NLP
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
이주성(카카오엔터프라이즈), 한기종(카카오엔터프라이즈)DSTC10 Wokrshop at AAAI
2022-02-28
Abstract
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask #1, #2 and the generation of subtask #4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask #1, #2 and a runner-up in the generation of subtask #4. The source code is available at https://github.com/rungjoo/simmc2.0.
카카오엔터프라이즈 연구팀은 지난해 10월 개최된 Situated Interactive MultiModal Conversations 2.0 (이하 SIMMC 2.0) 챌린지에 참여하여 subtask #1과 #2에서는 3위를, #4에서는 2위를 달성하는 성과를 거두었습니다. 본 논문을 통해 챌린지 참여 과정을 소개하고자 합니다.
1. 챌린지 소개
먼저 해당 챌린지에 대해 짧게 소개드리려고 합니다. 지난해 2회째를 맞은 SIMMC 2.0는 AI 대화 시스템 분야의 대표적인 국제 경진대회인 DSTC(Dialog State Tracking Challenge)10을 통해 개최되었습니다. 대회 주제는 바로, 멀티모달 데이터셋을 활용해 실생활에 쓰일 수 있는 어시스턴트(assistant) 모델을 만드는 것이었는데요. 주어진 데이터셋은 쇼핑 도메인에 특화된 목적지향 대화(task-oriented dialog) 데이터로 구성되어 있었고, 이 데이터셋을 활용해 사용자가 의류 또는 가구를 쇼핑하는 상황에서 AI 어시스턴트가 얼마나 대화 맥락에 적절한 응답을 생성하는지를 평가하는 과제들이 주어졌습니다.
2. 과제 소개
연구팀은 SIMMC 2.0에서 주어진 4가지 과제 중, subtask #1, #2와 #4에 참여하였습니다. 각 subtask마다 사용 가능한 데이터와 모델링에 있어 차이가 있었고, 학습과 테스트 과정에서 활용 가능한 데이터에서도 제한이 있었습니다. 특히 모든 테스트 과정에서 객체의 시각적 메타데이터, 라벨링된 사용자 정보, 대화에 언급된 모든 객체 리스트 정보는 사용할 수 없었는데요. 다만, 객체의 비시각적 메타데이터, 시스템 발화에서 언급된 객체 리스트, 대화에 해당하는 배경이미지, 모든 객체의 경계 박스(bounding box) 데이터는 모두 활용 가능했습니다. 참고로, 여기서 객체는 의류 도메인 상에서 의류 이미지에 해당됩니다.
좀 더 자세히 각 과제 내용을 살펴보면, #1 Multimodal Disambiguation은 배경 전체 이미지와 대화 맥락이 주어질 때, 이 상황에서 마지막 발화의 명확성을 판단(True/False)하는 과제입니다. 예를 들어 오른쪽 옷걸이에 파란색 옷 3가지가 걸려있다고 가정했을 때, 아래와 같은 방식으로 발화가 이루어진다면 어떤 옷을 가르키는지 명확히 알 수 없기 때문에 불명확함을 의미하는 False를 도출하게 됩니다.
- 발화1 : 파란색 옷이 어디 있나요?
- 발화2 : 저기 오른쪽 위에 있습니다.
다음으로 #2 Multimodal Coreference Resolution은 사용자의 발화에 언급된 객체를 찾는 과제로, #1 과제와 동일한 테스트 데이터 사용이 가능했습니다. 이어 #4 Multimodal Dialog Response Generation & Retrieval에서는 사용자 발화에 적절한 시스템 응답을 생성하거나 검색하는 과제였습니다.
3. 과제 해결과정
연구팀은 과제 해결을 위해, 기존 텍스트 기반의 BERT와 GPT2에서 더 나아간 멀티모달 모델을 새롭게 고안하였습니다. 멀티모달 데이터셋은 이미지와 텍스트 정보를 모두 포함하고 있어, 텍스트로만 구성된 데이터셋보다 어려운 문제로 볼 수 있는데요. 이미지와 텍스트 간의 관계를 미리 이해할 수 있도록 멀티모달 사전학습(pre-training) 과정을 거쳤습니다. 사전학습에는 그림1과 같이 총 2가지 모델이 사용되었습니다. 하나는 객체 이미지와 텍스트 설명(description)이 일치하는지 판단하는 모델(ITM)이었고, 다른 하나는 배경 이미지와 대화 맥락(context)이 일치하는지 판단하는 모델(BTM)이었습니다. 두 가지 모델을 결합한 뒤 이를 각 태스크에 맞춰 미세 조정하는 방식으로, 하나의 멀티모달 모델을 사용해 전체 과제를 해결하였습니다.
