NLP
AligNART: Non-autoregressive Neural Machine Translation by Jointly Learning to Estimate Alignment and Translate
송종윤(카카오엔터프라이즈, 서울대), 김성원(서울대), 윤성로(서울대)Empirical Methods in Natural Language Processing (EMNLP)
2021-11-07
Abstract
Non-autoregressive neural machine translation (NART) models suffer from the multi-modality problem which causes translation inconsistency such as token repetition. Most recent approaches have attempted to solve this problem by implicitly modeling dependencies between outputs. In this paper, we introduce AligNART, which leverages full alignment information to explicitly reduce the modality of the target distribution. AligNART divides the machine translation task into (i) alignment estimation and (ii) translation with aligned decoder inputs, guiding the decoder to focus on simplified one-to-one translation. To alleviate the alignment estimation problem, we further propose a novel alignment decomposition method. Our experiments show that AligNART outperforms previous non-iterative NART models that focus on explicit modality reduction on WMT14 En↔De and WMT16 Ro→En. Furthermore, AligNART achieves BLEU scores comparable to those of the state-of-the-art connectionist temporal classification based models on WMT14 En↔De. We also observe that AligNART effectively addresses the token repetition problem even without sequence-level knowledge distillation.
카카오엔터프라이즈 AI Lab에서는 고품질의 번역 서비스를 제공하고자 신경망 기계 번역(Neural Machine Translation, 이하 NMT) 연구를 진행하고 있습니다. 본 글에서는 송종윤 님이 카카오엔터프라이즈 AI Lab 인턴 당시, 서울대 연구팀과 함께 연구한 AligNART 방법론을 간략하게 소개드리고자 합니다.
1. NMT(Neural Machine Translation)의 등장
먼저 기계 번역 발전과정을 짧게 살펴보면, 기존 기계 번역 분야는 수많은 과정을 거쳐 통계를 기반으로 진행되었습니다. 지난 2014년 말, 처음 등장한 NMT는 관련 업계에 큰 혁신을 가져왔습니다.
NMT는 encoder와 decoder로 구성된 하나의 큰 인공신경망을 기반으로, 간단히 기계 번역을 출력할 수 있도록 그 구조를 완전히 새롭게 바꾸었습니다. 현재도 번역 분야는 딥러닝이 가장 크게 활용되는 분야 중 하나인데요. NMT의 첫 등장 이후, NMT는 지속적인 발전을 거듭해오고 있습니다.
2. 기존 NMT 연구의 한계
일반적으로 NMT에서는 자기회귀(autoregressive) 모델이 활용되었습니다. 자기회귀 모델은 출력 단어 간의 종속성을 고려하여 좋은 성능을 내지만, 이로 인해 병렬화가 어려워 디코딩 속도가 느리다는 한계가 있습니다. 이러한 이유로 최근에는 단어 간의 종속성을 직접적으로 고려하기보다, 이같은 고려를 최소화한 비자기회귀(non-autoregressive) 모델이 주목받고 있습니다.
비자기회귀 모델은 독립적인 단어 생성을 통해 병렬화가 가능해, 속도를 크게 개선한 점이 특징입니다. 하지만, 이 과정에서 동일한 의미를 가진 토큰이 반복되거나 중요한 단어를 누락하여 잘못된 번역 결과를 도출하는 멀티 모달리티(multi modality) 문제를 안고 있습니다. 이번 연구는 바로 이 문제를 해결하기 위해 제시된 방법론입니다.
3. AligNART 방법론 소개
AligNART는 단어의 정렬(alignment) 정보를 활용하여 멀티 모달리티 문제를 개선하였습니다. 여기서 가장 중요한 역할을 하는 모듈이 바로 aligner입니다. aligner는 수많은 타겟 토큰의 정렬 정보를 동시에 예측하는 역할을 합니다.
이를 위해 정렬 분해(alignment decomposition) 구조를 새롭게 구성하여 사용했습니다. ‘Duplication - Permutation - Grouping’ 3단계를 통해 단어의 중첩을 예상하고, 단어의 어순이 바뀌지 않고 번역될 수 있도록 그 순서배열을 정리하고, 복합 형태의 단어가 담고 있는 단일 의미를 고려하여 최종 단어를 매핑하는 과정을 거쳤습니다. 이렇게 출력된 정렬 정보를 다시 디코더의 입력값(input)으로 활용하여 번역 성능을 높였습니다.
