COMPUTER VISION
Distilling Global and Local Logits with Densely Connected Relations
김유민(경희대, 카카오엔터프라이즈), 박진배(경희대), 장윤호(경희대), Muhammad Ali(경희대), 오태현(포항공대), 배성호(경희대)International Conference on Computer Vision (ICCV)
2021-10-11
Abstract
In prevalent knowledge distillation, logits in most image recognition models are computed by global average pooling, then used to learn to encode the high-level and task-relevant knowledge. In this work, we solve the limitation of this global logit transfer in this distillation context. We point out that it prevents the transfer of informative spatial information, which provides localized knowledge as well as rich relational information across contexts of an input scene. To exploit the rich spatial information, we propose a simple yet effective logit distillation approach. We add a local spatial pooling layer branch to the penultimate layer, thereby our method extends the standard logit distillation and enables learning of both finely-localized knowledge and holistic representation. Our proposed method shows favorable accuracy improvement against the state-of-the-art methods on several image classification datasets. We show that our distilled students trained on the image classification task can be successfully leveraged for object detection and semantic segmentation tasks; this result demonstrates our method’s high transferability.
본 글에서는 카카오엔터프라이즈 AI Lab과 경희대, 포항공대에서 함께 연구한 새로운 지식 증류(Knowledge Distillation) 방법론이 ICCV 2021 학회를 통해 발표되어, 간략하게 소개드리고자 합니다.
1. 지식 증류 기법의 등장
지식 증류 기법은 기 학습된 거대 모델(teacher)의 지식을 새로운 네트워크(student)가 전달받아 학습하는 방식으로, ‘teacher-student’ 모델이라고도 합니다. 잘 학습된 teacher 모델을 기반으로, 경량화된 student 모델이 학습을 통해 그에 버금가는 우수한 성능을 내고자 한다는 점이 특징입니다.
지식 증류 기법은 기존 딥러닝 모델이 가지는 컴퓨팅 리소스과 메모리의 한계, 긴 추론시간 등의 문제를 해결하고자 제시된 방법입니다. 일반적으로 딥러닝 모델은 모델의 크기가 커질수록, 즉 파라미터 수가 많아질수록 더 높은 성능을 내게 됩니다. 더 많은 연산량을 처리하기 위해서는 대량의 컴퓨팅 리소스와 학습시간을 필요로 하기 때문에, 상대적으로 저성능, 저전력의 소형 모바일 디바이스나 IoT 기기에는 이를 활용하기 어렵다는 문제가 있었습니다. 이같은 문제를 해결하고 효율적인 딥러닝 학습을 시도하기 위한 움직임으로, 현재 지식 증류 기법 연구가 주목받고 있습니다.
2. 기존 지식 증류 기법의 한계
지식 증류 과정에서 teacher 모델의 정보를 student 모델에 전달하기 위해, logit 값이 활용됩니다. 여기서 logit은 해당 task와 직접적인 연관을 가지는 모델의 출력값으로, feature보다 입력 이미지에 대한 모델의 representation 정보를 풍부하게 담고 있어 학습 데이터와 함께 사용될 경우 효율적인 학습이 가능해집니다.
이때 logit은 과적합(overfitting)을 방지하기 위해 global average pooling(GAP)으로 계산되는데, 이로 인해 logit을 활용한 기존 연구들에서는 세부 공간에 대한 logit을 사용할 수 없다는 한계가 존재했습니다. 이에 카카오엔터프라이즈 연구팀은 global logit과 local logit이라는 개념을 새롭게 제시한 ‘Global and Local Logit with Densely Connected Relations(GLD)’ 방법론을 제안하여 이같은 문제를 해결하고자 하였습니다.
3. Global and Local Logit with Densely Connected Relations(GLD) 방법론 소개
해당 방법론의 가장 큰 특징은 앞서 언급한 global logit과 local logit을 모두 사용했다는 점입니다. 먼저 global logit은 입력된 이미지의 global feature에서 classifier를 거쳐 최종적으로 산출된 값으로, 기존 연구에서 주로 활용되던 정보입니다. 여기에 global feature를 세분화한 뒤, 동일한 방식으로 산출한 값이 local logit입니다. 보다 세밀한 공간 정보를 담은 local logit을 추가적으로 사용함으로써 디테일한 정보를 학습에 반영할 수 있게 되었습니다.
또한, 개별 이미지 샘플에서 세부 영역의 관계 정보를 파악할 수 있음은 물론, 여러 샘플값 간의 관계 정보도 파악하여 모델 성능을 높였습니다.
