COMPUTER VISION
GroupFace: Learning Latent Groups and Constructing Group-based Representations for Face Recognition
김용현(카카오엔터프라이즈), 박원표(카카오), 노명철(카카오엔터프라이즈), 신종주(카카오엔터프라이즈)Computer Vision and Pattern Recognition (CVPR)
2020-06-14
공동 연구팀은 얼굴 인식에 전문화된 새로운 아키텍처인 GroupFace를 제안했습니다. GroupFace는 얼굴의 유사성을 그룹화해 표현하는 여러 개의 특징 벡터group-aware representation를 적용해 모델의 표현력을 높였습니다. 사람의 개입 없이도 각 그룹에 속하는 샘플 수의 균형을 맞추는 기법Self-distributed Label도 적용했습니다.
공동 연구팀이 1:1 얼굴 검증과 1:N 얼굴 인식 작업에서 최소한의 추가 연산만으로 여러 데이터셋에 대해 현재 최고 수준의(SOTA) 성능을 얻을 수 있었습니다.
카카오엔터프라이즈는 이번 연구로 얻은 기술력과 경험을 바탕으로 자사 얼굴 인식 기술을 고도화할 계획입니다.
☛ Tech Ground 데모 페이지 바로 가기 : 얼굴 검출 데모
Abstract
In the field of face recognition, a model learns to distinguish millions of face images with fewer dimensional embedding features, and such vast information may not be properly encoded in the conventional model with a single branch. We propose a novel face-recognition-specialized architecture called GroupFace that utilizes multiple group-aware representations, simultaneously, to improve the quality of the embedding feature. The proposed method provides self-distributed labels that balance the number of samples belonging to each group without additional human annotations, and learns the group-aware representations that can narrow down the search space of the target identity. We prove the effectiveness of the proposed method by showing extensive ablation studies and visualizations. All the components of the proposed method can be trained in an end-to-end manner with a marginal increase of computational complexity. Finally, the proposed method achieves the state-of-the-art results with significant improvements in 1:1 face verification and 1:N face identification tasks on the following public datasets: LFW, YTF, CALFW, CPLFW, CFP, AgeDB-30, MegaFace, IJB-B and IJB-C.
Overall Architecture
We introduce a new face recognition-specialized architecture that integrates the group-aware representations into the embedding feature and provides well-distributed group-labels to improve the quality of feature representation.
The rationale behind the effectiveness of GroupFace can summarize in two main ways:
(1) It is well known that additional supervisions from different objectives can bring an improvement of the given task by sharing a network for feature extraction, e.g., a segmentation head can improve accuracy in object detection. Likewise, learning the groups can be a helpful cue to train a more generalized feature extractor for face recognition.
(2) GroupFace proposes a novel structure that fuses instance-based representation and group-based representation, which is empirically proved its effectiveness.
Our GroupFace can be applied to many existing face recognition methods to obtain a significant improvement with a marginal increase in the resources. Especially, a hard-ensemble version of GroupFace can achieve high recognition-accuracy by adaptively using only a few additional convolutions.
