NLP
Auxiliary Sequence Labeling Tasks for Disfluency Detection
이동엽(카카오), 고병일(카카오엔터프라이즈), 신명철(카카오엔터프라이즈), 황태선(와이즈넛), 조재춘(한신대학교)Conference of the International Speech Communication Association (INTERSPEECH)
2021-08-30
Abstract
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. Existing works for disfluency detection have focused on designing a single objective only for disfluency detection, while auxiliary objectives utilizing linguistic information of a word such as named entity or part-of-speech information can be effective. In this paper, we focus on detecting disfluencies on spoken transcripts and propose a method utilizing named entity recognition(NER) and part-of-speech(POS) as auxiliary sequence labeling(SL) tasks for disfluency detection. First, we investigate cases that utilizing linguistic information of a word can prevent mispredicting important words and can be helpful for the correct detection of disfluencies. Second, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
그동안 카카오엔터프라이즈 AI Lab에서는 음성인식 영역과 자연어처리 분야에 활용 가능한 ‘사족제거(disfluency detection)’를 주제로, 연구를 진행해 왔습니다. 이번 INTERSPEECH 2021에서 NER(개체명 인식), POS(품사 태그) 정보를 활용해 사족제거 작업의 정확도를 높이는 새로운 방법론을 공개하게 되어, 해당 내용을 간략하게 소개드리고자 합니다.
1. 사족제거 연구의 필요성
먼저 사족제거 작업은 화자가 “음”, “아”와 같이 의미 없이 발화한 간투사를 교정하고, 발화 중 반복 사용한 표현들을 정제하는 과정을 말합니다. 예를 들어 “어… 오늘, 오늘은 날씨가 참 좋네”라는 문장에서 사족을 제거한다면, 별다른 의미를 가지지 않는 “어…”와 반복된 “오늘”을 삭제할 수 있습니다.
실제 발화 상황에서는 이와 같은 간투사나 숨소리, 머뭇거림 등 음성 전사 후 언어를 처리하는데 불필요한 발화가 다수 포함될 수 있습니다. 이런 발화를 음성인식 모델이 인식하고, 음성번역, 언어이해 등 자연어 처리(NLP)를 하기 위해서는 이러한 사족을 제거하는 작업이 필수적입니다.
2. 기존 사족제거 연구의 한계
기존 사족제거 연구는 word 단위의 자질(feature)을 각각 reparandum(RM), interregnum(IM), repair(RP)로 구분하여 우리가 제거해야할 대상(RM, IM)과 아닌 것(RP)을 명확히 파악하는데 초점을 두었습니다. IM에는 ‘음, 아’와 같은 간투사 표현들이 해당되고, 이들은 쉽게 구분되는 특성을 가졌기 때문에 IM보다는 주로 RM에 대한 예측정확도를 높이는데 중점을 둔 연구가 주를 이루고 있습니다. 여기서 RM은 쉽게 말해, 문장 시작에 들어가는 쿠션어, 반복어 표현들을 일컫는데, 먼저 입력된 값(RM)에 대해 오류라고 판단하고 뒤에 오는 값(RP)을 올바른 값으로 보았습니다. 기존 연구들은 이 RM을 파악하는데 목적을 두고, RM으로 분류된 정답 데이터를 학습하는 방식이 주로 활용되었습니다.

그림1. 기존 사족제거 연구의 어노테이션(annotation) 예시
하지만, 이와 같이 제거 대상만을 가려내는데 초점을 두면 중요한 의미를 가진 단어를 사족으로 오예측(false positive)하게 되고 예측정확도가 떨어질 수 있다는 한계점이 있습니다. 이에, 카카오엔터프라이즈 연구팀은 추가적인 정보들을 학습시켜 예측 성능을 높이는 방법론을 고안하였습니다.
