COMPUTER VISION
BroadFace: Looking at Tens of Thousands of People at Once for Face Recognition
김용현(카카오엔터프라이즈), 박원표(카카오), 신종주(카카오엔터프라이즈)European Conference on Computer Vision (ECCV)
2020-08-23
얼굴 인식 모델은 수만에서 수십만 명에 달하는 인물 분류를 목표로 합니다. 미니배치mini-batch를 활용한 기존의 학습 방식은 한 번에 극소수의 인물만 다를 수 있어 얼굴 인식을 위한 최적의 결정 경계decision boundary 탐색을 어렵게 만듭니다.
공동 연구팀은 수많은 인물을 효과적으로 학습하는 기법인 BroadFace를 제안했습니다. BroadFace는 학습 과정에서 Queue에 저장해 둔 특징 벡터embedding vector를 활용, 분류 모델의 가중치 행렬weight matrix이 다수의 인물을 종합적으로 고려하도록 합니다. 이때, 특정 시점 대기열에 축적된 특징 벡터가 업데이트된 모델 가중치를 반영할 수 있게 하는 새로운 보상 기법도 마련했습니다.
그 결과, BroadFace를 적용한 얼굴 인식 모델은 더 많은 인물 정보를 고려하면서도, (추론 시) 연산 비용을 늘리지 않고도 현재 최고 수준의(SOTA) 성능을 획득할 수 있었습니다.
카카오엔터프라이즈는 이번 연구로 얻은 기술력과 경험을 바탕으로 자사 얼굴 인식 기술을 고도화할 계획입니다.
☛ Tech Ground 데모 페이지 바로 가기 : 얼굴 검출 데모
Abstract
The datasets of face recognition contain an enormous number of identities and instances. However, conventional methods have difficulty in reflecting the entire distribution of the datasets because a minibatch of small size contains only a small portion of all identities. To overcome this difficulty, we propose a novel method called BroadFace, which is a learning process to consider a massive set of identities, comprehensively. In BroadFace, a linear classifier learns optimal decision boundaries among identities from a large number of embedding vectors accumulated over past iterations. By referring more instances at once, the optimality of the classifier is naturally increased on the entire datasets. Thus, the encoder is also globally optimized by referring to the weight matrix of the classifier. Moreover, we propose a novel compensation method to increase the number of referenced instances in the training stage. BroadFace can be easily applied on many existing methods to accelerate a learning process and obtain a significant improvement in accuracy without extra computational burden at inference stage. We perform extensive ablation studies and experiments on various datasets to show the effectiveness of BroadFace, and also empirically prove the validity of our compensation method. BroadFace achieves state-of-the-art results with significant improvements on nine datasets in 1:1 face verification and 1:N face identification tasks, and is also effective in image retrieval.
Overall Architecture
We introduce BroadFace, which is a simple yet effective way to cover a large number of instances and identities. BroadFace learns globally well-optimized identity-representative vectors from a massive number of embedding vectors. For example, on a single Nvidia V100 GPU, the size of a mini-batch for ResNet-100 is at most 256, whereas BroadFace can utilize more than 8k instances at once. The following describes each step.
