COMPUTER VISION
Proxyless Neural Architecture Adaptation for Supervised Learning and Self-Supervised Learning
김도국(인하대학교), 이흥창(카카오엔터프라이즈)Learning Network Architecture during Training Workshop at AAAI
2022-02-28
Abstract
Recently, Neural Architecture Search (NAS) methods are introduced and show impressive performance on many benchmarks. Among those NAS studies, Neural Architecture Transformer (NAT) aims to adapt the given neural architecture to improve performance while maintaining computational costs. However, NAT lacks reproducibility and it requires an additional architecture adaptation process before network weight training. In this paper, we propose proxyless neural architecture adaptation that is reproducible and efficient. Our method can be applied to both supervised learning and self-supervised learning. The proposed method shows stable performance on various architectures. Extensive reproducibility experiments on two datasets, i.e., CIFAR-10 and Tiny Imagenet, present that the proposed method definitely outperforms NAT and be applicable to other models and datasets.
본 글에서는 카카오엔터프라이즈와 인하대 공동 연구팀이 연산 자원을 많이 사용하는 기존 NAS의 단점을 보완하고자, 새롭게 제안한 알고리즘에 대해 소개드리려고 합니다. 해당 연구 결과는 AAAI 2022 학회에서 Workshop으로 개최된 Learning Network Architecture during Training 을 통해 공개되었습니다.
1. NAS(Neural Architecture Search)의 등장
일반적으로 딥러닝에서 높은 성능을 얻기 위해서는 주어진 task와 데이터셋에 최적화된 모델 구조를 찾는 과정이 필요합니다. 이를 위해 사람이 직접 각 레이어와 필터 개수 등 여러 설정을 일일이 미세조정하고 설계하는 과정을 거치는데요. 최적화된 모델 구조는 각 task와 데이터셋에 따라 달라지기 때문에, 해당 구조의 성능은 실제 학습을 진행한 뒤 그 결과로만 판단할 수 있습니다.
바로 이러한 불편함을 개선하고자 등장한 연구 분야가 NAS(Neural Architecture Search) 입니다. NAS는 자동화를 통해 주어진 task에 최적화된 모델 구조를 편리하고 빠르게 탐색하는 방법론으로, 여러 벤치마크 데이터셋에서 눈에 띄는 우수한 연구성과들을 보이고 있습니다.
여기서 더 나아가, 최근에는 NAS의 이점은 유지하면서 연산비용을 줄인 여러 연구가 주목받고 있는데요. 그 중 하나로는, 기존에 방대한 아키텍처 후보군(Search Space)을 아주 작게 줄여서 최적의 아키텍처를 찾는 NAT(Neural Architecture Transformer) 방식이 있습니다. 하지만, NAT은 알고리즘의 재현성(reproducibility)이 떨어지고, 동일한 셀 아키텍처 구조 하에서만 탐색이 가능하다는 단점이 있는데요.
2. Proxyless Neural Architecture Adaption 방법론 소개
본 연구에서는 NAT의 단점을 개선한 Proxyless Neural Architecture Adaption 방법론을 새롭게 제안하였습니다.
이 방법론은 NAT과 비교해 재현성이 높고, 효율적이라는 점이 특징인데요. NAT에서는 추가적인 아키텍처 서치 과정이 필요하기 때문에 학습시간과 GPU 자원 소모가 큰데 반해, 본 방법론은 아키텍처 서치와 모델 학습을 동시에 진행하여 자원을 크게 절감할 수 있습니다.
또한, 하나의 셀(cell) 단위가 아닌 다양한 셀 아키텍처를 가진 매크로블록(macroblock) 기반 탐색으로 전체 범위를 탐색할 수도 있습니다. 이뿐만 아니라, 지도학습(Supervised Learning)과 자기지도학습(Self-Supervised Learning)에 모두 적용될 수 있어 활용도가 높은데요.

