SPEECH/AUDIO
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
장원(카카오엔터프라이즈), 임단(카카오), 윤재삼(카카오엔터프라이즈), 김봉완(카카오엔터프라이즈), 김준태(카카오엔터프라이즈)Conference of the International Speech Communication Association (INTERSPEECH)
2021-08-30
Abstract
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
카카오엔터프라이즈 AI Lab 음성처리팀은 카카오 i에 적용되는 TTS(Text to Speech) 연구를 진행해오고 있습니다. TTS 시스템은 크게 텍스트에서 acoustic feature를 생성하는 어쿠스틱 모델(acoustic model)과 이 스펙트로그램에서 음성신호를 합성해 AI 음성을 만들어내는 보코더(vocoder)로 구성됩니다. 여기서 보코더는 고품질의 음성을 생성하는데 주요한 역할을 담당하고 있습니다.

그림1. TTS 구조
카카오엔터프라이즈 연구팀은 기존 연구보다 개선된 고품질 음성 합성을 가능케하는 뉴럴 보코더 기술 ‘UnivNet’을 고안해, 이번 INTERSPEECH 2021에서 연구 내용을 공개하게 되었습니다. 지난해 음성합성 모델과 음소-오디오 정렬 모델을 한꺼번에 훈련하는 아키텍처 ‘JDI-T’를 공개한데 이어, 2년 연속 연구 성과를 발표하게 되었습니다. 본 글에서는 이번 연구 성과에 대해 간략하게 소개드리고자 합니다.
1. 기존 뉴럴 보코더 연구의 한계
대다수 뉴럴 보코더(neural vocoder) 연구에서는 전체 주파수 대역 중 일부(0-8kHz)에 해당하는 멜 스펙트로그램(mel-spectrogram)을 입력값으로 사용하고 있습니다. 여기서 멜 스펙트로그램은 인간의 인지 기준에 따라 헤르츠(Hz) 단위의 주파수를 mel-scale에 따라 변환한 값으로, 딥러닝에서 오디오 신호 처리에 많이 활용되는 피쳐(feature)입니다. 일반적으로 사람들은 고주파보다 저주파를 잘 인지하기 때문에, 스펙트로그램의 저주파 부분을 보다 잘 인식할 수 있도록 저주파 부분을 확장시킨 점이 특징입니다.
이때, 전체 대역폭을 입력값으로 사용하면 음향정보가 더욱 많아져 깨끗한 음성을 얻을 수 있음에도 불구하고, 일부값만이 활용되었습니다. 전체 값을 활용한 일부 연구에서는 합성 음성의 고주파수 대역이 흐릿해지는 문제(over smoothing)가 발생해, 음성에 지지직거리는 소리 등 잡음이 섞여 기대했던 것 이상의 음성 품질을 얻기 어려운 경우들이 있었습니다.
카카오엔터프라이즈 연구팀은 이같은 문제를 해결하고자 새로운 뉴럴 보코더 방법론 ‘UnivNet’을 고안해, 실시간 서비스에서 더욱 깨끗한 음성을 제공하고자 하였습니다.
2. UnivNet 특징 소개
먼저 UnivNet의 구조는 <그림2>와 같이 크게 생성기(generator)와 판별기(discriminator)로 구분됩니다. generator는 MelGAN 기반 구조이며, 여기에 더해 모델의 크기를 유지하면서도 효과적으로 로컬 정보를 확보하기 위해 LVC(Location-Variable Convolution)를 추가하였습니다. 이로 인해 mel-spectrogram의 지역별 정보를 효율적으로 모델에 제공하여, 더 적은 파라미터 수로도 더 높은 음질을 얻을 수 있었습니다. 또한, 효율적인 연산을 위해 GAU(Gated Activation Unit)를 더했습니다.
다음으로 discriminator에서는 generator에서 생성된 가짜 데이터와 실제 데이터를 구별하도록 학습을 진행합니다. 여기서 주목할 점은 multi-resolution spectrogram discriminator(이하 MRSD)를 사용했다는 것입니다. MRSD는 다양한 STFT 파라미터셋을 사용하여 실제 데이터와 생성된 가짜 데이터의 여러 선형 스펙트로그램 크기들을 계산해, 각 하위 판별기에 입력값으로 활용합니다. 이때, STFT 파라미터셋에는 1)푸리에 변환 차수, 2)시간(frame) 이동 간격, 3)윈도우(window) 길이가 포함됩니다.
