SPEECH/AUDIO
SE-Conformer: Time-Domain Speech Enhancement using Conformer
김의성(카카오엔터프라이즈), 서혜지(카카오엔터프라이즈)Conference of the International Speech Communication Association (INTERSPEECH)
2021-08-30
Abstract
Convolution-augmented transformer(Conformer) has recently shown competitive results in speech-domain applications, such as automatic speech recognition, continuous speech separation, and sound event detection. Conformer can capture both the short and long-term temporal sequence information by attending to the whole sequence at once with multi-head self-attention and convolutional neural network. However, the effectiveness of conformer in speech enhancement has not been demonstrated. In this paper, we propose an end-to-end speech enhancement architecture(SE-Conformer), incorporating a convolutional encoder–decoder and conformer, designed to be directly applied to the time-domain signal. We performed evaluations on both the VoiceBank-DEMAND Corpus(VCTK) and Librispeech datasets in terms of objective speech quality metrics. The experimental results show that the proposed model outperforms other competitive baselines in speech enhancement performance.
카카오엔터프라이즈 AI Lab에서 새롭게 제안하는 ‘SE-Conformer’는 음성 향상(SE, Speech Enhancement) 방법론입니다. 음성 향상 기술은 잡음(noise)이 포함된 음성 신호에서 잡음을 제거하여 음성 신호의 음질을 높이는 역할을 합니다. 실생활에서 녹음되는 음성에는 바람 등 주변 소리, 타인의 목소리 등 다양한 잡음이 섞이게 되는데, 이러한 음성 데이터를 음성 기반 애플리케이션에서 처리하기 위해서는 잡음을 제거하는 전처리 과정이 필수적입니다. 예를 들어 스마트 스피커의 경우, 인식해야되는 사용자의 음성에 잡음이 다수 섞여 있다면 인식 성능이 크게 낮아질 수 있기 때문에 음성 향상 기술이 중요한 역할을 하게 됩니다.
카카오엔터프라이즈 연구팀은 그동안 음성 처리 연구를 진행해오며, 전처리 기술로서 음성 향상 기술에 대한 연구를 지속해왔습니다. 이번 INTERSPEECH 2021을 통해 발표하게 된 새로운 음성 향상 방법론, SE-Conformer에 대한 내용을 간략하게 소개드리겠습니다.
1. 기존 음성 향상 기술 연구의 한계
기존 뉴럴넷(Neural Network) 기반의 음성 향상 기술은 주로 푸리에 변환(Fourier transform)을 사용하여, 주파수 대역에서 뉴럴넷을 처리하는 방식으로 연구가 진행되었습니다. 최근에는 음성 품질을 높이기 위해 잡음이 섞인 음성으로부터 깨끗한 신호를 뉴럴넷을 통해 직접 추정하는 음성 향상 기법들이 연구되고 있습니다. 그 중 푸리에 변환 대신 Convolutional Encoder-Decoder(CED) 구조를 사용하여 음성 파형을 처리하는 End2End 방식은 음성의 왜곡을 줄이고 품질을 높인다는 장점이 있습니다. 이에 카카오엔터프라이즈는 CED 구조를 기반으로 Conformer 네트워크를 활용하여 시간 영역에서 더욱 깨끗하게 음성의 잡음을 제거할 수 있는 새로운 방법론을 제안하였습니다.
2. SE-conformer 특징 소개
SE-conformer는 그림1과 같이 Encoder, Conformer block, Decoder로 구성되어 있습니다. 먼저 Encoder는 Upsampling block을 통하여 resolution을 증가시키고, 컨볼루션 연산 기반의 연산 (E-ConvBlock) 을 통하여 음성 신호를 latent representation으로 변환시켜주는 역할을 합니다.
그 후에 Conformer를 사용하여 잡음이 포함된 신호의 latent representation으로부터 깨끗한 신호의 representation을 추정합니다. Conformer는 Multi-Head Self-Attention 과 Depth-Wise 컨볼루션을 결합한 네트워크로, 연속적인 데이터에서 장단기 정보를 잘 반영하는데 적합하다고 알려져 있습니다.
마지막으로 Decoder는 Encoder와 반대 개념으로, conformer block의 아웃풋으로부터 깨끗한 신호를 복원하는 역할을 합니다. 트랜스포즈 컨볼루션 기반의 연산 (D-ConvBlock)을 통하여 latent representation을 다시 음성 신호로 복원시키고, Downsample block을 통해 resolution을 감소시켜 최종적으로 우리가 원하는 잡음이 제거된 깨끗한 신호를 얻을 수 있도록 네트워크를 구성합니다.
