COMPUTER VISION
Deep Metric Learning with Multi-Objective Functions
이주영(카카오엔터프라이즈), 노명철(카카오엔터프라이즈)CVPR workshop on Computer Vision for Fashion, Art and Design (CVFAD)
2020-06-14
올해로 3번째 열린 CVPR 워크숍 CVFAD에서는 패션, 예술, 디자인 등의 창의성이 요구되는 분야에 필요한 생성 모델generative models, 검색retrieval, 제품 추천product recommendation, 이미지 분할image segmentation, 속성 인식attribute discovery, 트렌드 예측trend forecast 등에 관한 최신의 컴퓨터 비전과 머신러닝 방법론을 다룹니다.
카카오엔터프라이즈는 패션 이미지를 효율적으로 검색하는 거리 학습metric learning 방법론을 제안했습니다. 기존의 페어pair/트리플렛triplet 기반 손실 함수와 프록시proxy 기반 손실 함수를 동시에 훈련하면서도, 이 과정에서 발생하는 샘플링sampling과 초매개변수hyperparameter 문제를 해결했습니다. 제안된 방법은 In-Shop Clothes Retrieval 데이터셋에서 현재 최고 수준의(SOTA) 추론 성능을 냈습니다.
카카오엔터프라이즈는 이번 연구로 얻은 기술력과 경험을 바탕으로 카카오 i의 시각 엔진과 딥러닝 기반 유사 스타일 추천 기술을 고도화할 계획입니다.
Abstract
Metric learning is a very important process for the efficient fashion image retrieval and, in the metric learning, one of the most important issues is the selection of which objective functions. Efficient object functions in the previous work are pair/triplet based loss and proxy based one. Two types of objective functions have disadvantages that are opposed to each advantage. The loss functions have their own strengths, but their strengths oppose each other. To overcome the disadvantages, we propose a method that can simultaneously train the multi-objective functions. We achieve the new state-of-the art performance on In-Shop Clothes Retrieval dataset.
Overall Architecture
The proposed method explicitly considered the three types of distances (or similarities), each of which corresponds to three types of objective functions are defined as: 1) pairwise loss function optimized using embeddings of given samples, 2) proxy-based loss function used the similarity between proxies and embeddings of given samples, and 3) loss function minimized the similarity between proxies, respectively. Since each loss function has a different amount of contribution to optimize the method, we analyze the contribution and propose a combination method considering this. Finally, because the existing sampling strategies are mainly based on a single anchor, the sampling strategies are impossible to consider each relation of an anchor and a proxy together. We also propose a sampling strategy to consider two types of relations, at the same time.
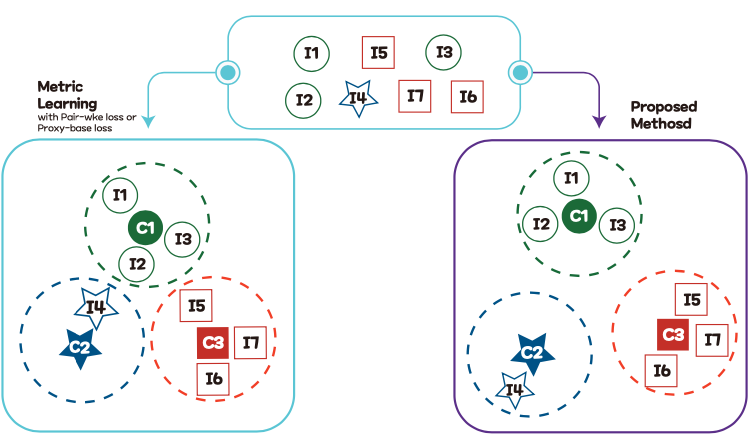
[ Figure 1 ] Comparison with the previous and our method
Experiments
We now compare the proposed method to other state-of-the art methods on In-shop Clothes Retrieval dataset. As shown in Table 1, the proposed method improves Recall@1 by 0.4%p, it is achieved to the new state-of-the art performance.
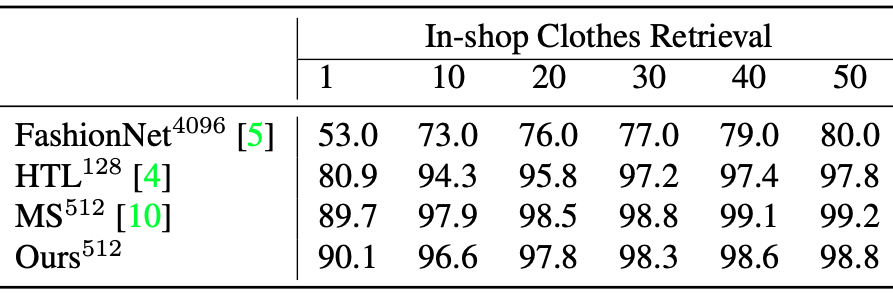
[ Table 1 ] Retrieval performance (Recall@K, %). Superscripts denote embedding size.