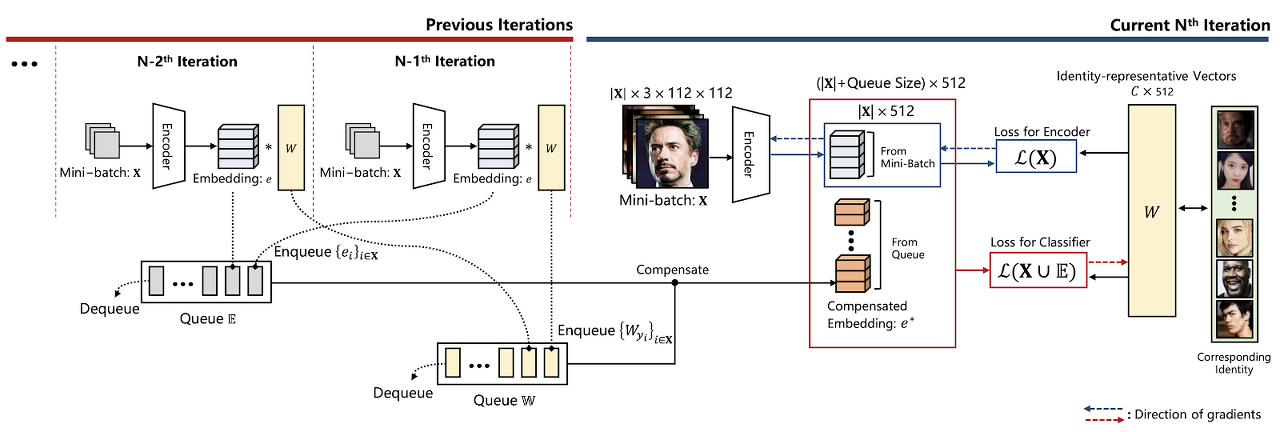
[ Figure 1 ] Learning process of the proposed method. BroadFace deploys large queues to store embedding vectors and their corresponding identity-representative vectors per iteration. The embedding vectors of the past instances stored in the queues are used to compute loss for identity-representative vectors. BroadFace effectively learns from tens of thousands of instances for each iteration.
Experiments
To show the effectiveness of our BroadFace, we evaluate the proposed method on various public datasets and achieve the state-of-the-art accuracy on all of the datasets. We also perform extensive ablation studies on the it’s behaviors.
1. Experimental Results
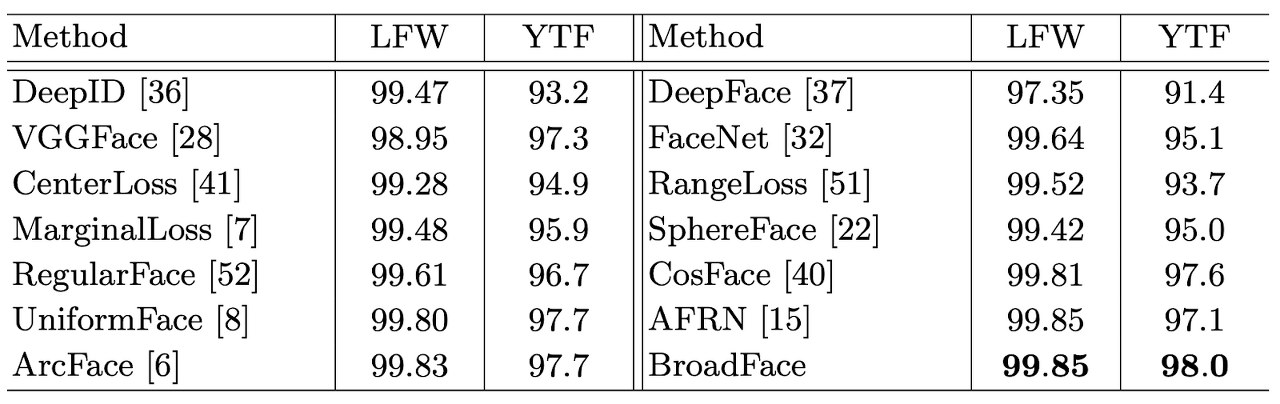
[ Table 1 ] Verification accuracy (%) on LFW and YTF.
