NLP
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
황태선(고려대학교), 이동엽(카카오), 오동석(고려대학교), 이찬희(고려대학교), 한기종(카카오엔터프라이즈), 이동훈(카카오엔터프라이즈), 이새벽(Wisenut Inc/고려대학교)Association for Advancement of AI (AAAI)
2021-02-02
응답 선택response selection은 다자 간의 대화multi-turn dialog를 보고 후보 문장 중 맥락에 가장 어울리는 문장을 선택하는 태스크를 가리킵니다. 최근에는 BERT, RoBERTa, ELECTRA와 같은 대규모 말뭉치를 사전학습한 언어 모델language model을 이용해 관련 벤치마크 테스트에서 눈에 띄는 성능 향상이 이뤄졌습니다.
최신 언어 모델 기반한 응답 선택 모델은 대화와 응답 후보군을 입력받으면, 후보 문장의 적정성 여부를 이진 분류binary classification1한 결과를 내놓습니다. 공동 연구팀은 의미적 유사도를 기반으로 점수를 내는 언어 모델의 특성상, 응답으로 적절하지 않은 문장에 정답보다 더 높은 점수를 부여하는 경향성을 보이는 기존 방식의 한계를 지적했습니다. 이는 기존의 손실 함수loss function가 발화utterance2 간 연관성coherence을 충분히 표현하지 못해서 생기는 거로 분석됩니다.
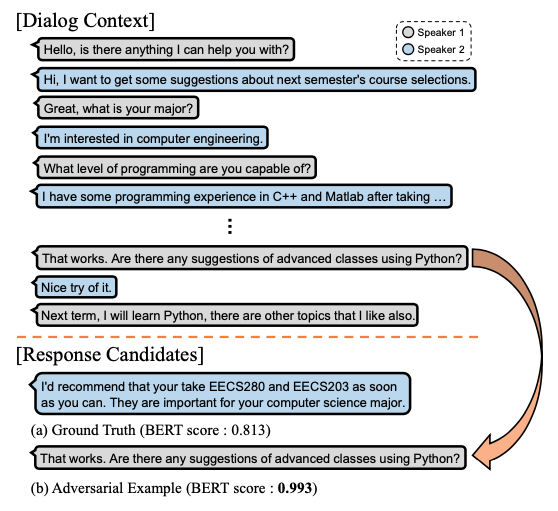
[ 그림 1 ] LM에 기반한 최신의 응답 선택 모델은 대화의 맥락에 호응하지 않음에도 불구, 의미적 유사도가 높은 문장 b에 더 높은 점수를 부여하고 있다.
공동 연구팀은 기존의 한계를 극복하고자 UMSUtterance Manipulation Strategies를 제안했습니다. 이 기법은 대화에서 특정 발화가 어느 위치에 삽입돼야 하는지(insertion), 현재 대화 흐름에서 어떤 발화가 올바르지 않은지(deletion), 특정 발화의 바로 이전 발화의 위치가 어딘지(search)를 배우는 3가지 태스크로 구성됩니다. 자가지도학습self-supervised learning3이라 사람이 따로 라벨링 작업을 할 필요가 없고, 기존의 응답 선택 모델을 따로 조정할 필요 없이 미세조정fine-tuning단계에서 합동 훈련joint-training을 진행하면 됩니다4.
실험 결과, UMS를 적용한 응답 선택 모델은 대화 일관성을 효과적으로 학습하며, 여러 언어의 벤치마크benchmark에서 기존 성능을 크게 넘어섰습니다.
카카오엔터프라이즈는 대화의 맥락에 호응하는 응답을 선택하는 모델의 강건성을 향상하는 연구를 계속 진행할 계획입니다.
Overall Architecture
Figure 1 describes the overview of our proposed method, utterance manipulation strategies. We propose a multi-task learning framework, which consists of three highly effective auxiliary tasks for multi-turn response selection, utterance 1) insertion, 2) deletion, and 3) search. These tasks are jointly trained with the response selection model during the fine-tuning period. To train the auxiliary tasks, we add new special tokens, [INS], [DEL], and [SRCH] for the utterance insertion, deletion, and search tasks, respectively.