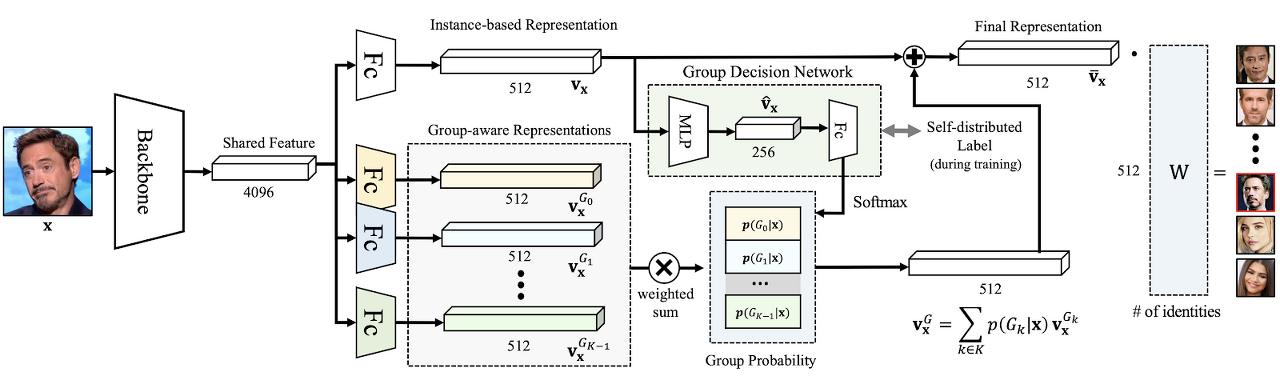
[ Figure 1 ] GroupFace generates a shared feature of 4096 dimension and deploys a fully-connected layer for an instance-based representation \(\mathbf{v}_{\mathbf{x}}\) and \(K\) fully-connected layers for group-aware representations \(\mathbf{v}_{\mathbf{x}}^{{G}}\) for a given sample \(\mathbf{x}\). A group-decision-network, which is supervised by the self-distributed labeling, outputs a set of group probabilities \(\left\{ p(G_0\vert\mathbf{x}), p(G_1\vert\mathbf{x}), ..., p(G_{K-1}\vert\mathbf{x}) \right\}\) from the instance-based representation. The final representation of 512 dimension is an aggregation of the instance-based representation and the weighted sum \(\mathbf{v}_{\mathbf{x}}^{{G}}\) of the group-aware representations with the group probabilities. W is a weight of the function \(g\).
Experiments
To show the effectiveness of our GroupFace, we evaluate the proposed method on various public datasets and achieve the state-of-the-arts accuracy on all of the datasets. We also perform the extensive ablation studies on the it’s behaviors.
1. Experimental Results

[ Table 1 ] Evaluation on LFW, YTF, CALFW, CPLFW, CFP-FP, AgeDB-30 and MegaFace
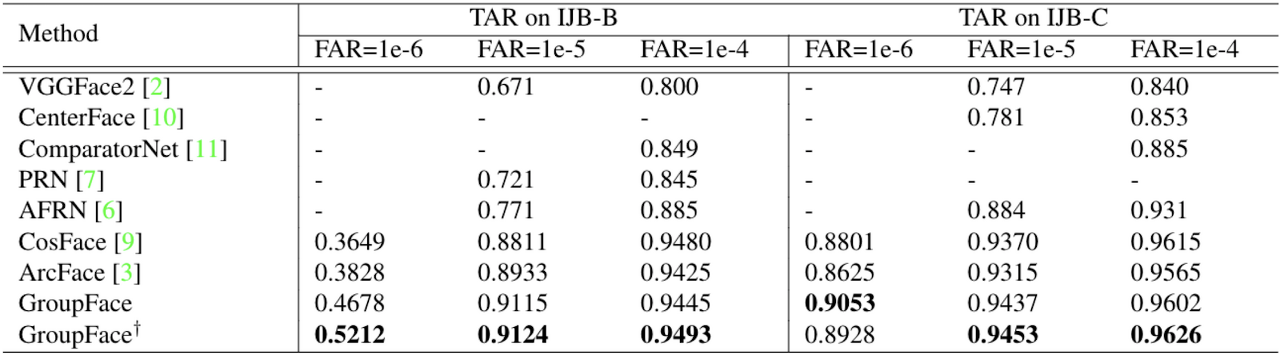
[ Table 2 ] Evaluation according to different FARs on IJB-B and IJB-C. Our GroupFace is trained by ArcFace. † denotes that a model is evaluated by using the group-aware similarity.