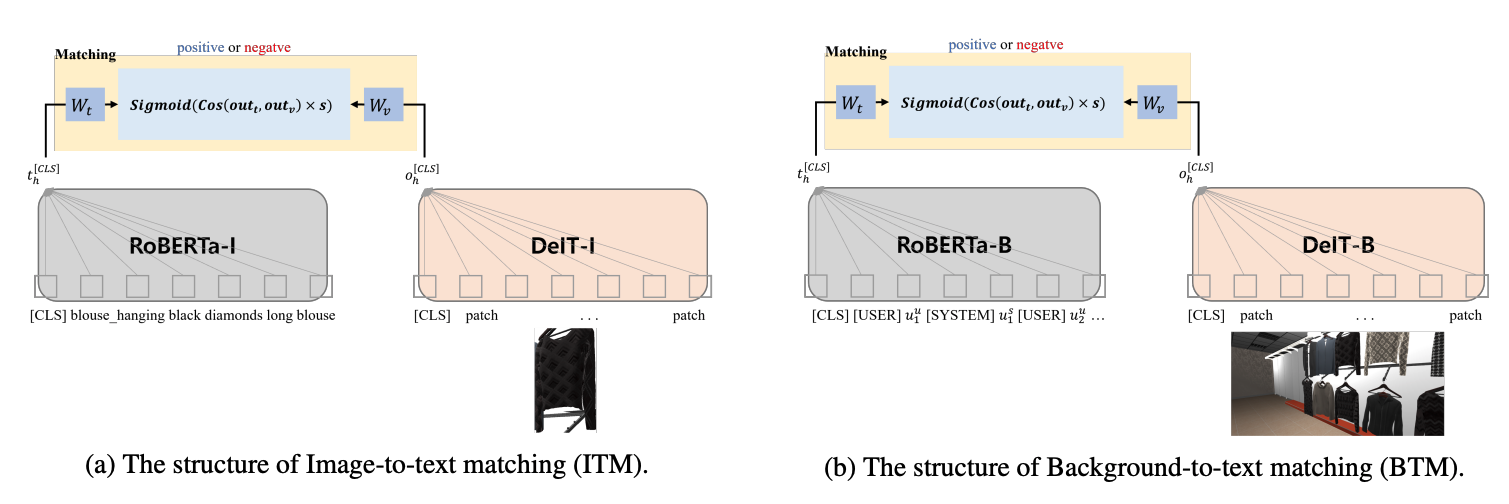
그림1. 멀티모달 사전학습 과정
전체적인 모델 구조는 그림2와 같은데요. 앞서 그림1에서 사전학습된 모델들을 모듈화해 전체 태스크에서 사용하였습니다.
