COMPUTER VISION
SmoothMix: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness
정종현(카이스트), 박세준(카이스트), 김민규(카이스트), 이흥창(카카오엔터프라이즈), 김도국(카카오엔터프라이즈), 신진우(카이스트)Neural Information Processing Systems (NeurIPS)
2021-12-06
Abstract
Randomized smoothing is currently a state-of-the-art method to construct a certifiably robust classifier from neural networks against \(l_{2}\)-adversarial perturbations. Under the paradigm, the robustness of a classifier is aligned with the prediction confidence, i.e., the higher confidence from a smoothed classifier implies the better robustness. This motivates us to rethink the fundamental trade-off between accuracy and robustness in terms of calibrating confidences of smoothed classifier. In this paper, we propose a simple training scheme, coined SmoothMix, to control the robustness of smoothed classifiers via self-mixup: it trains convex combinations of samples along the direction of adversarial perturbation for each input. The proposed procedure effectively identifies over-confident, near off-class samples as a cause of limited robustness in case of smoothed classifiers, and offers an intuitive way to adaptively set a new decision boundary between these samples for better robustness. Our experimental results demonstrate that the proposed method can significantly improve the certified \(l_{2}\)-robustness of smoothed classifiers compared to existing state-of-the-art robust training methods.
본 글에서는 카카오엔터프라이즈와 카이스트, Vector Institute 공동 연구팀이 강건한 분류기 구축을 위해, 새롭게 제안하는 적대적 학습(adversarial training) 기법을 소개드리려고 합니다. 해당 연구 결과는 NeurIPS 2021 학회를 통해 공개되었습니다.
1. 적대적 학습 기법의 필요성
일반적으로 딥러닝 모델은 훈련 과정에서 예측값에 대해 과잉 확신(over-confidence)을 가지는 경향이 있습니다. 이로 인해 틀린 답을 정답으로 간주하는 큰 문제를 야기할 수 있는데요. 이같은 문제 해결을 위해 적대적 학습 기법이 등장하였습니다.
적대적 학습 기법은 원본 데이터에 최적의 노이즈를 추가한 적대적 샘플을 통해, 딥러닝 모델의 오예측을 유도하는 훈련 방법론입니다. 실제 사람이 보기에는 크게 문제가 없는 수준의 노이즈더라도, 노이즈로 인해 왜곡된 이미지는 모델 예측에 악영향을 끼칠 수 있습니다. 이처럼 예측이 어려운 적대적 샘플을 통해 학습을 진행하고, 이를 방어하기 위한 목적함수를 조정하는 적대적 학습 기법을 활용해 정확도를 한층 높인 강건한 분류기를 구축할 수 있습니다.

그림1. 맨 왼쪽 그림은 57.7%의 confidence로 판다라고 인식하지만, 중간에 노이즈를 추가한 오른쪽 그림은 유관상으로는 같은 그림 같아 보이지만 모델은 99.3%의 confidence로 긴팔원숭이로 분류하는 걸 확인할 수 있습니다. [Goodfellow et al., 2014]
2. 기존 적대적 학습 기법 연구의 한계
기존 연구들은 학습 과정에서 적대적 입력으로 데이터를 증강하는 학습 기법 [Madry et al., 2018]을 널리 사용해 왔습니다. 이에 비해 가우시안(Gaussian) 랜덤변수를 표방한 무작위 평활화(randomized smoothing) 기법은 충분히 연구되지 못했습니다.
무작위 평활화 기법은 현재 가장 강력한 perturbation으로 알려진 \(l_{2}\) adversarial perturbations에도 강건한 분류 성능을 보이는 SOTA(State-of-the-art) 방법론입니다. 최근 등장한 SmoothAdv 방법론 [Salman et al., 2019]은 무작위 평활화 기반 분류기에 직접적으로 적대적 학습을 적용해, 모델 성능이 향상될 수 있음을 보였습니다. 하지만, 이는 이미 지역적으로 강인성을 확보하고 있는 평활 분류기에 여전히 기존 방법론의 지역적 검색을 사용하는 등 일반 분류기와의 차이를 고려하지 못했다는 한계가 있었는데요. 이에 본 연구팀은 평활화 기반 분류기의 특성을 고려한 적대적 학습 기법을 새롭게 제안하고자 합니다.
