SPEECH/AUDIO
JDI-T: Jointly trained Duration Informed Transformer for Text-To-Speech without Explicit Alignment
임단(카카오), 장원(카카오엔터프라이즈), 오경환(카카오엔터프라이즈), 박혜영(카카오엔터프라이즈), 김봉완(카카오엔터프라이즈), 윤재삼(카카오엔터프라이즈)Conference of the International Speech Communication Association (INTERSPEECH)
2020-10-26
FastSpeech와 DurIAN과 같은 최신의 음성 합성 모델은 오류가 없는 고품질의 멜-스펙트로그램Mel-spectrogram1 생성에 탁월합니다. 하지만 훈련에 필요한 음소phoneme의 길이 정보를 확보하기 위해서는 합성 모델과는 별도로, 음소와 오디오를 명시적으로 정렬explicit alignment하는 모델을 따로 준비해야 하는 번거로움이 따릅니다.
이에 공동 연구팀은 음성합성 모델과 음소-오디오 정렬 모델을 한꺼번에 훈련joint training하는 아키텍처인 JDI-T를 제안했습니다. 제안 모델은 자사 내부 데이터와 공개 한국어 데이터셋인 KSSKorean Single Speaker Speech에서 다른 최신 음성 합성 모델과 비교해 우수한 성능을 보였습니다.
카카오엔터프라이즈는 향후 다양한 시나리오를 대비해 자사 음성 합성 기술을 고도화할 계획입니다.
Abstract
We propose Jointly trained Duration Informed Transformer (JDI-T), a feed-forward Transformer with a duration predictor jointly trained without explicit alignments in order to generate an acoustic feature sequence from an input text. In this work, inspired by the recent success of the duration informed networks such as FastSpeech and DurIAN, we further simplify its sequential, two-stage training pipeline to a single-stage training. Specifically, we extract the phoneme duration from the autoregressive Transformer on the fly during the joint training instead of pre-training the autoregressive model and using it as a phoneme duration extractor. To our best knowledge, it is the first implementation to jointly train the feed-forward Transformer without relying on a pre-trained phoneme duration extractor in a single training pipeline. We evaluate the effectiveness of the proposed model on the publicly available Korean Single speaker Speech (KSS) dataset compared to the baseline text-to-speech (TTS) models trained by ESPnet-TTS.
Overall Architecture
