COMPUTER VISION
Learning Debiased Representation via Disentangled Feature Augmentation
이정수(카이스트, 카카오엔터프라이즈), 김응엽(카이스트, 카카오엔터프라이즈), 이주영(카카오엔터프라이즈), 이지현(카이스트), 주재걸(카이스트)Neural Information Processing Systems (NeurIPS) Oral
2021-12-06
Abstract
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with “diverse” bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on both synthetic as well as real-world datasets.
본 글에서는 카카오엔터프라이즈와 카이스트 공동 연구팀이 데이터셋의 편향(bias) 문제를 개선하기 위해 새롭게 제안한 데이터 증강(data augmentation) 기법을 소개드리고자 합니다. 해당 연구 결과는 NeurIPS 2021 학회에서 oral presentation을 통해 공개되었습니다.
1. 기존 편향성 개선 연구의 한계
데이터셋의 편향 문제는 이미지 분류 모델의 학습 과정에서 흔하게 발생됩니다. 데이터를 수집, 가공하는 과정에서 자연스럽게 존재하게 되는 bias로 인해, 모델의 성능이 크게 좌우될 수 있습니다. 이로 인해 훈련 과정에서는 높은 정확도를 보였던 모델이 실제 편향되지 않은 데이터셋에 적용될 때, 낮은 성능을 보일 수 있는데요. 예를 들어 ‘새’ 이미지를 학습하는 과정에서 학습한 모든 이미지에 ‘하늘’이 있었다면, 하늘과 함께 있는 물체만 새로 인식하여 ‘땅’ 또는 ‘풀’ 위에 있는 새는 분류에 실패할 수 있습니다. 학습자의 의도와 관계 없이, 데이터셋 자체에 존재하는 편향성에 의해 모델의 성능이 저하될 수 있는건데요.
기존 연구들은 이러한 편향성을 제거하기 위해, 편향성을 제거한 샘플(bias-conflicting sample)을 추가하거나, 가중치를 조정하는 방식을 활용했습니다. 사실상 bias-conflicting 샘플을 수집하는 데에는 물리적, 시간적 어려움이 있기 때문에 이러한 방식에는 한계가 있었습니다.
2. 다양한 bias-conflicting 샘플의 중요성
딥러닝 학습에 있어 알고리즘 이상으로 중요한 것은 바로 데이터의 양입니다. 많은 데이터를 잘 활용하는 것이 모델의 성능을 좌우하는데요. 이에 공동 연구팀은 편향성 개선을 위해서는 ‘다양한 bias-conficting 샘플을 많이 활용하는 것이 모델 학습에 효과적’이라는 가설을 가지고, 이를 검증하기 위한 토이셋(toy-set) 실험을 진행하였습니다.
먼저 훈련 과정에는 그림1과 같이 두 가지 데이터셋(Colored MNIST, Corrupted CIFAR-10)을 활용하였습니다. 하나는 기존 MNIST 데이터셋에서 숫자에 특정 색상이 자주 나오도록 색상 bias를 설정한 Colored MNIST이고, 다른 하나는 기존 CIFAR-10 데이터셋에서 사물에 특정 텍스쳐(Corruption)가 반복되도록 텍스쳐 bias를 변형한 Corrupted CIFAR-10입니다.

그림1. 데이터셋 형태 (점선 위는 기존 bias-aligned 샘플이며, 점선 아래는 bias-conflicting 샘플임)
아래 표1은 해당 데이터셋으로 학습한 모델에 편향성이 없는 테스트셋(unbiased test sets)을 적용했을 때의 분류 정확도를 나타냅니다. 다양한 bias-conflicting 샘플을 학습에 많이 활용한 경우가 가장 높은 정확도를 보였습니다. 여기서 주목할 점은 바로 샘플링 비율보다 다양성 비율이 높았을 때, 상대적으로 높은 정확도를 보였다는 점입니다.
