COMPUTER VISION
A Plug-in Method for Representation Factorization in Connectionist Models
윤재석(고려대학교), 노명철(카카오엔터프라이즈), 석흥일(고려대학교)IEEE Transactions on Neural Networks and Learning Systems
2021-02-10
일반적으로 딥러닝 모델의 성능은 과제를 수행하는 데 필요한 필수 정보를 추출하고 이를 최대한 압축한 임베딩 벡터embedding vector를 제대로 표현하는 능력에 있다고 해도 과언이 아닙니다. 다만 각 차원이 여러 요인을 함축적으로 포함하는 그 특성상, 사람이 벡터를 해석하는 데에는 한계가 있습니다. 머리 색, 머리 길이, 얼굴형, 눈썹 모양, 얼굴색 등이 얼굴을 구성하는 요소라고 본다면, 딥러닝 모델이 생성한 벡터는 차원1-머리색/머리길이, 차원2-머리길이/얼굴색 등으로 여러 차원에 여러 요인이 복잡하게 얽혀 있죠.
이에 데이터를 독립 요인independent factor에 상응하는 해석 가능한 표현disentangled representation으로 만드는 방법에 관한 연구가 활발하게 이뤄지고 있습니다. 공동 연구팀 또한 이 대열에 합류, 총 상관계수total correlation1를 최소화하는 방식으로 의미상 제어할 수 있는 요인으로 임베딩 벡터를 분해하는 기법인 FDENFactors Decomposer-Entangler Network을 제안했습니다.
FDEN은 학습된 모델pre-trained model의 가중치weight 값을 변경하지 않고도 사용할 수 있는 플러그인plug-in 방식으로 동작합니다. 모델이 추출한 임베딩 벡터에서 요인에 영향을 미치는 부분을 찾아내는(해석하는) 별도의 단계를 뒀다는 의미입니다. 이 덕분에 우수한 성능을 내는 여러 학습 모델에 바로 적용해볼 수 있습니다.
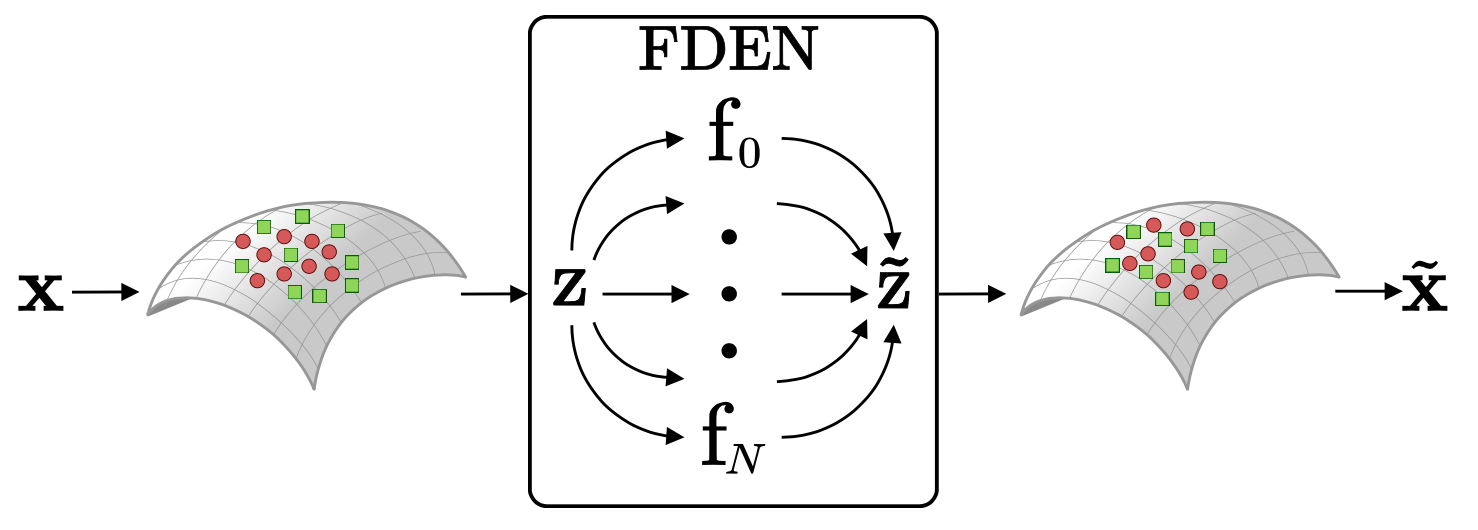
[ 그림 1 ] 가중치를 고정한 사전학습한 모델에 플러그인 방식으로 동작하는 FDEN은 출력된 임베딩 벡터 z를 해석가능한 표현 \(\tilde{z}\)로 바꾼다.
