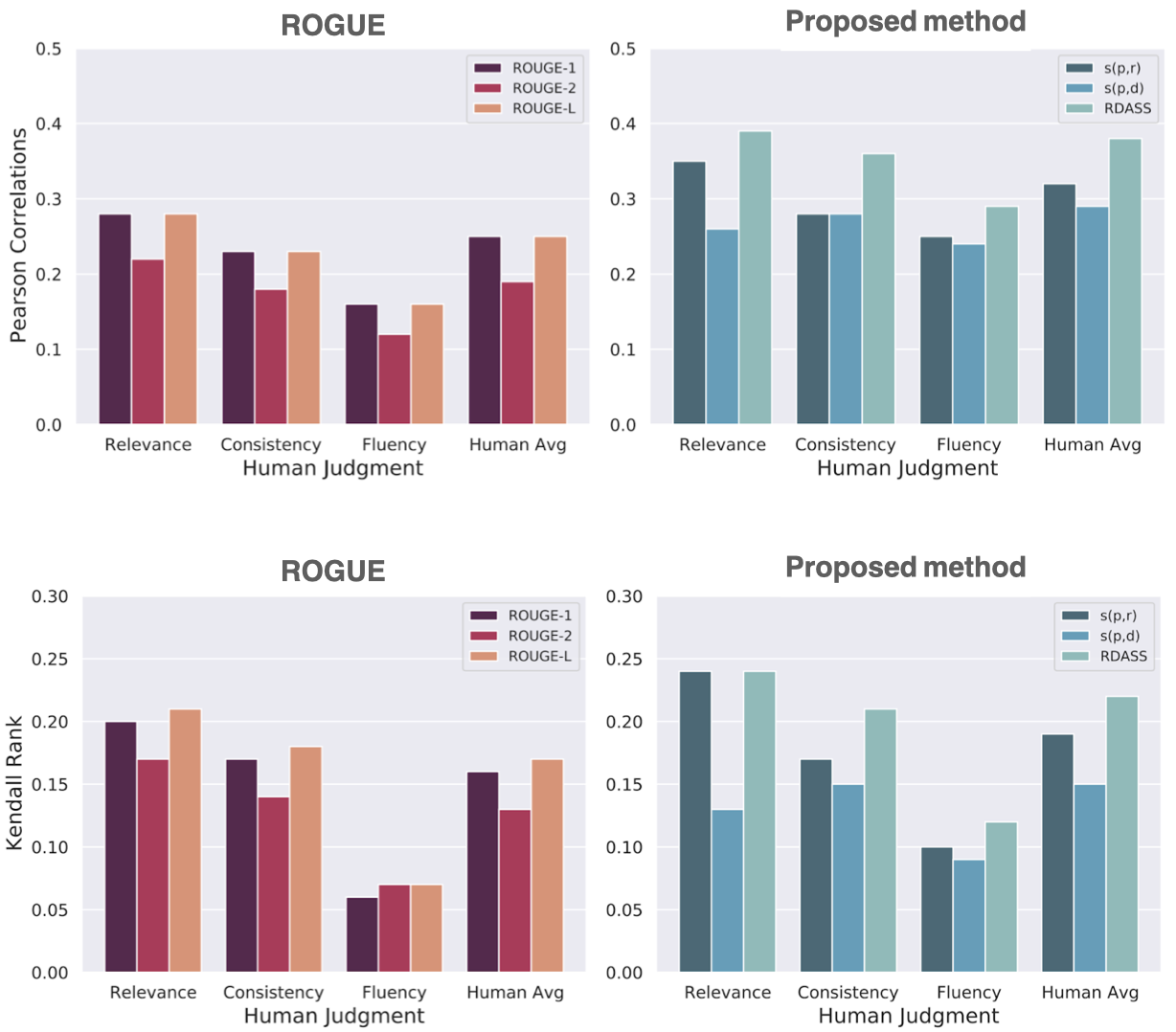
[ 그림 4 ] RDASS와 사람 평가 방식의 상관관계 측정
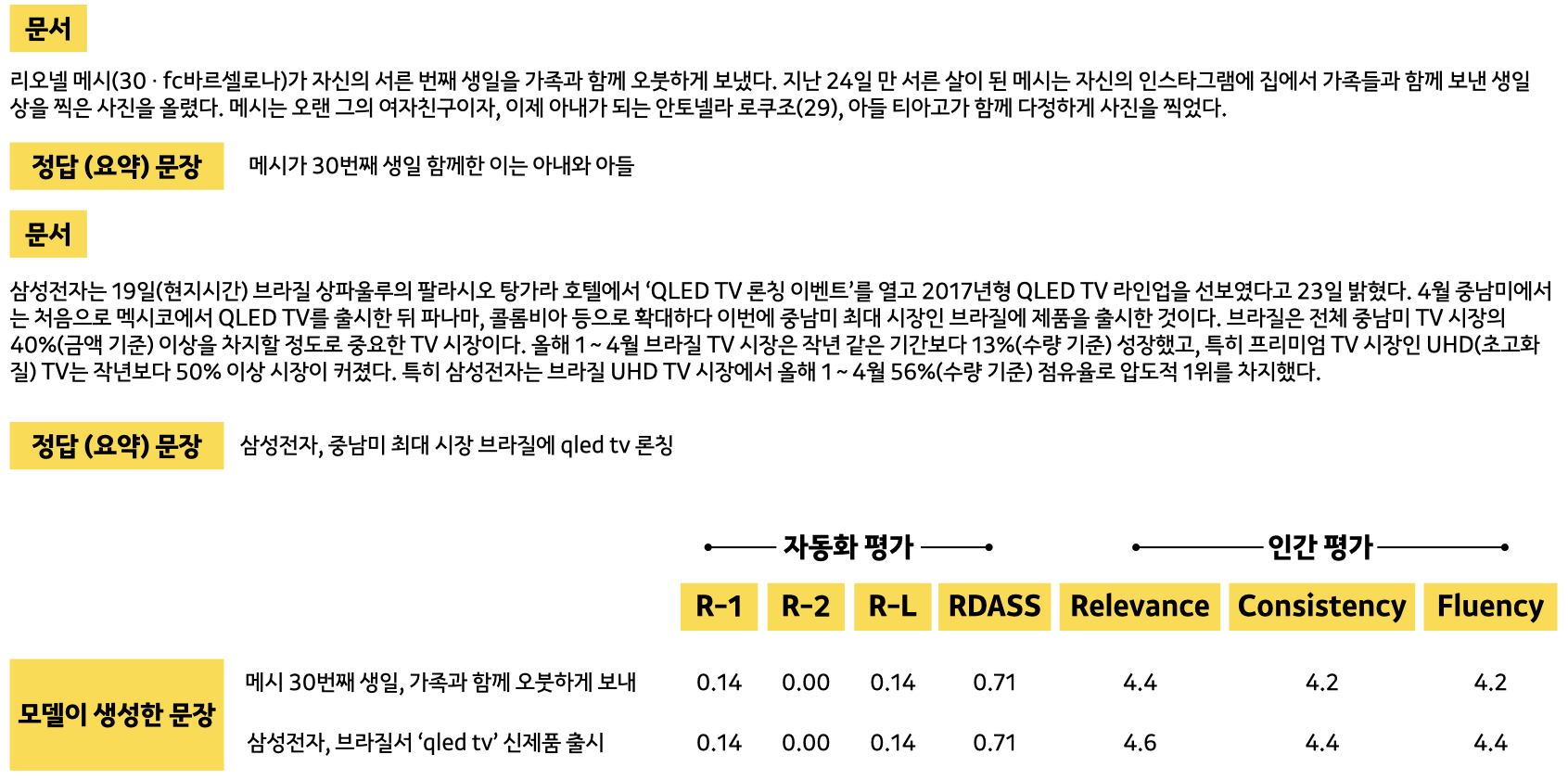
[ 그림 5 ] RDASS가 ROGUE보다 사람 평가와 상관성이 더 크다는 결과가 나왔다.
생성요약 모델과 SBERT를 함께 미세조정한 효과는 [표 1]에서 확인할 수 있습니다. P-SBERT만을 이용해 RDASS를 계산한 결과보다는, FWA-SBERT를 이용해 RDASS를 계산한 결과값이 사람 평가와 일치도가 더 높습니다.