UnivNet은 MRSD 구조를 통해 전체 대역폭 데이터가 가진 다양한 시간과 해상도(resolution) 정보를 사용하여 실제 사람 음성과 같은 높은 수준의 음성을 생성하고자 하였습니다. MRSD 구조는 MelGAN의 multi-scale waveform discriminator(MSWD) 구조에 기반하며, 여기에 시간 영역에서 적대적 모델링을 개선하기 위해 multi-period waveform discriminator(MPWD)를 더한 점이 특징입니다.
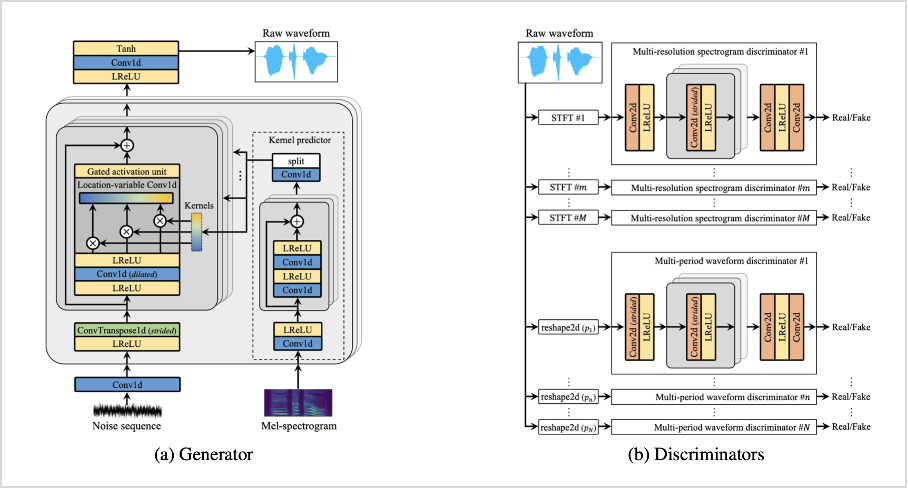
그림2. UnivNet 구조
3. 실험 결과
1) 데이터 구성
해당 실험에는 LibriTTS 데이터셋을 활용하였습니다. LibriTTS 데이터셋은 영어 오디오북 데이터셋으로, 이 중 192시간 분량, 11만 6천개의 발화, 904명의 화자 데이터로 구성된 ‘train-clean-360’을 바탕으로 모델 훈련을 진행하고, 이미 아는 화자(seen speaker)에 대한 평가를 진행하였습니다. 9시간 분량, 4천개의 발화, 39명의 화자 데이터로 구성된 ‘train-clean’ 데이터셋으로는 처음 보는 화자(unseen speaker)에 대한 평가를 진행하였습니다. 또한, TTS 성능 평가를 위해서는 24시간 분량, 1만 3천개 발화 데이터로 구성된 LJSpeech 데이터셋을 활용하였습니다. 해당 데이터셋은 영어로 구성된 단일 화자의 데이터셋입니다.
2) Ablation study
먼저 해당 모델의 자체 성능을 파악하기 위해 Ablation study를 진행하였습니다. 각 구성요소는 G1=LVC, G2=GAU, D1=MRSD, D2=MPWD, D3=MSWD와 같습니다. 여기서 주목할 점은 <표1>에서 D1(MRSD)이 제거되면 <그림3>의 왼쪽 그림과 같이 생성된 음성의 고주파수 대역이 흐릿해지는 문제가 발생한다는 점입니다. 제안하는 모델의 결과를 나타내는 <그림3>의 가운데 그림을 보면 이러한 문제가 개선되어 실제 녹음 음성의 고주파수 대역과 비슷해진 점을 볼 수 있습니다. 이를 통해 Univnet 모델에서 MRSD 구조가 가지는 중요성을 확인할 수 있었습니다.