3. Auxiliary Sequence Labeling Tasks 방법론 소개
카카오엔터프라이즈 연구팀이 새롭게 제안하는 방법론은 ‘Auxiliary Sequence Labeling Tasks’입니다. 기존 연구에서 추가적인 정보로 NER(개체명 인식, Named Entity Recognition), POS(품사 태그, Part-Of-Speech)를 Multi-Task Learning 방식에 활용해, 총 3개의 목적함수를 사용하여 학습을 진행하였습니다.
좀 더 자세히 살펴보면, 먼저 NER은 해당 단어의 개체명(Entity Name)이 인명, 장소, 시간 표현 등을 정의하는 과제(task)입니다. 그림2를 예시로 보면 NER 정보는 초록색으로 나타납니다. 기존 연구에서는 사족에 해당하는 ‘i would’를 명확히 파악하지 못하고, 오히려 문장의 중요한 의미를 담고 있는 ‘my forty’를 사족으로 오예측하였습니다. 본 연구에서는 이처럼 중요한 의미를 갖는 단어의 오예측을 방지하고, 정확한 사족 예측이 가능해지도록 NER 정보를 학습에 활용했습니다.
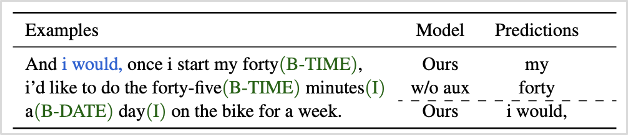
그림2. NER 정보 예시 (초록색이 NER에 해당하며, 파란색이 사족에 해당함)
또한, 추가적으로 사용된 POS는 각 문장 성분의 품사 태그 정보를 의미합니다. 그림3에서는 RM과 RP의 POS가 동일한 태그 형태를 가질 때, 보다 정확한 사족 예측이 가능함을 보여줍니다. 기존 연구에서도 POS를 활용한 연구들은 진행되었지만, rule-base 방식의 경우 단어 의미가 담긴 시맨틱 정보가 제대로 반영되지 않는다는 한계가 있었고, ML방식의 경우 추론(inference) 시 해당 입력 단어들에 대한 feature를 추출하기 위한 추가 시간이 소요된다는 문제가 있었습니다. 카카오엔터프라이즈 연구팀은 POS와 NER 정보를 추가 활용하는 Auxiliary Sequence Labeling Tasks 방법론을 새롭게 제안하여 그동안의 문제점들을 해결하고 더 높은 성능을 얻고자 하였습니다.

그림3. POS 정보 예시
본 연구에서는 사족제거, NER, 그리고 POS태그들을 예측을 위해 3가지의 negative log likelihood loss 함수를 사용하였습니다. 사족제거, NER, 그리고 POS 테스크를 위한 loss 함수들을 각각 Ld, Le, Lp라고 정의할때, 최종 loss 함수는 L= Ld + *(Le +Lp)로 정의합니다. 여기서 는 계수(coefficients)로써, NER과 POS 테스크들의 영향도를 학습에 얼마나 반영할지 결정하는 요소입니다.
4. 성능 평가
제안한 방법의 성능평가를 위해 기존 연구와의 모델 성능비교와 학습요소별 성능비교 2가지 방식을 이용하였습니다. 먼저 동일한 CRF Layer(Decoder)에 입력 자질(feature input)로 사전훈련된 언어모델 transformer, BERT, ELECTRA의 최종 output layer를 사용하여 각각의 성능을 비교해 보았습니다. 현재 성능 테스트에 많이 활용되고 있는 English Switchboard 데이터셋을 활용하여 테스트해본 결과, F1 score에서 기존 연구 모델보다 평균적으로 높은 수치를 기록하는 것을 확인할 수 있었고, 최고치의 경우 93.1(ELECTRA)에 달하는 우수한 결과를 얻었습니다.