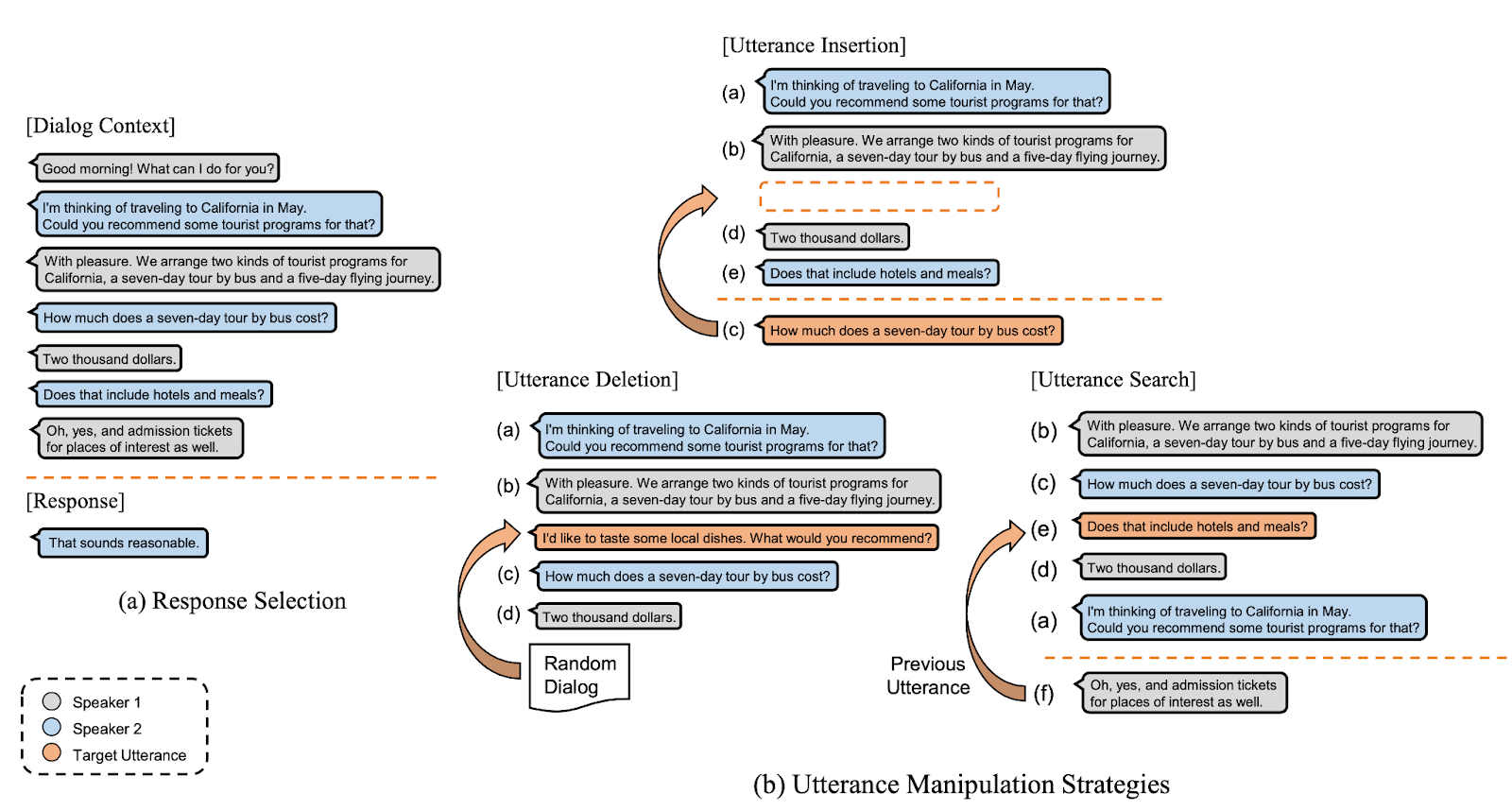
[ Figure 1 ] An overview of Utterance Manipulation Strategies. Input sequence for each manipulation strategy is dynamically constructed by extracting k consecutive utterances from the original dialog context during the training period. Also, target utterance is randomly chosen from either the dialog context (Insertion, Search) or the random dialog (Deletion).
Experiments
We obtained new state-of-the-art results on multiple public benchmark datasets (i.e., Ubuntu, Douban, and E-Commerce) and significantly improved results on Korean open-domain dialog corpus.