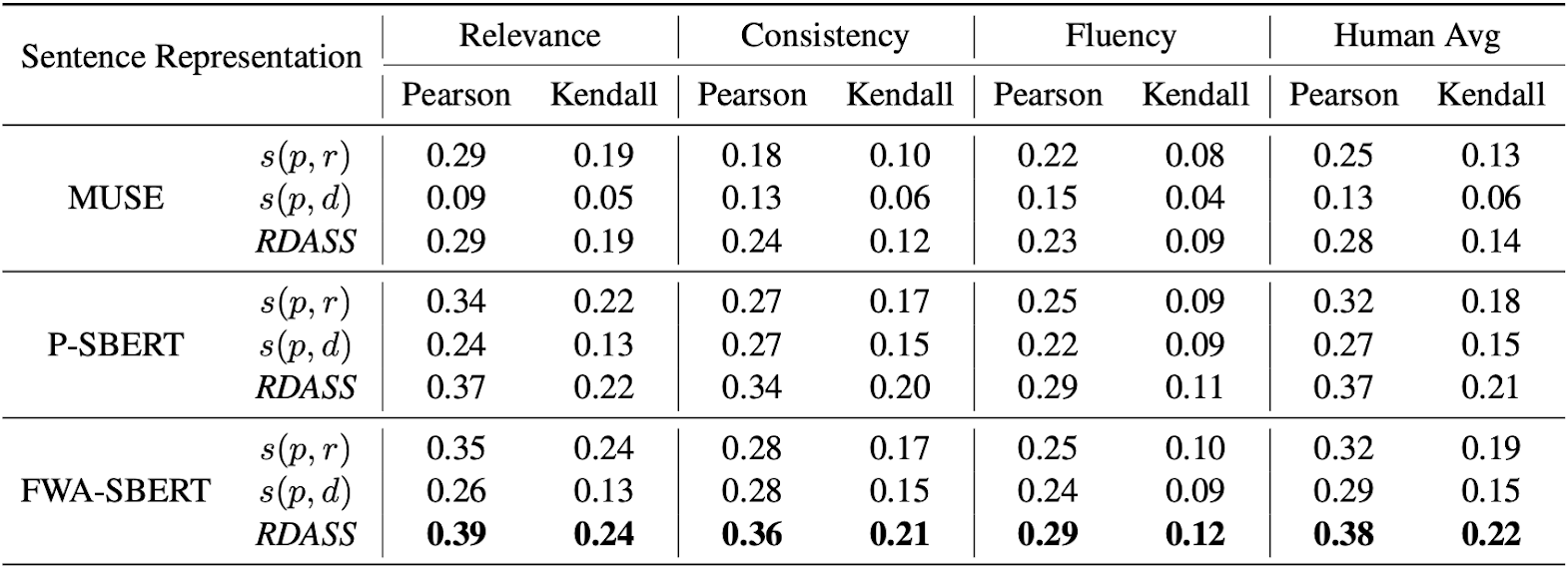
[ 표 1 ]생성요약 모델과 SBERT를 함께 미세조정하면 RDASS와 사람 평가의 일치도(유사성)가 상대적으로 더 높다.
향후 계획
요즘에는 기계가 생성한 요약문의 참 또는 거짓을 판단하는 요소를 반영하는 연구 분야에서 성과가 나고 있습니다17. 지문의 개체entity, 전치사 등의 항목에 오류를 주고 이를 복구하는 방법을 배우는 사후 교정 방식post-editing의 요약 교정 모델[10]과 모델이 예측한 요약문으로 질문지를 생성한 뒤 정답을 예측 요약문에서 찾은 점수와 본문에서 찾은 점수를 비교해서 생성된 요약문의 사실성을 판단하는 평가 척도[11]가 새롭게 제안되기도 했습니다. 공동 연구팀 또한 최근 연구 변화 흐름에 따라 참/거짓 오류를 줄여서 사실에 입각한 요약 문장을 생성하는 모델을 연구∙개발할 계획입니다.
이동엽 카카오 연구원은 “모델의 성능 평가 척도는 더 나은 요약 모델 개발에 매우 중요한 요소 중 하나”라며 “영어 텍스트 요약 태스크에서의 추가 검증 등 RDASS의 상대적 효용성을 입증하는 실험도 추가할 예정”이라고 말했습니다.