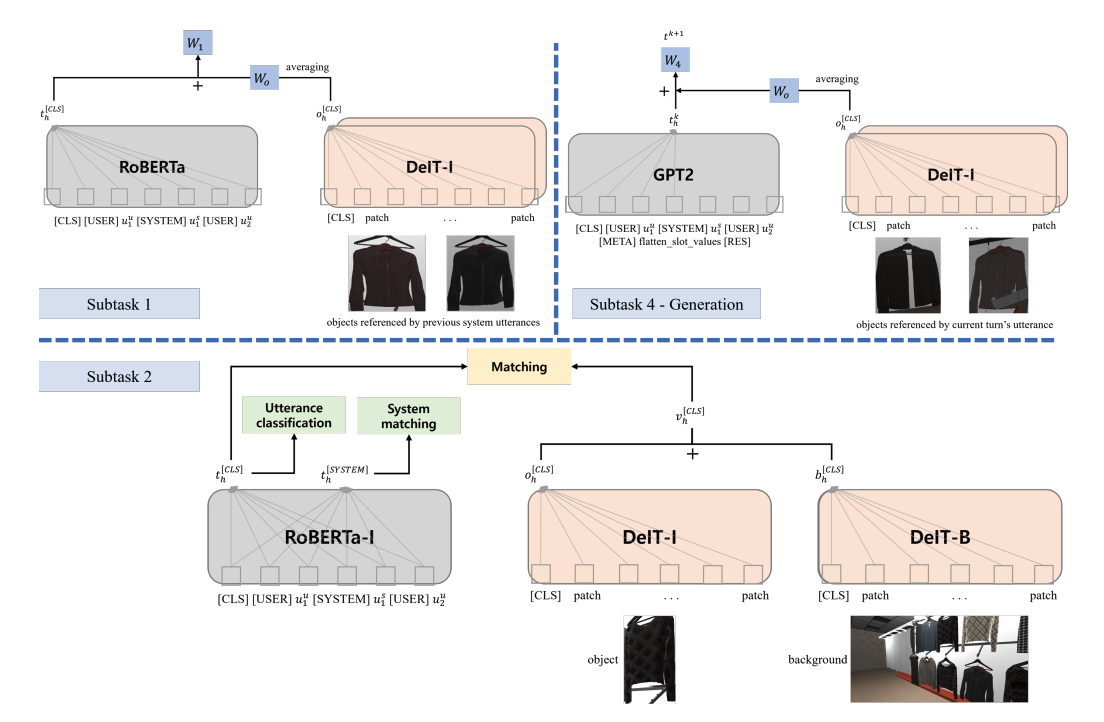
그림2. 전체 모델 구조
각 구조를 살펴보면 subtask #1에서는 발화의 명확성을 판단하기 위해 전체 컨텍스트가 담긴 멀티모달 사전학습이 되지 않은 RoBERTa에 사전학습된 DeIT-I을 사용하여 주어진 이미지에서 의류 형태만 크롭한 후, 객체 설명과 일치하는지를 판단하였습니다.
subtask #2에서는 #1과 데이터는 동일하게 사용하였지만, 사용자의 발화에 언급된 객체를 찾기 위해 대화맥락, 객체, 배경 정보를 모두 활용하는 구조를 사용했습니다. 먼저 context feature를 추출하기 위해, 그림3과 같은 구조 하에 두 가지 멀티태스크 러닝을 추가로 수행하였습니다. 1단계(utterance classification)에서는 매칭 판단에 유의미하지 않은 발화를 제거하기 위해 발화와 객체의 일치성을 판단하고, 2단계(system matching)에서는 이 객체를 이전 시스템 발화에 해당하는 object_ids에 매칭하였습니다. 여기서 모델이 학습하는 데이터에 따라 추론과정도 조금 달라지게 되는데요. 학습 데이터로 어떤 mention_objects를 사용하냐에 따라 모델의 강점이 달라집니다. 이에 따라 이전 발화에 언급됐던 related objects는 1 또는 matching으로, 관련이 없는 unrelated objects는 0으로, 이외 나머지를 의미하는 others는 0 또는 matching으로 결과값을 도출합니다.
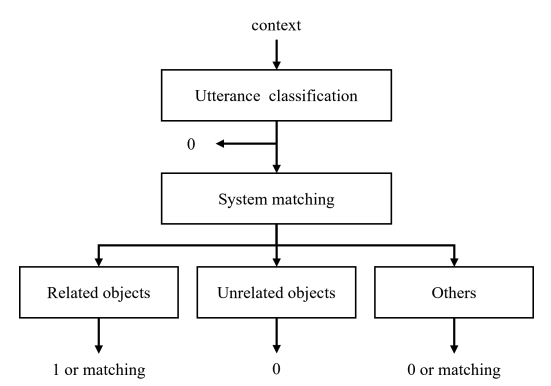
그림3. 주어진 발화에서 객체의 포함여부를 판단하는 로직 (two multi-task learning)
예를 들어 그림4와 같이 유저와 시스템의 발화쌍이 있다면, 시스템 1과 시스템 2의 system matching 여부를 판단하는 건데요. Case1에서는 “파란색 옷”으로 일치하기 때문에 1이, Case2에서는 “검은색과 빨간색 바지”, “파란색 옷”으로 일치하지 않기 때문에 0이 도출됩니다.