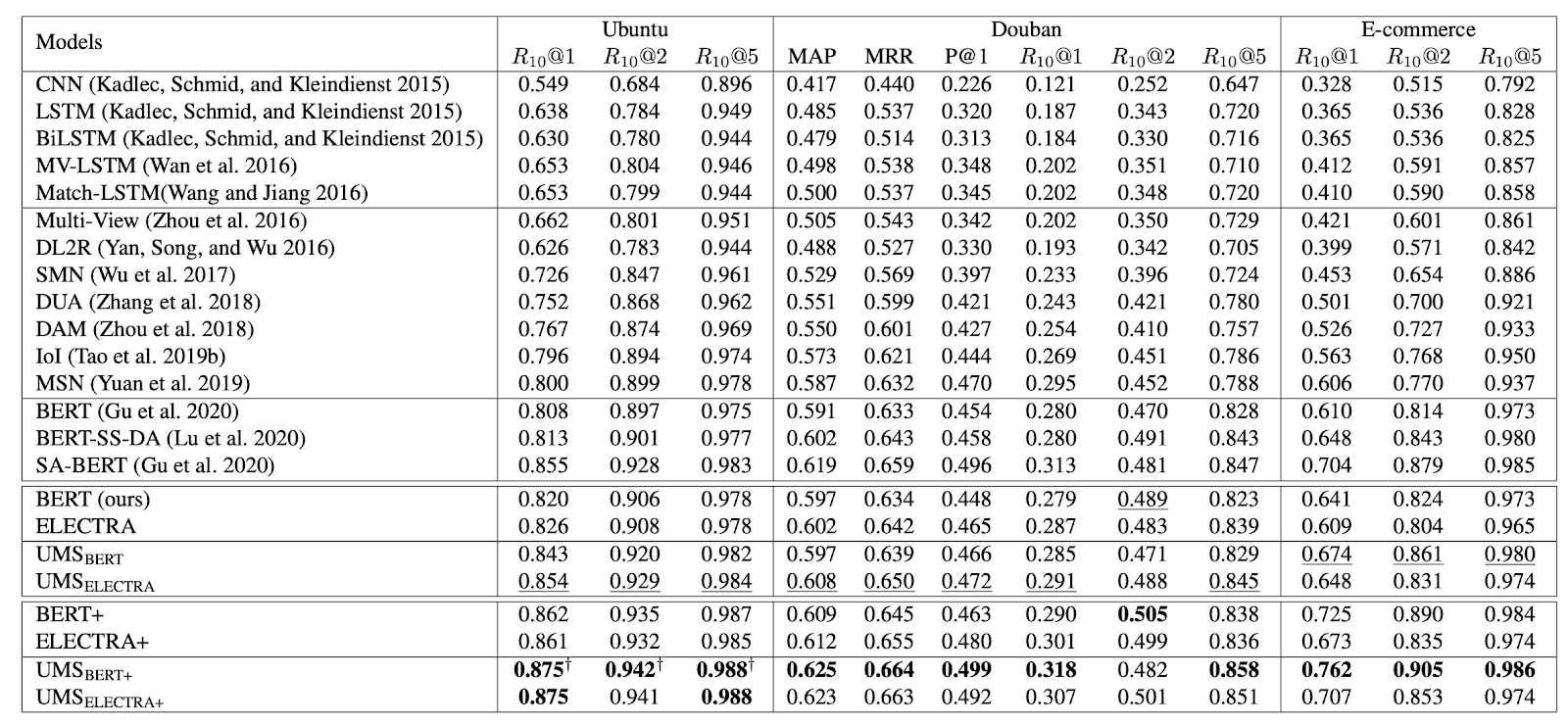
[ Table 2 ] Results on Ubuntu, Douban, and E-Commerce datasets. All the evaluation results except ours are cited from published literature (Tao et al. 2019b; Yuan et al. 2019; Gu et al. 2020). The underlined numbers mean the best performance for each block and the bold numbers mean state-of-the-art performance for each metric. † denotes statistical significance (p-value < 0.05).
Footnotes
-
이진 분류 과정은 다음과 같다. (1) 비선형 활성 함수activation function인 시그모이드sigmoid를 이용해 점수를 산출한다(eg., 0번(올바른 응답) 클래스: 0.87, 1번(올바르지 않은 응답) 클래스: 0.6). (2) 각 클래스 점수값 중 큰 쪽을 선택하는 이진분류를 수행한다. ↩
-
대화 속에서 주고 받는 말의 단위 ↩
-
비라벨링 데이터만 주어진 상태에서 입력 데이터 일부를 라벨로 사용하거나, 사전 지식에 따라 라벨을 스스로 만들어 모델을 훈련하는 방식 ↩
-
공동 연구팀이 제안한 방법은 4개의 손실값(response selection loss + insertion loss + deletion loss + search loss Loss)을 최소화하는 가중치weight 탐색을 목표로 학습을 진행한다. ↩