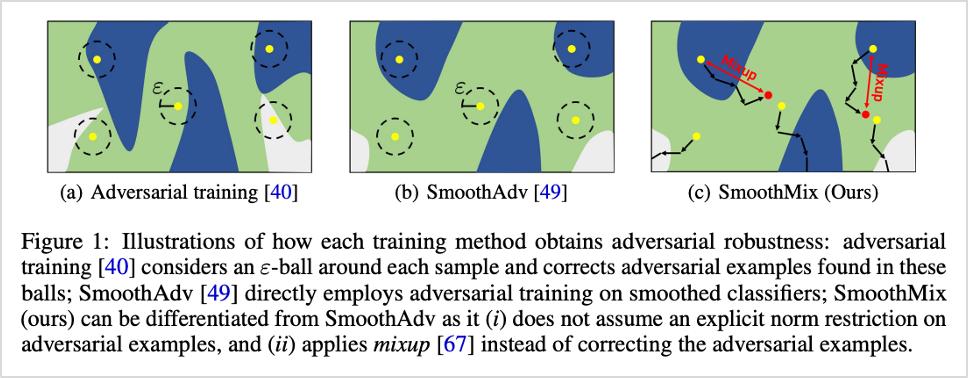
그림2. 기존 적대적 학습 기법(a, b)과 제안 방법론(c)에 대한 시각화
3. SmoothMix 방법론 소개
SmoothMix의 가장 큰 특징은 적대적 입력 탐색에서 지역적 검색을 사용하지 않고, 해당 입력값과 원본 입력값 간의 mixup 학습 구조를 가진다는 점입니다.
이를 자세히 살펴보면, SmootMix는 기존 적대적 학습 기법에서 사용되었던 제한된 ε-ball 내부에서의 검색을 사용하지 않는 대신, 주어진 입력 x 주변의 over-confident한 입력을 찾습니다.

이때 over-confident 입력값을 학습에 적용하기 위해, confidence 값을 uniform prediction으로 penalize하는데요. 해당 값과 원본 입력값 간의 차이를 측정하여 mixup [Zhang et al., 2017] 목적함수를 최소화하는 정규화 기법을 사용합니다. 이를 통해 두 입력값 간의 confidence를 조정하여 기존 적대적 학습 기법 대비 분류기의 강건함을 향상시켰습니다.
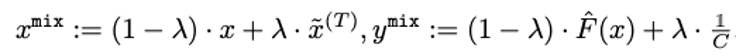
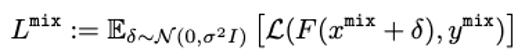
또한, SmoothMix는 SmoothAdv 기법을 통해 효과를 입증한 mixup 목적함수에 ‘single-step adversarial example’ 기법을 추가 제안하여 더욱 강건한 분류기 구조를 구성하였습니다.
4. 성능 평가
해당 방법론은 MNIST, CIFAR-10, ImagNet 등의 이미지 분류 데이터셋에서 기존 방법론 대비 높은 성능을 보였습니다. 특히 모델의 정확도와 강인성의 최적 정도를 보여주는 ACR(Average Certified Radius) 수치를 평가하였고, 아래 표2, 표3과 같이 현재 SOTA(State-of-the-art)와 비교해 우수한 성능을 확인하였습니다.
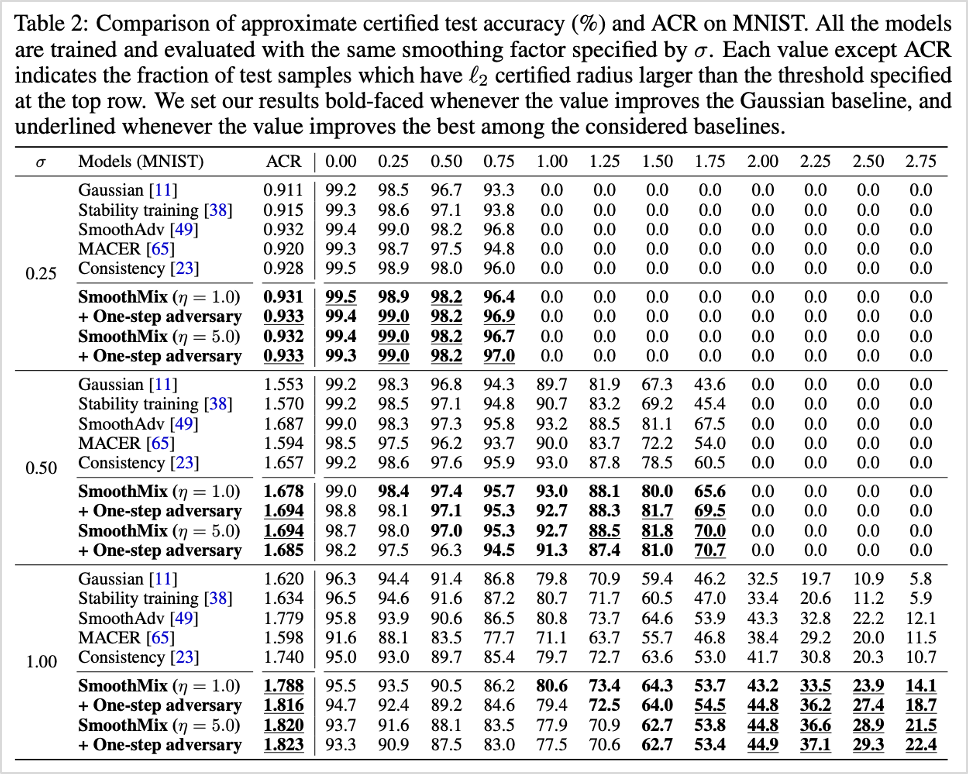