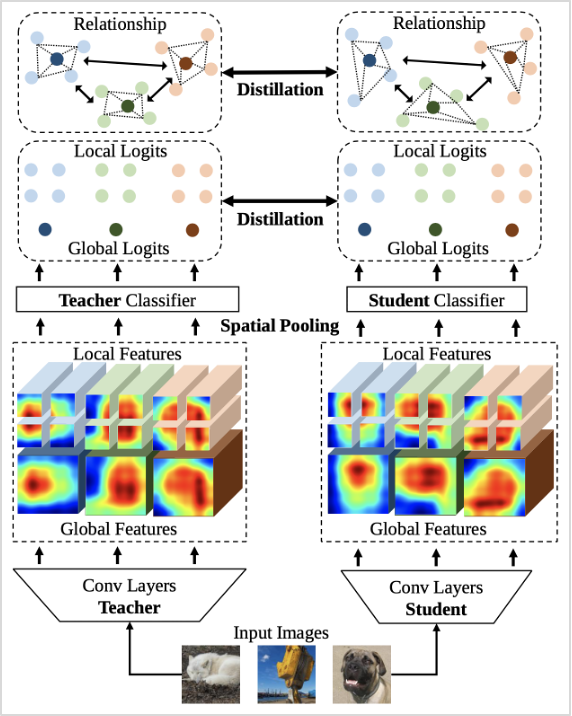
그림1. GLD 전체 구조
이밖에도 GLD에서는 logit 값을 정규화하기 위해 loss 함수 LND을 새롭게 제안하였습니다. 기존 방법론에서는 softmax 함수 사용으로 정보량이 적은 확률 분포가 도출되는 문제를 해결하기 위해, 고정된 temperature 파라미터를 사용하여 확률 분포의 정보량을 증가시켰습니다. 하지만, 이는 개별 이미지마다 확률 분포의 특징이 다르다는 것을 고려하지 않았다는 한계가 있었기 때문에, GLD에서는 입력 이미지마다 logit의 표준편차를 사용하여 개별 조정하는 방식을 활용하였습니다.
4. 성능 평가
카카오엔터프라이즈 연구팀은 모델의 성능을 검증하기 위해, 9가지의 지식 증류 SOTA(State-of-the-art) 모델과 성능 비교 실험을 진행하였습니다. 실험결과는 각각 CIFAR-100, ImageNet, CINIC-10, STL-10, VOC2007, COCO2017 데이터셋으로 측정하였습니다.
먼저 이미지 분류 문제에서 성능 테스트를 위해 CIFAR-100, ImageNet 데이터를 활용하였습니다. CIFAR-100 테스트에서는 다양한 환경에서의 방법론 검증을 위해 총 4가지의 실험모델을 구성하여 테스트를 진행하였고, ImageNet 테스트에서는 Top-1과 Top-5 정확도를 구분하여 평가한 결과 기존 연구 모델보다 평균적으로 우수한 성능을 확인할 수 있었습니다.
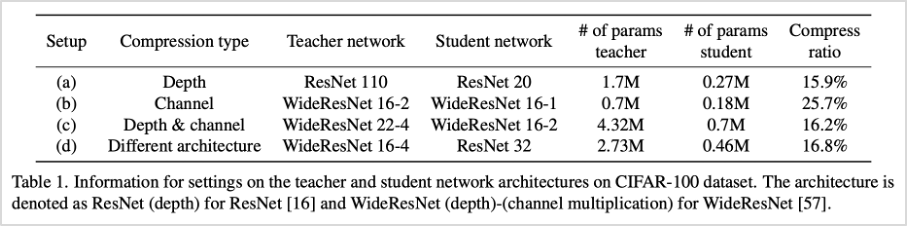
표1. 실험모델 구성 (CIFAR-100 데이터셋 기준)
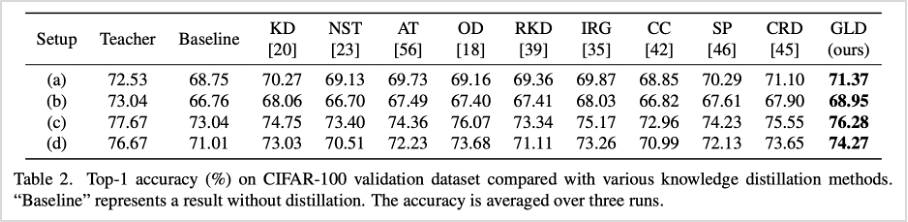
표2. GLD와 기존 방법론 성능 비교 (CIFAR-100 데이터셋 기준)
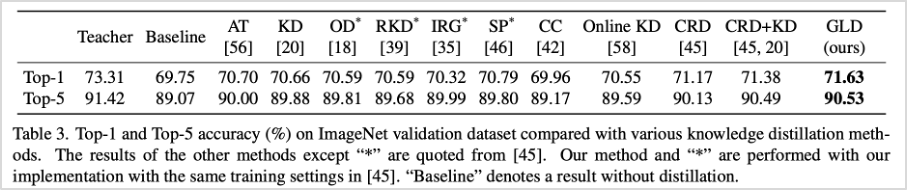
표3. GLD와 기존 방법론 성능 비교 (ImageNet 데이터셋 기준)
또한, 실질적으로 teacher 모델에서 student 모델로 얼마나 지식이 잘 전달될 수 있는지, 그 성능을 평가해보고자 학습되지 않은 CINIC-10과 STL-10 데이터셋을 활용하여 실험을 진행한 결과 SOTA보다 높은 성능을 확인할 수 있었습니다.
