NLP
한국어 질의 응답에서의 화제성을 고려한 딥러닝 기반 정답 유형 분류기
조승우(카카오), 최동현(카카오), 김응균(카카오)한글 및 한국어정보처리 학술대회
2019-10-11
카카오엔터프라이즈는 한국어 질의응답 시스템의 입력 질의 문장을 단답형/서술형으로 분류하는 모델을 제안했습니다. 모델의 분류 성능을 높이고자 육하원칙 정보와 포털 서비스 쿼리에서 추출한 화제성을 가진 주제어와 속성 표현도 함께 입력하는 방식으로 모델의 분류 성능을 높였습니다.자체 실험 결과, 기존 모델과 비교해 카카오엔터프라이즈가 제안한 기법을 모두 반영한 모델의 분류 정확도가 4% 높아졌습니다.
카카오엔터프라이즈는 정답 유형 분류기의 성능을 개선하기 위한 연구를 앞으로도 계속 진행할 계획입니다.
☛ Tech Ground 데모 페이지 바로 가기 : 지문분석 데모 | 통합분석 데모
전체 구조
주어진 질의가 단답형 답변을 요구하는지, 또는 서술형 답변을 요구하는지 여부는, 해당 질의의 문맥 정보만 가지고는 판단이 불가하다. 또한, 이러한 질의 주제어들은 화제성에 따라 새로이 추가되거나 제거될 수 있다. 본 논문에서는 이러한 문제를 해결하기 위하여, 포털 사이트 쿼리 로그로부터 질의에 포함될 수 있는 후보질의 주제어들을 추출하고, 이를 자질로 사용하여 주어진 질문이 서술형 답변을 요구하는지, 또는 단답형 답변을 요구하는지 판별하는 합성곱 신경망(Convolutional Neural Network) 기반 문장 분류 네트워크를 제안한다. 제안된 시스템의 성능을 추가적으로 향상시키기 위하여, 문장의 육하원칙 정보 및, 수작업으로 구축된 속성 표현들이 같이 사용되었다.
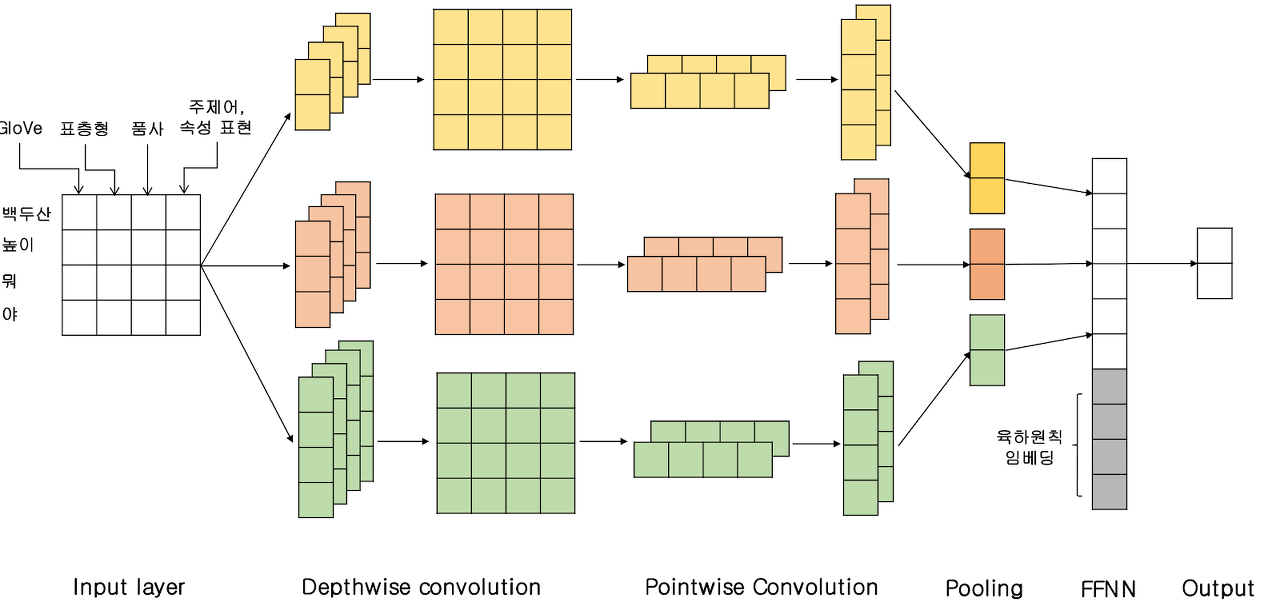
[ 그림 1 ] 깊이별 분리 합성곱 신경망 기반 분류 네트워크 모델
실험
[표 1]에서 베이스라인 모델과 비교하여 제안 모델은 4% 정도 더 높은 분류 정확도를 가진 것으로 나타났다. 유형별 분류 개선 정도는 단답형 분류에 실패한 문장(C1), 서술형 분류에 실패한 문장(C2), 둘 다 올바르게 분류한 문장(C3)을 보면, 단답형 질문에 대한 오류는 제안 기법을 통해서 월등히 개선되었으나, 서술형 질문에 대한 오류는 비슷한 수준을 유지하는 것으로 집계되었다.

[ 표 1 ] 베이스라인 모델과 제안 모델 성능 비교
[표 2]는 추가 정보에 대한 Ablation 실험 결과이다. 개별적인 추가 정보를 제거했을 때, 육하원칙(5W1H)이 0.5%, 화제성 반영 질의 주제어(Topic)는 0.75%, 속성 표현(Attr)은 3.25% 정도 성능이 하락하는 것을 발견하였다. 따라서, 속성 표현이 가장 주요한 추가 정보였으며, 화제성 반영 질의 주제어, 육하원칙이 순차적으로 높은 중요도를 가지는 것을 알 수 있었다.
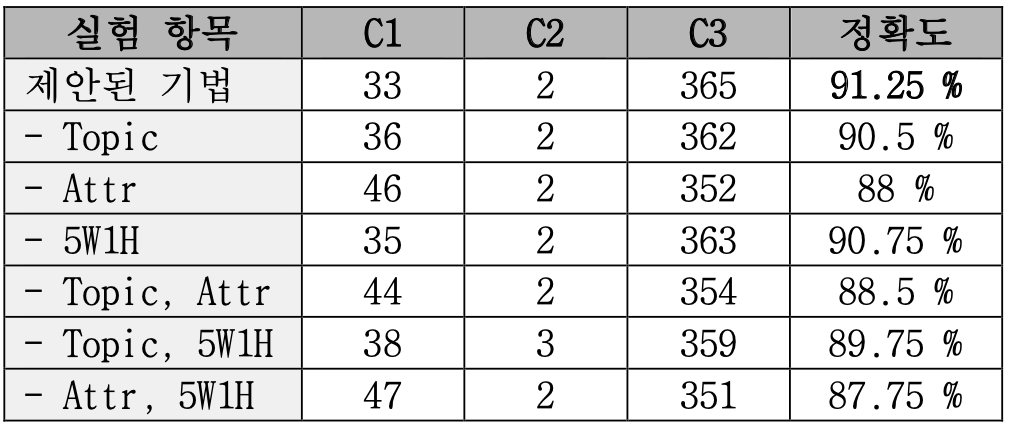
[ 표 2 ] 추가 정보에 대한 Ablation 실험 결과