NLP
한국어 챗봇에서의 오류에 강건한 한국어 문장 분류를 위한 어절 단위 임베딩
최동현(카카오), 박일남(카카오), 신명철(카카오), 김응균(카카오), 신동렬(성균관대학교)한글 및 한국어정보처리 학술대회
2019-10-11
카카오엔터프라이즈는 철자가 잘못 입력된 한국어 문장의 분류 성능을 높이고자 새로운 통합 어절 임베딩 방식을 제안했습니다. 형태소와 자모음 정보에 각각 부여한 임베딩 벡터를 이용해 다시 원래 어절을 조압하고 데이터에 노이즈를 자동으로 추가하는 방식으로 오류를 포함한 문장 분류 성능을 높입니다. 자체 실험 결과, 기존 시스템과 비교해 오류를 포함한 문장의 분류 정확도를 23%p 높였습니다.
카카오엔터프라이즈는 더 많은 종류의 임베딩을 하나로 통합하는 방법과 새로운 데이터 노이즈 추가 방법에 관한 지속적인 연구를 진행할 계획입니다.
☛ Tech Ground 데모 페이지 바로 가기 : 지문분석 데모 | 통합분석 데모
전체 구조
텍스트를 입력으로 받는 한국어 챗봇의 경우, 때때로 입력 문장에 오타나 띄어쓰기 오류 등이 포함될 수 있고, 이러한 오류는 잘못된 형태소 분석 결과로 이어지게 된다. 본 논문은 띄어쓰기 오류에 국한된 것이 아닌, 일반적인 오류를 포함한 문장에 대한 문장 분류 문제를 해결하고자 하였고, 이를 위해 기존의 형태소 임베딩 기반 방식 대신 어절 임베딩 기반 방식이 새로이 제안되었다. 어절 임베딩 벡터 방식의 오류를 포함한 한국어 문장 분류 성능을 추가적으로 향상시키기 위하여, 자모 드롭아웃과 띄어쓰기없는 문장 생성의 두가지 데이터 노이즈(noise) 추가 방법도 제안되었다.
실험
실험 결과에 따르면, 제안된 시스템은 기존 관련 연구에서 제안된 형태소 기반 문장 분류 시스템과 비교하여 오류를 포함한 문장 분류 문제(KT 말뭉치)에서 24.3%p, 문법적으로 옳은 문장을 분류하는 문제(WF 말뭉치)에서 0.63%p의 성능 향상을 보였다. 통합 어절 임베딩을 사용할 경우 SM 말뭉치에 대한 성능은 크게 저하되나, 제시된 실험 결과에서 보여지듯이 띄어쓰기 없는 문장 생성 방법을 사용함으로써 이러한 통합 어절 임베딩의 단점을 극복할 수 있었다. 띄어쓰기 없는 문장 생성 방법을 사용한 시스템 어절+SG의 SM 말뭉치에 대한 성능은 88.31%인데, 이는 Baseline 시스템의 83.46% 보다 오히려 4.85%p 더 향상된 것이다.
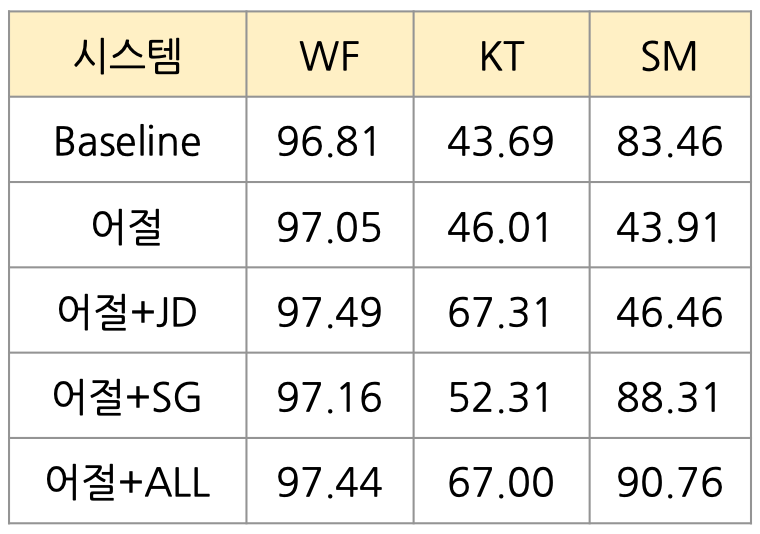
[ 표 1 ] 통합 어절 임베딩 적용 실험 결과
[표 2]는 동일한 데이터 노이즈 추가 방법이 적용되었을 때, 통합 형태소 임베딩과 통합 어절 임베딩간의 분류 성능 비교를 보여주고 있다.
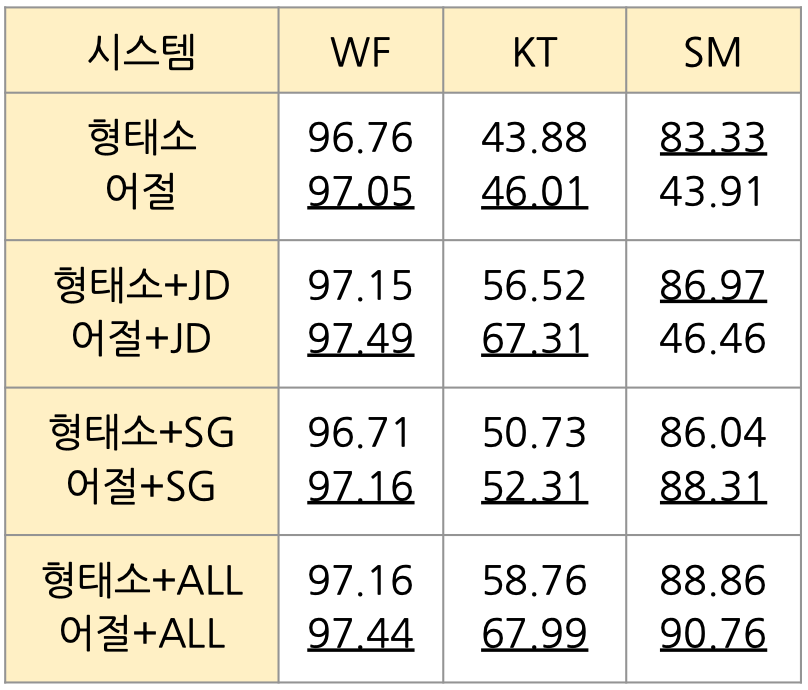
[ 표 2 ] 통합 어절 임베딩과 통합 형태소 임베딩의 비교