그림1. Proxyless Neural Architecture Adaption 방법론을 적용한 네트워크 아키텍처 검색 구조
3. 성능 비교
이 방법론의 성능과 광범위한 재현성을 검증하기 위해 CIFAR-10과 Tiny Imagenet 데이터셋에 여러가지 모델로 실험을 진행했습니다.
먼저 지도학습 환경에서 수작업으로 설계된 Resnet20과 MobilentV2, NAS 모델인 DARTS와 Proxyless NAS 모델을 활용하여 테스트를 진행하였습니다. 기존 방식과 NAT, 본 방법론으로 실험을 진행한 결과, [표1]과 같이 다양한 아키텍처에서 기존 방법론 대비 뛰어난 성능을 확인했습니다. 더불어 전체적인 연산비용 측면에서도 NAT과 비교해 더 적은 비용을 사용할 수 있었습니다.

표1. 지도학습에서의 평균 정확도, 표준편차, 연산시간 비교 (CIFAR-10 기준)
표2에서는 마찬가지로 CIFAR-10 데이터셋 상에서 5번의 무작위 시도를 거쳐 재현성을 테스트 진행하였고, 안정적인 성능을 확인할 수 있었습니다.
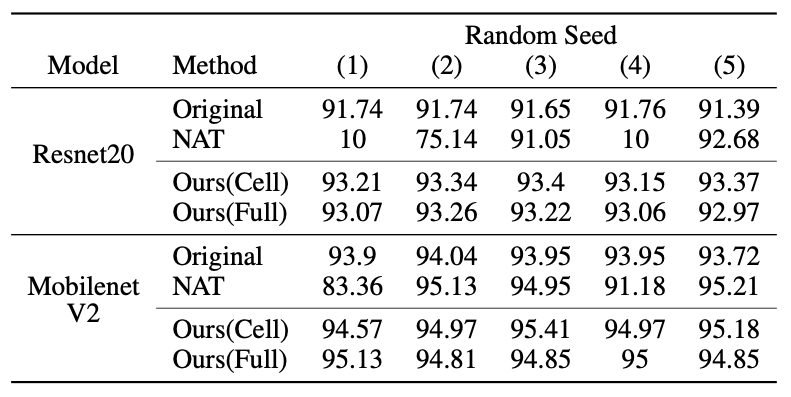
표2. 지도학습에서의 재현성 비교 (CIFAR-10 기준)

표3. 지도학습에서의 평균 정확도, 표준편차, 연산시간 비교 (Tiny Imagenet 기준)
또한, 자기지도학습 환경에서도 성능을 확인하기 위해 NAS모델인 DARTS와 Proxyless NAS에 추가적인 테스트를 진행하였고, 여기에서도 기존 방식 대비 우수한 성능을 확인하였습니다.
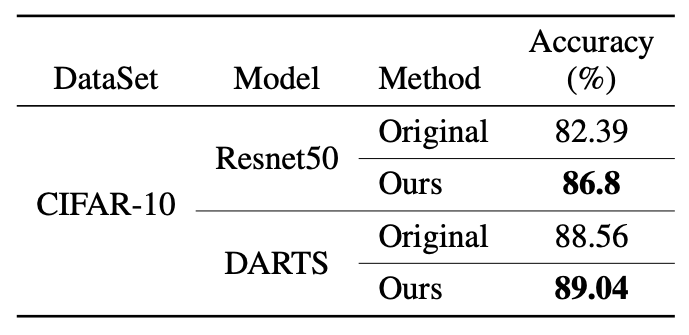
표4. 자기지도학습에서의 정확도 비교 (CIFAR-10 기준)
4. 향후 연구 계획
카카오엔터프라이즈 연구팀은 해당 방법론을 활용하여 정확도를 넘어, 결과가 도출되는 시간, 속도(latency)까지 고려한 모델을 만들고자 합니다. 특히 컴퓨터비전 분야 연구에 적용해 최적의 모델 구조를 빠르고, 저비용으로 탐색하는 데에 중점을 둘 계획입니다.
앞으로도 카카오엔터프라이즈의 AI 연구에 많은 관심 부탁드리며, 카카오엔터프라이즈 AI Lab & Service에 대해 궁금하시다면 아래 링크를 참고해주세요!
👨🏻💻 인재영입