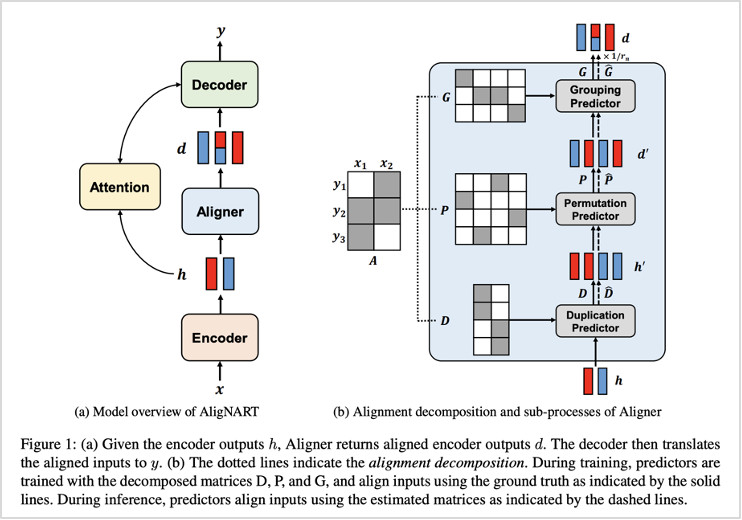
그림1. (좌)AligNART 전체 구조, (우)Alignment decomposition 구조
4. 성능 평가
모델 성능을 평가하기 위해, WMT14 En↔De와 WMT16 Ro↔En 케이스에서 BLEU score를 측정하였습니다. BLEU는 기계 번역 결과와 사람이 직접 번역한 결과를 비교하여 그 결과가 얼마나 유사한지를 기준으로, 기계 번역에 대한 성능을 평가하는 방법입니다.
AligNART는 해당 평가에서 SOTA 수준의 우수한 성능을 보였습니다. 본 연구에서는 aligner 모듈의 유효성을 검증하는 것이 주요 목적이었기 때문에, 별도의 목적함수를 조정하지 않았습니다. 향후 후속 연구에서 목적함수를 최적화한다면 현재보다 높은 성능을 보일 것으로 기대가 됩니다.
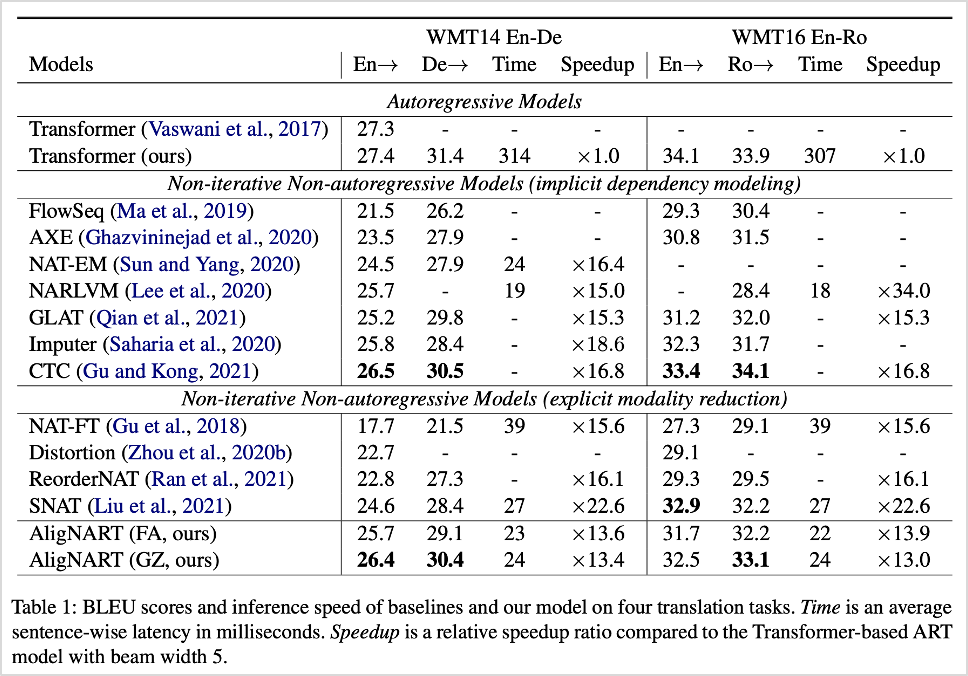
표1. BLEU Score 측정 결과
5. 향후 연구 계획
AligNART 모델은 기존 NMT보다 추론이 단순하고 속도가 빨라, 엣지 디바이스와 같이 가볍고 빠른 번역 결과가 필요한 곳에 효과적으로 적용될 수 있습니다. 향후 엣지 디바이스 상에서 보다 빠르고 정확한 번역 서비스를 제공하기 위해 관련 연구를 지속적으로 발전시켜 나갈 계획입니다. 앞으로도 카카오엔터프라이즈의 AI 연구에 많은 관심 부탁드립니다. 감사합니다.
► 카카오엔터프라이즈의 번역서비스가 궁금하다면 지금 바로 카카오 i 엔진을 확인해보세요!
현재 카카오엔터프라이즈 AI Lab에서는 다양한 AI 연구와 서비스화를 함께 고민해나갈 여러분의 지원을 기다리고 있습니다. AI를 통해 더욱 가치있는 세상을 만들고, 꿈을 현실로 만들어가는 여정에 함께하세요!
👨🏻💻 인재채용