참고문헌
[1] 한국어 기술문서 분석을 위한 BERT 기반의 분류모델 (2020) by 황상흠, 김도현, in 한국전자거래학회지 제25권 제1호
[2] Reference and Document Aware Semantic Evaluation Methods for Korean Language Summarization (2020) by Dongyub Lee, Myeong Cheol Shin, Taesun Whang, Seungwoo Cho, Byeongil Ko, Daniel Lee, EungGyun Kim, Jaechoon Jo in COLING
[3] ROUGE: A Package for Automatic Evaluation of Summaries (2004) by Chin-Yew Lin in ACL
[4] ParaEval: Using Paraphrases to Evaluate Summaries Automatically (2006) by Liang Zhou, Chin-Yew Lin, Dragos Stefan Munteanu, Eduard Hovy in ACL
[5] Better Summarization Evaluation with Word Embeddings for ROUGE (2015) by Jun-Ping Ng, Viktoria Abrecht in ACL
[6] ROUGE 2.0: Updated and Improved Measures for Evaluation of Summarization Tasks (2018) by Kavita Ganesan in ACL
[7] GloVe: Global Vectors for Word Representation (2014) by Jeffrey Pennington, Richard Socher, Christopher D. Manning in EMNLP
[8] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (2019) by Nils Reimers, Iryna Gurevych in EMNLP
[9] KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding (2020) by Jiyeon Ham, Yo Joong Choe, Kyubyong Park, Ilji Choi, Hyungjoon Soh in EMNLP
[10] Factual Error Correction for Abstractive Summarization Models (2020) by Meng Cao, Yue Dong, Jiapeng Wu, Jackie Chi Kit Cheung in EMNLP
[11] Asking and Answering Questions to Evaluate the Factual Consistency of Summaries (2020) by Alex Wang, Kyunghyun Cho, Mike Lewis in ACL
[12] Text Summarization with Pretrained Encoders (2019) by Yang Liu, Mirella Lapata in EMNLP
각주
자연어처리 및 언어학을 대표하는 국제 학회로, 2020년에는 제출된 2,319편의 논문 중 644개의 논문이 통과됐다. ↩
문장을 특정 단위를 기준으로 N개씩 분할해서 얻은 결과물을 가리킨다. 이 단위는 형태소, 또는 어절(띄어쓰기 기준) 등이 될 수 있다. ↩
중심이 되는 의미를 갖춘 실질 형태소를 가리킨다. ↩
어근과 결합해 그 의미나 기능을 더해주는 형식 형태소를 가리킨다. 어근 앞에 붙으면 접두사, 어근 뒤에 붙으면 접미사라고 부른다. ↩
2014년 미국 스탠포드대학교 연구팀이 개발한 단어 임베딩 기법 ↩
Sentence-BERT 논문에서 “this common practice yields rather bad sentence embeddings, often worse than averaging GloVe embeddings.”라고 기술한 바 있다. ↩
주어진 두 문장의 관계를 '함의한다entailment', '모순적이다contradiction', '모른다neutral' 중 하나로 분류하는 태스크 ↩
주어진 두 문장의 의미의 유사 여부를 판별하는 태스크 ↩
<문서, 요약 문장>으로 구성된 N개의 데이터셋이 있다고 가정해보자. n(1~N)번째 데이터셋으로 미세조정한다고 했을 때, 임의의 오답 문장은 n번째 데이터셋을 제외한 임의의 데이터셋의 문장을 선택한다. ↩
두 문장의 벡터 유사도를 구하는 방법에는 유클리디언 거리euclidean distance와 코사인 유사도가 있다. 유클리디안 거리는 N차원의 공간에서 두 점의 직선 거리를 의미하며, 코사인 유사도는 두 벡터간의 사이각 계산 방법을 의미한다. ↩
Cable News Network/DailyMail, New York Times, XSum 데이터셋 기준 ↩
카카오 i 번역 엔진을 이용해 SBERT 훈련에 사용된 NLI 및 STS 데이터셋을 구성하는 영어 문장을 한국어 문장으로 번역했다. ↩
여기서 말하는 사실성은 문서에 서술된 내용을 의미한다. ↩
한쪽이 증가할 때 다른 한쪽도 증가함을 의미한다. ↩
한쪽이 증가할 때 다른 쪽은 감소함을 의미한다. ↩
문서 내용 또는 외부 지식을 이용해 그래프를 구축하고 이를 학습에 활용하는 연구도 진행되고 있다. ↩
만든이

|

|