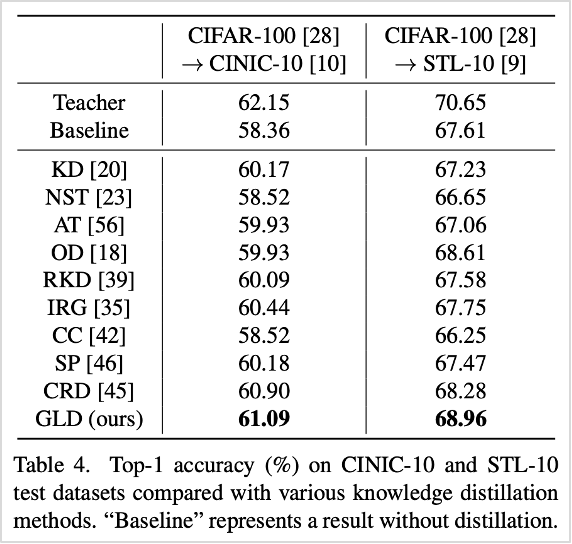
표4. GLD와 기존 방법론 성능 비교 (CINIC-10과 STL-10 데이터셋 기준)
이밖에도 객체 탐지와 시멘틱 세그멘테이션 문제에서 성능을 확인하기 위해 VOC2007, COCO2017 데이터셋을 활용한 결과, 우수한 성능을 확인함은 물론, 이미지 분류뿐만 아니라 feature representation 영역에서 높은 성능을 나타냄을 확인할 수 있었습니다.
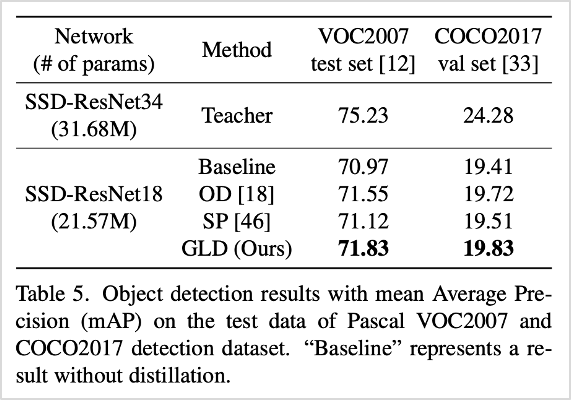
표5. 객체 탐지 문제에서의 GLD와 기존 방법론 성능 비교 (VOC2007과 COCO2017 데이터셋 기준)
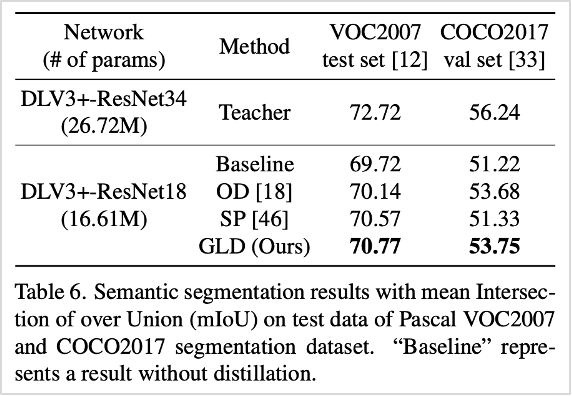
표6. 시멘틱 세그멘테이션 문제에서의 GLD와 기존 방법론 성능 비교 (VOC2007과 COCO2017 데이터셋 기준)
5. 향후 연구 계획
향후 해당 방법론을 기반으로 딥러닝 알고리즘을 경량화하여 얼굴 인식 및 여러가지 비전 기반 서비스의 계산량을 효율화하는 데에 활용할 계획입니다. 앞으로도 카카오엔터프라이즈 연구에 많은 관심과 응원 부탁드립니다. 감사합니다.