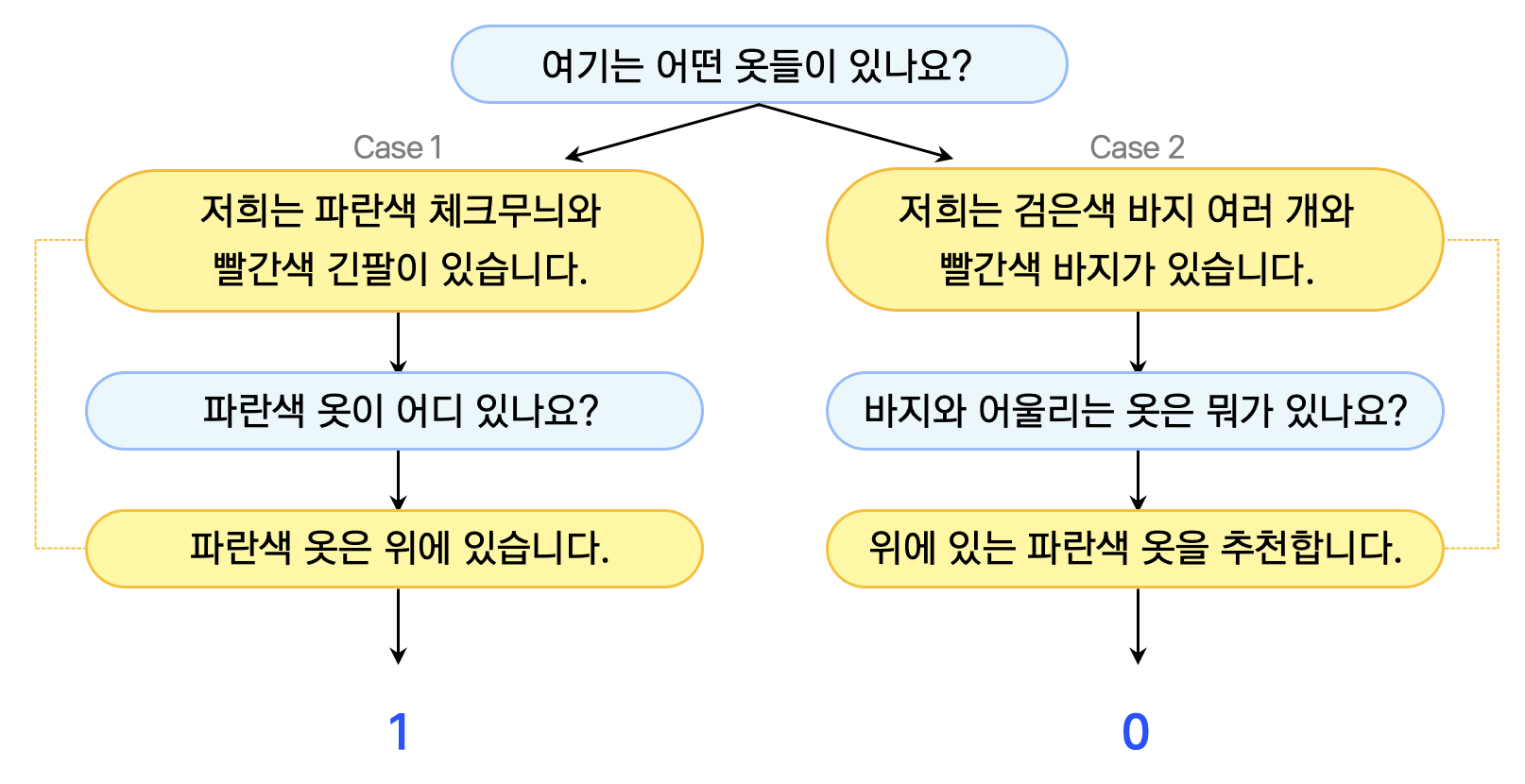
그림4. 그림3의 로직 판단 예시 (유저 발화:파란색, 시스템 발화:노란색)
이처럼 대화 특성상 앞서 언급된 단어가 뒤에도 동일하게 언급될 가능성이 높기 때문에, 최종적으로 system matching이 1로 판별된 시스템 발화의 objects만을 사용하여 객체의 후보군을 축소시키고자 하였습니다. 여기서 이 정보에 object feature와 background feature를 추출하는 DeIT-I와 DeIT-B 값을 매칭해 최종적으로 발화에 언급된 객체를 판단할 수 있었습니다.