표1. 기존 방법론과의 성능 비교 (MNIST 데이터셋 기준)
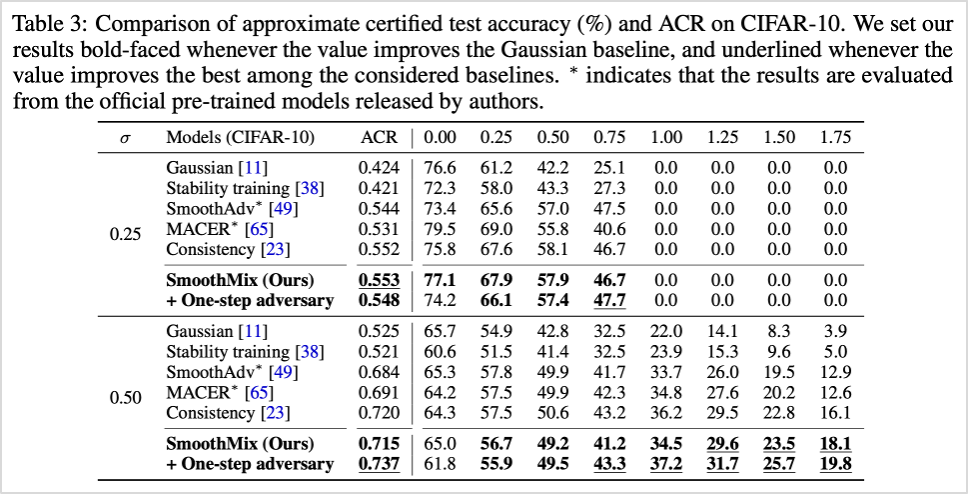
표2. 기존 방법론과의 성능 비교 (CIFAR-10 데이터셋 기준)
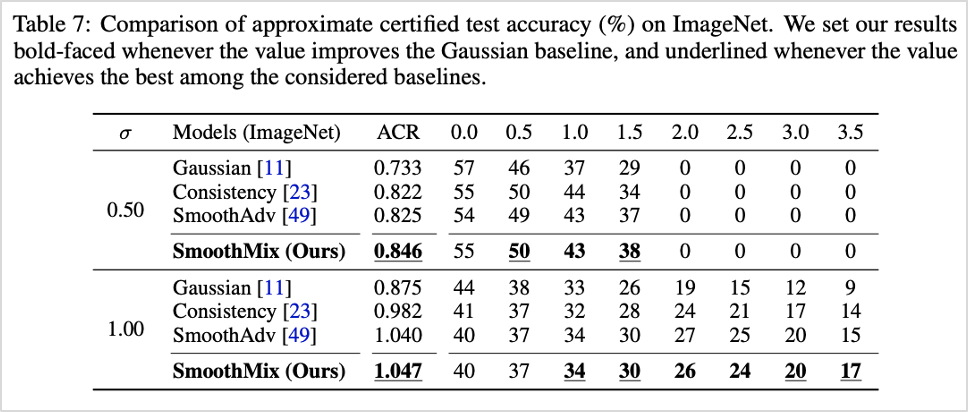
표3. 기존 방법론과의 성능 비교 (ImageNet 데이터셋 기준)
5. 향후 연구 계획
적대적 학습 기법은 노이즈에 강력한 모델을 구축하는데 큰 역할을 할 수 있습니다. 이로 인해 모델이 처음 보는 실서비스 데이터에서도 우수한 성능을 보일 수 있는데요. 이 기법은 다양한 AI 분야에 활용이 가능하지만, 특히 자율주행차, 의료 시스템 등 높은 정확도를 요구하는 영역에서 오판단을 줄여 그 성능을 크게 발휘할 수 있습니다.
향후 카카오엔터프라이즈 연구팀은 해당 방법론을 기반으로 여러가지 컴퓨터 비전 문제를 해결하고, 서비스를 고도화해 나갈 계획입니다. 앞으로도 카카오엔터프라이즈 연구에 많은 관심과 응원 부탁드립니다. 감사합니다.
참고문헌
- [Goodfellow et al., 2014] Explaining and harnessing adversarial examples. arXiv 2014.
- [Madry et al., 2018] Towards Deep Learning Models Resistant to Adversarial Attacks, ICLR 2018.
- [Salman et al., 2019] Provably robust deep learning via adversarially trained smoothed classifiers, NeurIPS 2019.
- [Zhang et al., 2017] mixup: Beyond Empirical Risk Minimization, ICLR 2018.
현재 카카오엔터프라이즈 AI Lab에서는 다양한 AI 연구와 서비스화를 함께 고민해나갈 여러분의 지원을 기다리고 있습니다. AI를 통해 더욱 가치있는 세상을 만들고, 꿈을 현실로 만들어가는 여정에 함께하세요!
👨🏻💻 인재영입