연구팀은 스타일 변환style transfer, 이미지 간 번역image-to-image translation, 퓨샷 러닝few-shot learning 등 다양한 태스크에서 우수한 성능을 내는 모델에 FDEN을 적용했습니다. 그 결과, FDEN은 사람이 라벨링한 요인을 효과적으로 분해할 수 있었습니다. 독립 요인(\(f_0\)+\(f_1\)+\(f_2\)…+\(f_n\))을 합쳐 기존 데이터(\(z\))와 유사한 데이터(\(\tilde{z}\))도 생성할 수 있음을 확인했습니다. 이는 사람이 해석 가능한 독립 요인을 조절해 새로운 데이터 혹은 사람이 원하는 데이터를 만들어낼 수 있음을 시사합니다.
연구팀은 비지도학습unsupervised learning2을 이용해 사람이 찾지 못한 요인을 섬세하게 분해할 방법론에 관한 연구를 진행할 계획입니다.
Overall Architecture
The objective of FDEN is to decompose input representation \(z\) into independent and semantically interpretable factors without losing the original information in the latent or feature representation \(z\). To achieve this aim, we compose an FDEN with three modules (Figure. 1): Decomposer \(D\), Factorizer \(F\), and Entangler \(E\). Note that because FDEN uses a fixed pretrained network and deals with the latent or feature representation from the network, it allows factorizing the input representation for other new tasks while maintaining the network capacity or power for its original tasks intact.
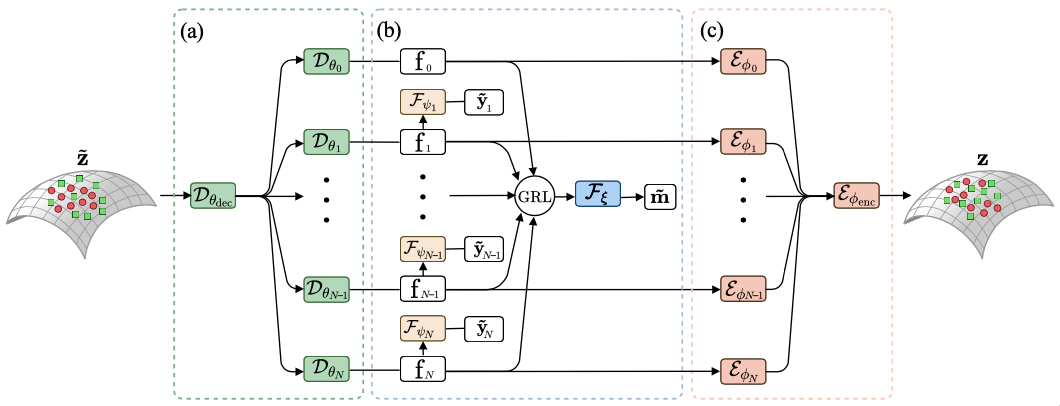
[ Figure 1 ] FDEN is divided into three modules: Decomposer \(D\), Factorizer \(F\), and Entangler \(E\). The model is an autoencoder-like architecture that takes representation \(z\) as the input and reconstructs its original representation (\(\tilde{z}\)). (a) First, Decomposer \(D\) takes a representation \(z\) from a fixed pretrained network as the input and decomposes it into a set of factors \(f_i\) (\(∀_i\) ∈ \(N\)). (b) Next, Factorizer \(F\) uses an information theoretic way to maximize the independence of each factor. (c) Finally, Entangler \(E\) takes the factors and reconstructs their original representation (\(\tilde{z}\)).
Experiments
Our objective here is to demonstrate that each module of FDEN is effective at decomposing a latent representation into independent factors. First, we evaluate the effectiveness of factors by performing various downstream tasks. Next, we analyze individual units of factors to verify if a representation is indeed reasonably factorized. We perform style transfer with human labeled attributes (Fig. 2). The results of style transfer with FDEN confirms a clear transfer of attributes.

[ Figure 2 ] Results of style transfer for the CelebA-128 dataset with N=7 factors (where \(f_0\) is the style factor). Images in the first and second columns are reconstructed images from Pioneer Network and FDEN, respectively. The following images are reconstructed images with one attribute opposite to the input image (e.g., \(1{^{st}}\) row \(f_3\): “not bald” transferred to “bald”; \(2{^{nd}}\) row \(f_3\): “young” transferred to “not young”). The original attributes of both input images are: “not bald”, “male”, “young”, “without smile”, “without beard”, “without eyeglasses” (note that the 1st row image is annotated as “with goatee, but without beard”).