마지막으로, 사용자 발화에 적절한 시스템 응답을 생성하거나 검색하는 subtask #4에서는 응답 생성만을 진행하였습니다. 여기서는 텍스트 모델로 GPT2-Large를 활용하여 전체 발화를 입력하였고, 시스템이 말할 다음 발화에 해당하는 이미지 정보(slot values)는 DeIT-I를 사용하여 object feature를 추출해 활용하였습니다. 다른 태스크와 달리, 이번 태스크에서는 현재 순서에 대한 주석 정보(system_transcript_annnotated)를 사용할 수 있었습니다.
4. 챌린지 성과 소개
학습에는 hugingface library를 사용하였고, 결과값은 아래 표와 같습니다. 전반적으로 베이스모델인 GPT2 대비 우수한 성능을 보였으며, 그결과 최종적으로 subtask #1, #2에서 각각 3위, #4 생성 분야에서는 준우승을 기록했습니다.
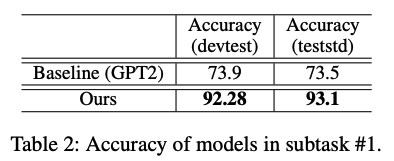
표1. subtask #1 성능 비교
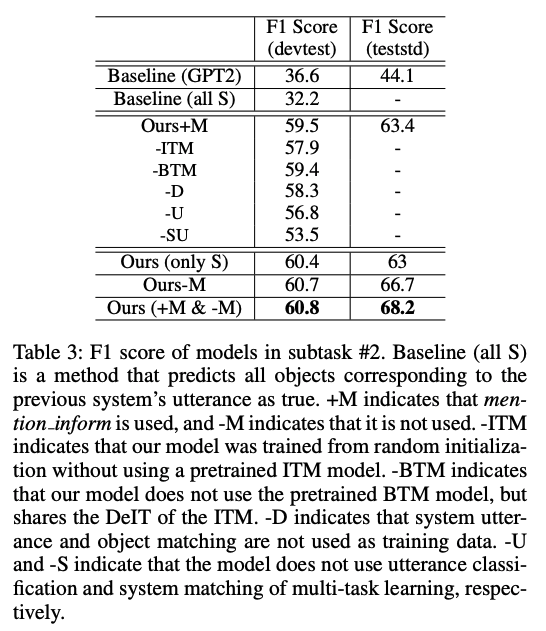
표2. subtask #2 성능 비교
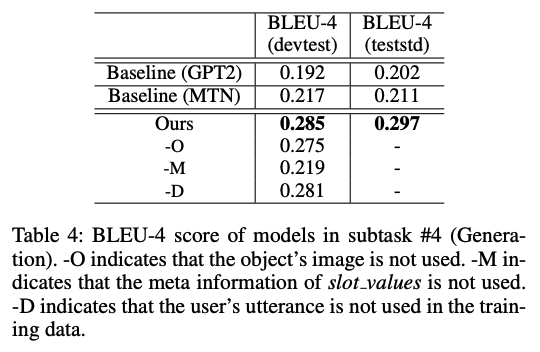
표3. subtask #4 성능 비교
5. 마치며
챌린지에 참여한 상세한 소스 코드는 깃허브를 통해 확인하실 수 있습니다. 앞으로 카카오엔터프라이즈 연구팀은 보다 사람같은 챗봇 서비스 구현을 위해, 이번 연구결과를 적극 활용할 계획입니다.
카카오엔터프라이즈의 AI 연구에 많은 관심 부탁드리며, 스몰톡 챗봇 ‘외개인아가’와 카카오엔터프라이즈 연구팀에 대해 궁금하시다면 아래 링크를 참고해주세요!
👨🏻💻 인재영입