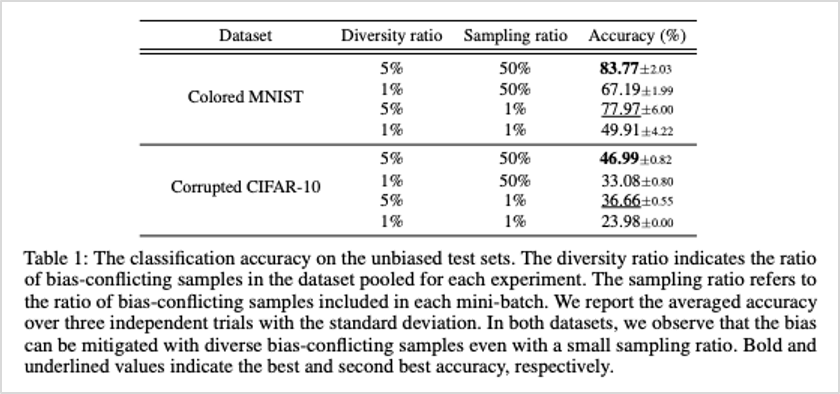
표1. 편향성이 없는 테스트셋(unbiased test sets)에서의 분류 정확도
이를 통해 본 연구팀은 다양한 bias-conflicting 샘플의 활용이 편향 제거에 효과가 있다는 가설을 검증하였고, bias-conflicting 샘플 데이터의 증강을 통해 편향성을 개선한 방법론을 제안하였습니다.
3. Debiasing via disentangled feature augmentation 방법론 소개
해당 방법론의 가장 큰 특징은 각 이미지가 가진 고유속성과 편향속성을 교차합성하여 데이터를 증강시켰다는 점입니다.
전체 구조를 살펴보면 각각 고유속성(\(E_{i}\)), 편향속성(\(E_{b}\))으로 구분되는 2개의 인코더가 있습니다. 하나의 이미지가 입력되면 해당 인코더를 거쳐 각각 고유속성과 편향속성의 disentangled feature로 \(Z_{i}\), \(Z_{b}\)가 출력됩니다.
여기서 고유속성과 편향속성의 disentanglement를 학습하기 위해, 다음과 같은 학습과정을 진행합니다. 먼저 고유속성을 학습하는데 사용되는 \(E_{b}\)와 \(C_{b}\)를 기존 논문(Nam et al., “Learning from Failure: Training Debiased Classifier from Biased Classifier”)에서 제시한 Generalized Cross-Entropy Loss를 통해 “쉬운” 정보만을 학습하도록 강제합니다. 이를 통해 해당 인코더는 주어진 이미지로부터 편향속성을 주로 추출하게 되고, 이렇게 편향 학습된 인코더로부터 상대적으로 큰 Loss를 갖게 되는 이미지를 Bias-conflicting 샘플로 판단할 수 있게 됩니다. 이러한 이미지들에 대한 가중학습을 통해, \(E_{i}\)와 \(C_{i}\)는 편향속성이 아닌 고유속성을 주로 추출하는데 사용됩니다.
이때, 이 한 쌍의 피쳐들을 미니배치 내 다른 랜덤 이미지의 피쳐값과 교차 합성(swapping)을 함으로써 기존 고유속성과 편향속성 간의 강한 상관관계(correlation)가 끊어진 샘플을 생성할 수 있는데요. 이는 곧 편향성을 가지지 않는 새로운 bias-conflicting 샘플을 의미합니다. 이 과정을 통해 실제 편향성 개선에 효과적인 유의미한 합성 결과물을 구현할 수 있었습니다. 또한, 데이터 증강으로 훈련 데이터셋의 다양성을 증가시키고, 데이터의 품질 또한 높여 분류 정확도를 향상시킬 수 있었습니다.