2. Ablation Studies
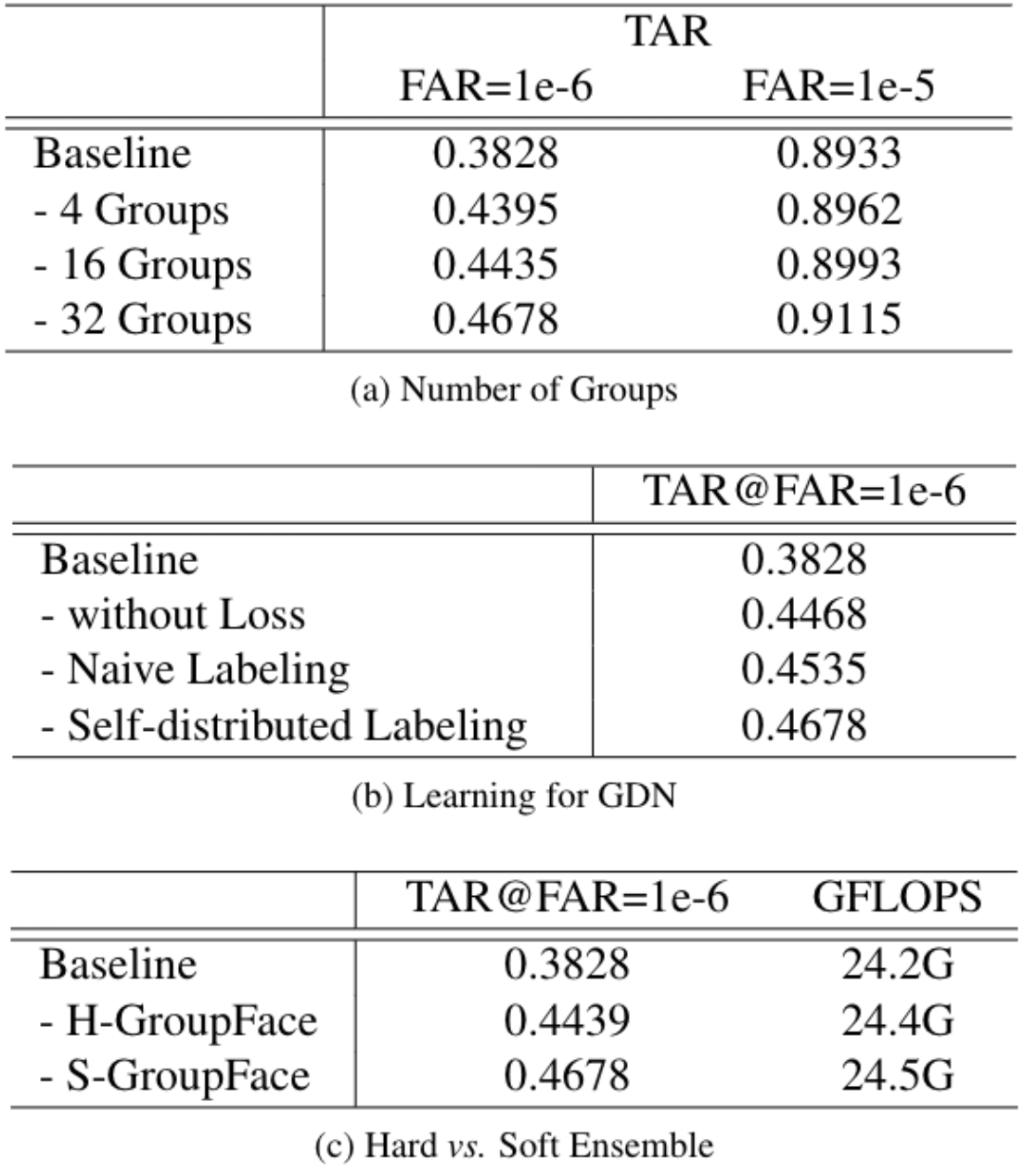
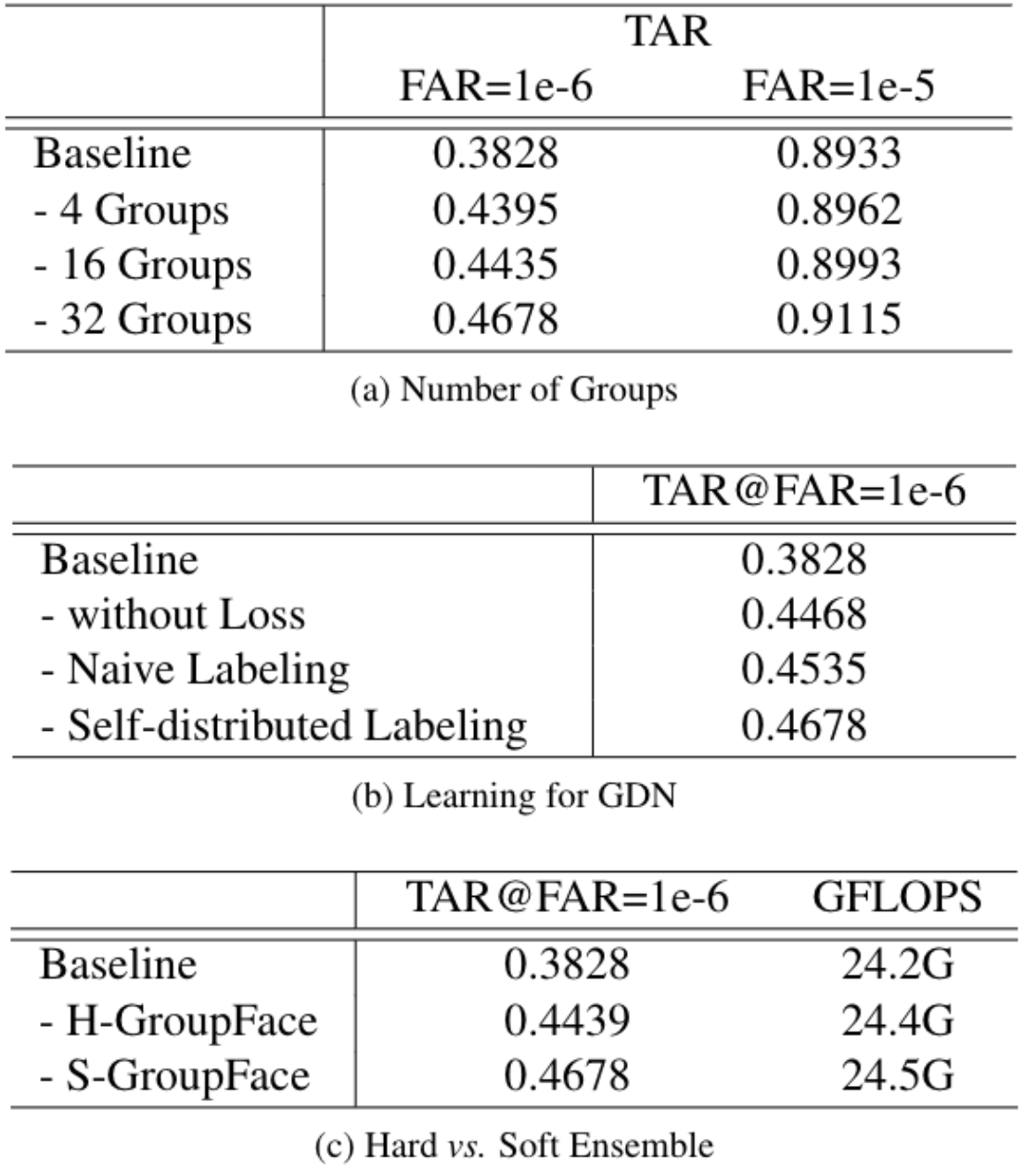
[ Table 3 ] Ablation studies for the proposed GroupFace on IJB-B dataset. The baseline is a recognition-model trained by ArcFace and † denotes an evaluation procedure using the group-aware similarity.
Visualization
The trained latent groups are not always visually distinguishable because they are categorized by a non-linear function of GDN using a latent feature, not a facial attribute (e.g., hair, glasses, and mustache). However, there are two cases of groups (Group 5 and 20) that we can clearly see their visual properties; 95 of randomly-selected 100 images are men in Group 5 and 94 of randomly-selected 100 images are bald men in Group 20. Others are not described as an one visual property, however, they seems to be described as multiple visual properties such as smile women, right-profile people and scared people in Group 1.

[ Figure 2 ] Example images belonging to each groups. As enormous identities (80k~) of large scale dataset cannot be mapped to a few groups (32), each group contains identities of multiple characteristics. Some groups have one common visual description with some variations while others have multi-mode visual descriptions.