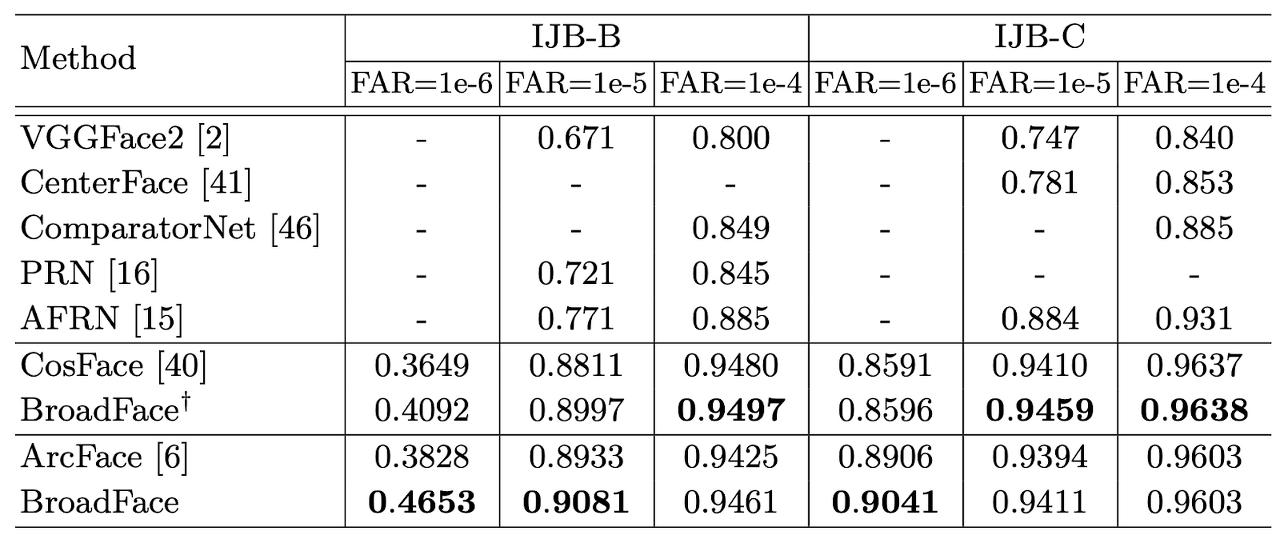
[ Table 2 ] Verification evaluation with a True Accept Rate at a certain False Accept Rate(TAR@FAR) from 1e-4 to 1e-6 on IJB-B and IJB-C. † denotes BroadFace trained by CosFace[40].
2. Ablation Studies
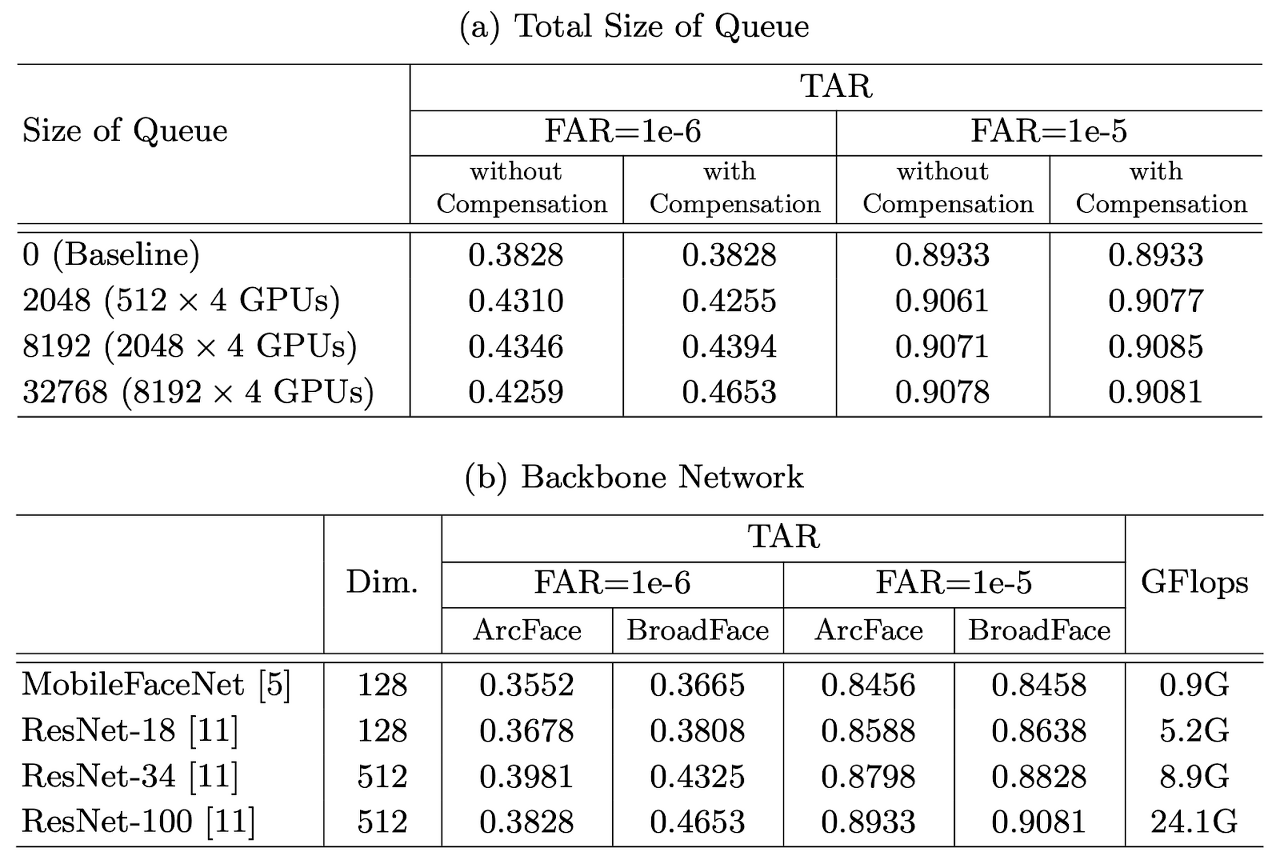
[ Table 3 ] Effects of BroadFace varying the size of the queue and the type of the backbone network on IJB-B dataset in face recognition.
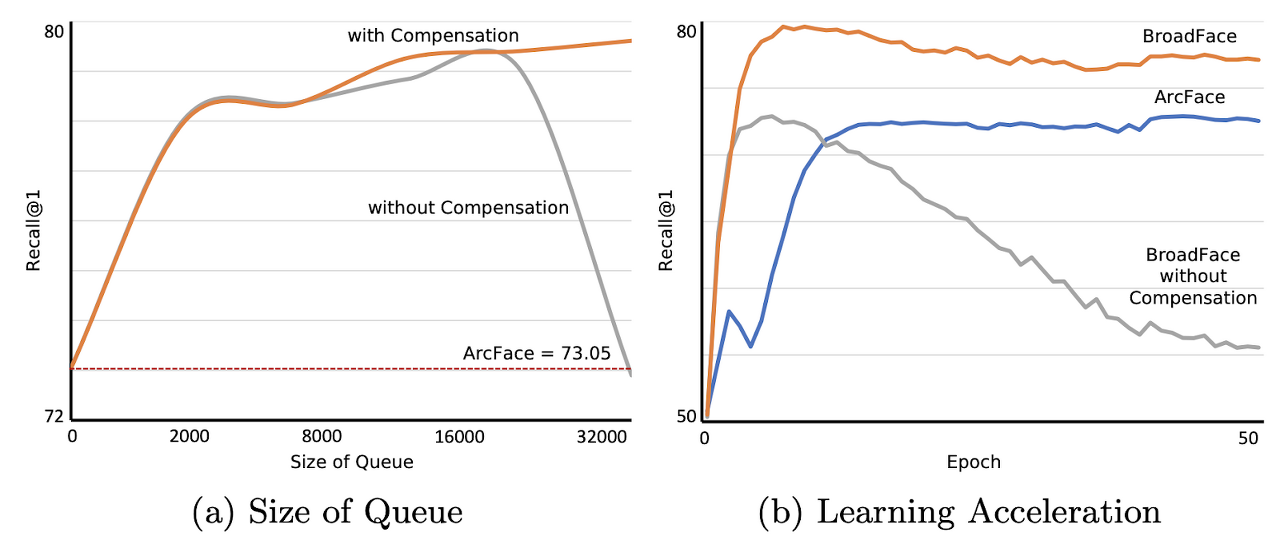
[ Figure 2 ] (a) the recall depending on the size of the queue in BroadFace with and without our compensation function; the red line indicates the recall of ArcFace (baseline) on the test set. (b) the learning curve for the test set when the size of the queue is 32k; ArcFace reaches the highest recall at the 45th epoch, our BroadFace reaches the highest recall at the 10th epoch, and the learning process collapses without our compensation function.