The proposed model, consisting of the feed-forward Transformer, the duration predictor, and the autoregressive Transformer, is trained jointly without explicit alignments. After joint training, only the feed-forward Transformer with the duration predictor is used for fast and robust conversion from phoneme sequences to mel-spectrogram.
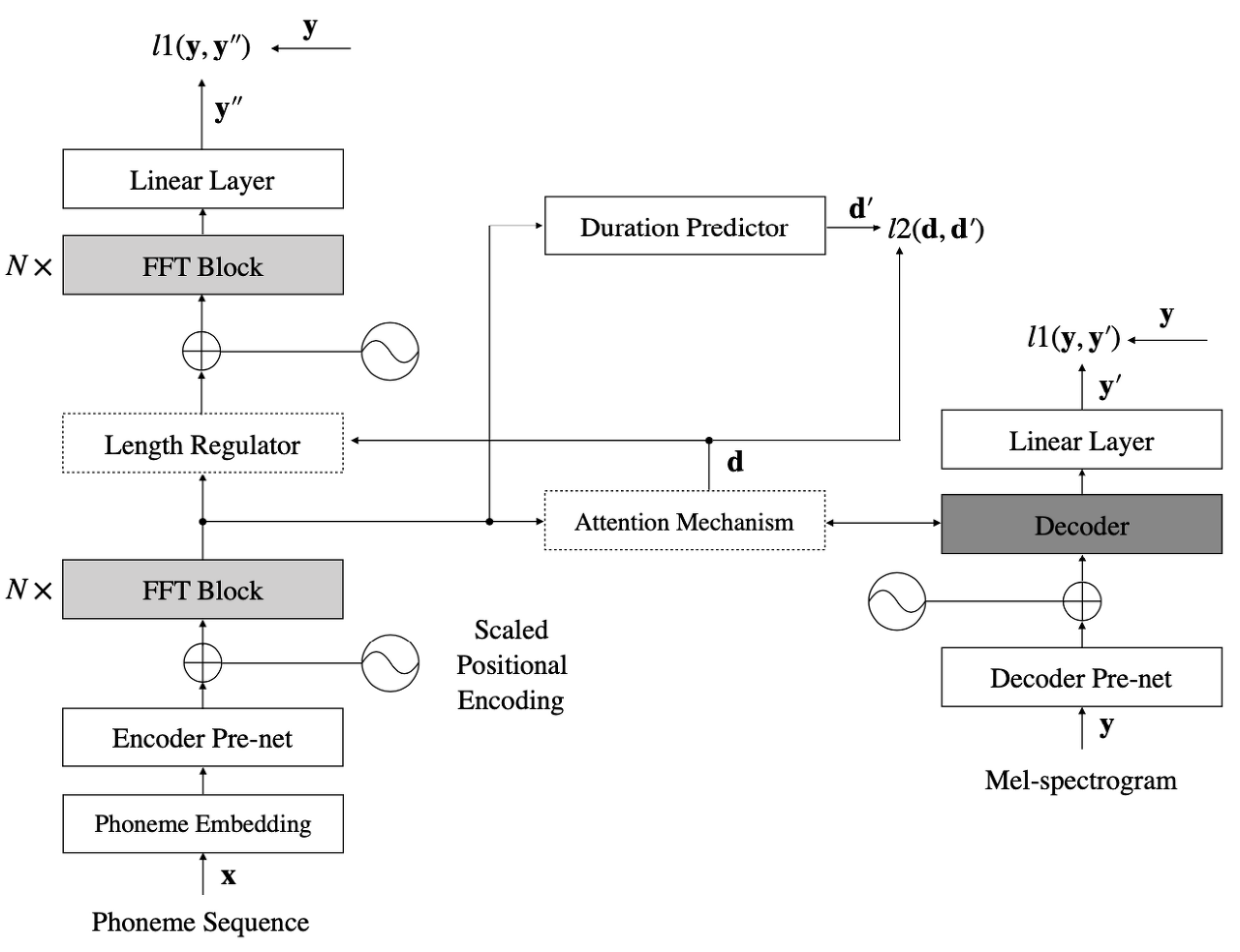
[ Figure 1 ] An illustration of our proposed joint training framework (Auxiliary loss for attention is omitted for brevity.)
Experiments
To evaluate the effectiveness of the proposed model, we conduct the Mean Opinion Score(MOS) test . The proposed model, JDI-T, is compared with three different models, including Tacotron2, Transformer, and FastSpeech. Table 1 shows the results on two different datasets; the Internal and the KSS.
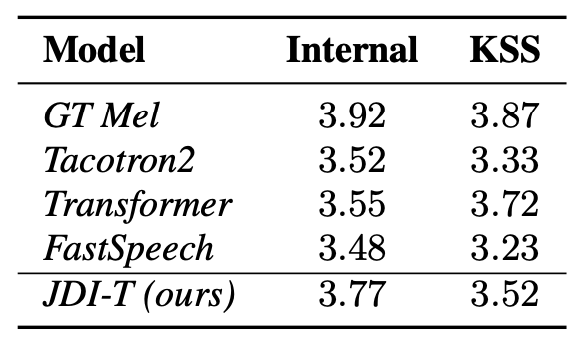
[ Table 1 ] Mean opinion scores(5-point scale)
The score of our proposed model, which is also non-autoregressive and duration informed model like FastSpeech, is better than FastSpeech and even achieves the highest score among the TTS models in the Internal dataset. These results show that the joint training of the proposed model is beneficial for improving the audio quality as well as for simplifying the training pipeline.
In addition to its high-quality speech synthesis, the proposed model has benefits of the robustness and fast speed at synthesis over the autoregressive, attention-based TTS models since it has the feed-forward structure and does not rely on an attention mechanism as in FastSpeech. Moreover, our internal test shows that Tacotron2 and Transformer have a high rate of synthesis error, especially when they are trained with the KSS dataset and synthesize the out-of-domain scripts. Note that the synthesized audio samples from the test scripts have no synthesis error.
Footnotes
-
음성 신호를 멜 스케일(mel-scale)에 따라 주파수를 분석하여 얻은 특징 벡터로, 기계학습 모델에서 음성을 나타내는 데 주로 쓰인다. ↩