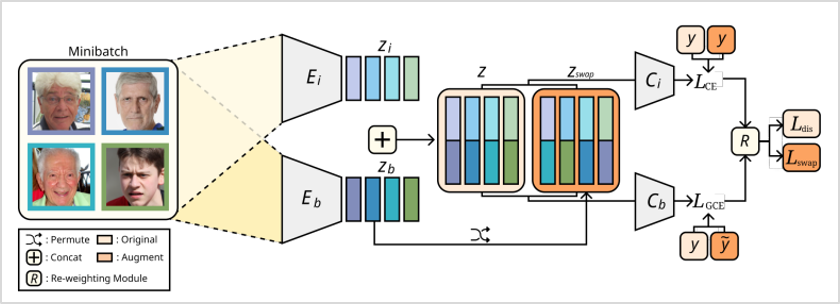
그림2. 전체 모델의 구조
4. 성능 평가
보다 정량적인 성능 평가를 위해, 앞서 언급한 2가지 합성 데이터셋(Colored MNIST, Corrupted CIFAR-10)과 함께 BFFHQ 데이터셋을 활용하여 실험을 진행하였습니다. 여기서 BFFHQ는 기존 FFHQ 데이터셋이 가진 나이와 성별 편향성(대다수 데이터가 젊은 여자와 나이 든 남자로 구성됨)에 변형을 둔 데이터셋입니다.
이 세가지 데이터셋으로 학습한 모델을 각각 편향성이 없는 테스트셋으로 평가했을 때, 아래 표2와 같이 SOTA(State-of-the-art)를 뛰어넘는 우수한 성능을 보임을 확인하였습니다. 해당 방법론은 합성 데이터셋 뿐만 아니라 실서비스 상의 데이터셋에도 효과적이라는 사실을 알 수 있었습니다.
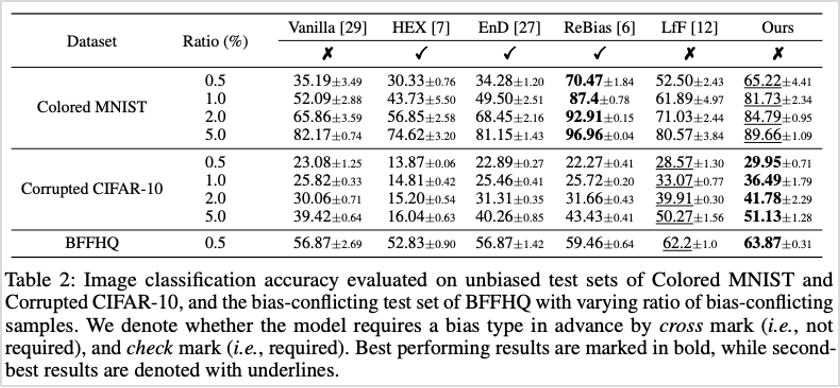
표2. 편향성이 없는 테스트셋(unbiased test sets)으로 평가한 분류 정확도
5. 향후 연구 계획
Dataset Bias 문제 해결은 이미지 인식, 얼굴 인식 등 여러 컴퓨터 비전 과제를 해결하는데 큰 역할을 할 수 있습니다. 예를 들어 앞서 언급한 이미지 분류 문제에서 오식률을 개선하고, 모델의 성능을 높이는 데에도 활용될 수 있는데요. 보다 구체적으로는 딥러닝 모델이 성별, 인종, 나이 등과 같이 편향과 관련된 여러 민감한 문제에 대해 보다 신뢰성 높은 정답을 도출할 수 있도록 기여할 수 있을 것으로 기대됩니다.
향후 카카오엔터프라이즈 AI Lab 비전팀은 해당 방법론을 기반으로 여러가지 컴퓨터 비전 문제를 해결하고, 서비스를 고도화할 계획입니다. 앞으로도 카카오엔터프라이즈 연구에 많은 관심과 응원 부탁드립니다. 감사합니다.
현재 카카오엔터프라이즈 AI Lab에서는 다양한 AI 연구와 서비스화를 함께 고민해나갈 여러분의 지원을 기다리고 있습니다. AI를 통해 더욱 가치있는 세상을 만들고, 꿈을 현실로 만들어가는 여정에 함께하세요!
👨🏻💻 인재영입