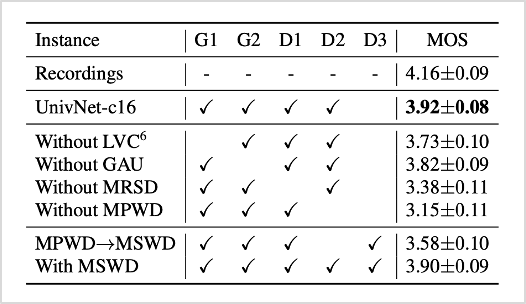
표1. Ablation study 결과
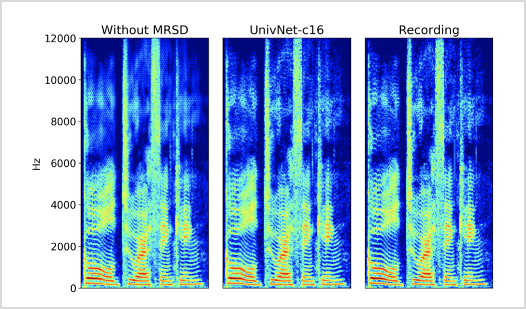
그림3. 오디오 클립에서 생성된 스펙트로그램
3) 기존 보코더 모델과 성능 비교
다음으로는 generator의 채널 크기가 다른 두 가지 버전의 UnivNet(UnivNet-16, UnivNet-32)을 준비하여 GAN 기반 보코더(MelGAN, Parallel WaveGAN, HiFi-GAN)와 성능을 비교해보았습니다.
보코더 자체의 성능을 평가하기 위해 실제 화자의 음성(Seen/Unseen speakers)에서 추출된 멜 스펙트로그램을 보코더를 이용하여 음성을 생성하는 과정을 진행하였습니다. <표2>를 보면 UnivNet-16은 학습 때 활용된 화자 데이터 외에 처음 보는 화자 데이터에서도 우수한 품질의 음성을 생성하였습니다. 기존 보코더 모델의 경우 새로운 화자가 추가될 때마다 모델을 추가 학습해야 하는 불편함이 있었지만, UnivNet은 처음 보는 화자 데이터에서도 우수한 성과를 보였다는 점에서 이같은 문제를 상당수 개선하였다고 볼 수 있습니다. 또한, UnivNet-32의 경우 전체 분야에서 기존 보코더 모델보다 높은 점수를 기록하고, 추론 속도도 다소 절감시키는 등 의미있는 결과값을 얻었습니다. 이어 진행된 TTS 성능 평가에서도 UnivNet-32은 우수한 성능을 보이며, 보코더 성능뿐만 아니라, 실제 TTS 구조 상에서도 높은 성능을 보여줌을 확인하였습니다.
해당 연구는 기존 보코더 모델보다 더 많은 대역폭을 쓰면서도 over-smoothing 문제 없이 더 깨끗한, 선명한 합성음을 얻었다는 점에서 의의가 있습니다. 또한, 음성 합성 분야에서 합성음의 품질뿐만 아니라, 중요한 추론 속도를 절감시켰다는 점도 주목할만합니다.
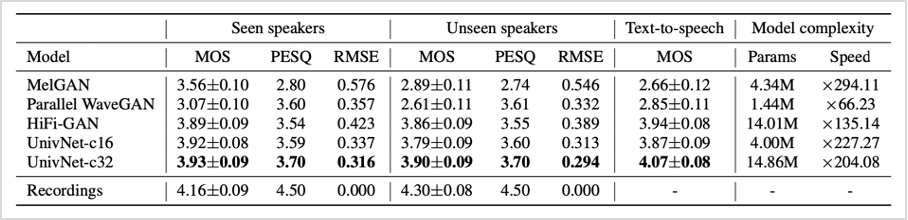
표2. 기존 보코더 모델과 성능 비교
4. 향후 계획
향후 UnivNet은 카카오 i 서비스에 적용되어 실제 다수의 사용자를 대상으로 서비스될 예정입니다. 합성음의 명료도와 자연성이 실제 사람의 발화 수준과 동일할 정도로, 그 품질을 향상시키기 위해 지속 연구할 계획입니다. 또한, fine-tuning 과정 없이도 여러 화자의 TTS 파이프라인에 활용할 수 있는 유니버셜 보코더 연구를 진행하고자 합니다. 앞으로도 카카오엔터프라이즈의 음성처리 연구에 많은 관심 부탁드립니다. 감사합니다.