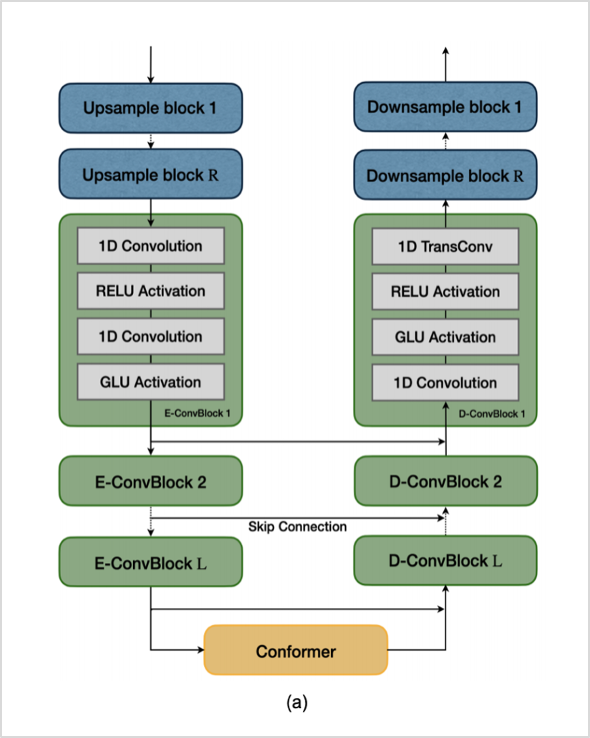
그림1. SE-Conformer 구조
3. 성능 평가
실험 결과는 VCTK 데이터셋과 LibriSpeech 데이터셋으로 측정되었습니다. VCTK 데이터의 깨끗한 음성 신호에 DEMAND 데이터셋의 잡음을 SNR 15, 10, 5, 0 dB로 섞어 학습 데이터셋을 생성하였으며, 학습에서 사용되지 않은 DEMAND 잡음을 2.5, 7.5, 12.5, 17.5 dB으로 섞어 테스트 데이터셋을 생성하였습니다. 성능은 음성 품질 측정을 위한 PESQ, 왜곡 측정을 위한 CSIG 외에 CBAK, COVL, STOI를 기준으로 측정되었으며, 제안하는 SE-conformer는 기존 연구 모델보다 평균적으로 우수한 성능을 보였습니다.
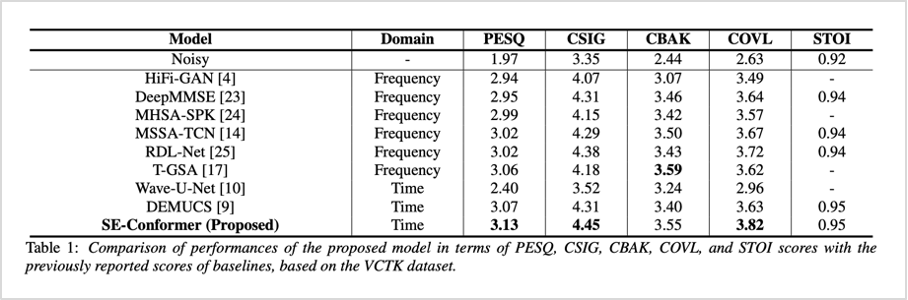
표1. SE-Conformer와 기존 방법론의 성능 비교 (VCTK 데이터셋 기준)
Large 데이터셋에서의 성능을 측정하기 위하여 LibriSpeech 데이터셋에서의 평가도 진행하였습니다. 학습 데이터셋을 생성하기 위해 LibriSpeech의 train-clean-100에서 랜덤하게 50h을 오디오 샘플을 선정하여 DEMAND 데이터셋과 MUSAN 데이터셋의 잡음과 -10 dB와 10dB로 섞었습니다. 테스트 데이터셋은 test-clean에서 랜덤하게 선정된 500개의 발화와 NOISEX-92 데이터셋과 DEMAND 데이터셋의 잡음을 -5, 0, 5, 10, 15 dB로 섞어 생성되었습니다. LibriSpeech 데이터셋에서도 기존 연구 모델 대비 우수한 성능을 나타내는 것을 확인할 수 있었습니다.
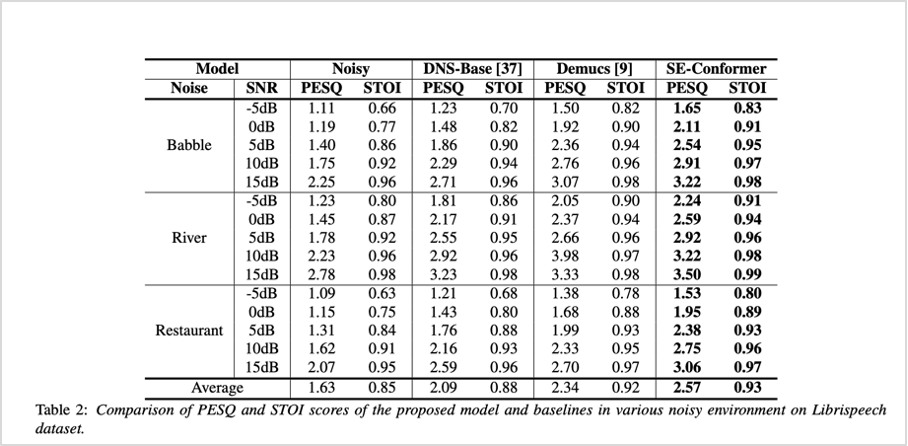
표2. SE-Conformer와 기존 방법론의 성능 비교 (LibriSpeech 데이터셋 기준)
4. 향후 계획
해당 연구 결과를 카카오 i 서비스에 적용하여 실제 사용자를 대상으로 더 나은 서비스를 제공하기 위한 연구를 이어나갈 계획입니다. 다양한 환경에서의 잡음을 실시간으로 제거해 음성의 품질을 높여 서비스의 만족도를 높이고, 모델 경량화를 통해 연산량 측면으로도 고도화시킬 예정입니다. 앞으로도 카카오엔터프라이즈 AI Lab 연구에 많은 관심 부탁드립니다. 감사합니다.