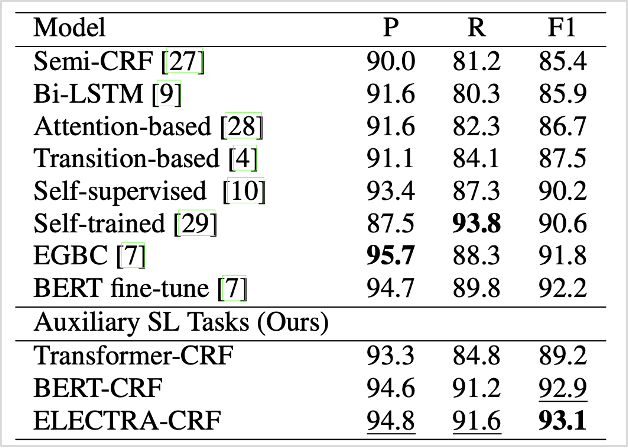
표1. 기존 방식으로 학습된 모델과 Auxiliary SL(Sequence Labeling) Tasks 방식으로 학습된 모델의 성능 비교
다음으로, 동일한 English Switchboard 데이터셋을 이용해 Ablation 분석을 진행하였습니다. 1)기존 연구 방식으로 학습된 모델, 2)NER을 추가한 경우, 3)POS를 추가한 경우, 4)AUXILIARY SL Tasks 방식(NER과 POS를 모두 추가, SL : Sequence Labeling)을 각각 비교해 보았습니다. 표2에서 볼 수 있듯이 추가 정보를 모두 활용한 경우가 F1 score에서 가장 높은 수치를 기록하였습니다.
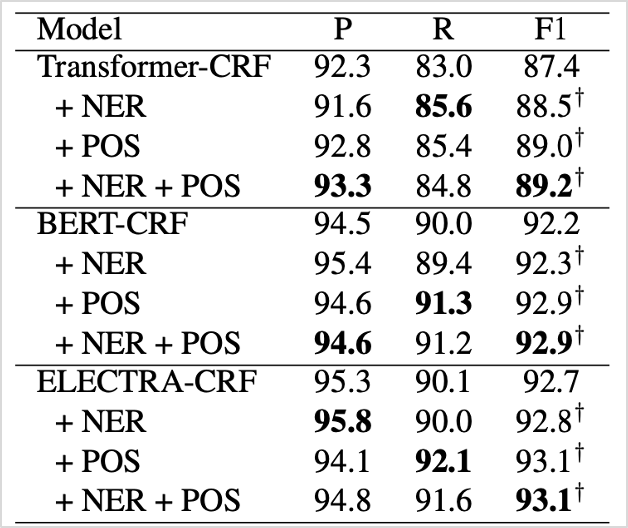
표2. Ablation Analysis 분석 결과
이를 통해 추가 정보를 활용하여 목적함수를 확대하는 것이 실제 성능에 영향력을 미친다는 것을 확인할 수 있었다는 점에서 해당 연구가 갖는 의의가 크다고 볼 수 있습니다.
추론에서도 본 연구의 장점이 있습니다. 기존의 연구에서도 이와 비슷하게 모델의 입력으로 단어의 NER과 POS와 같은 추가 자질들을 사용하는 방법들이 있었지만, 이러한 방법들은 추론시, 단어의 자질들을 추출하는데 추가 시간이 필요한 단점이 있습니다.하지만 본 연구에서는 NER와 POS tasks를 학습시간에만 활용하고, 추론시에는 사용을 하지 않기 때문에 추론 시간을 단축시키는 효과가 있습니다. 그 결과, 아래의 표3과 같이 추론을 위해 추가적으로 요구되는 시간은 없다는 것을 알 수 있습니다.

표3. Auxiliary SL Tasks를 활용한 방식(Ours)과 활용하지 않은 방식(Ours w/o aux)간의 추론 속도 비교
5. 향후 연구 계획
해당 연구는 현재 헤이카카오앱 중 받아쓰기 기능에 적용되었고, 녹음 내용을 전사한 결과에 사족제거기능으로 활용되고 있습니다. 향후 한국어 서비스 고도화를 위해 한국어용 사족제거 모델 개선에 집중하고 유의미한 성능을 얻을 수 있도록 연구를 발전시켜나갈 계획입니다. 앞으로도 많은 관심 부탁드립니다. 감사합니다.