SPEECH/AUDIO
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
공정일(카카오엔터프라이즈), 김재현(카카오엔터프라이즈), 배재경(카카오엔터프라이즈)Neural Information Processing Systems (NeurIPS)
2020-12-15
최근 음성합성 연구에서는 GANgenerative adversarial networks 구조를 활용해 보코더vocoder의 음성 합성 속도와 메모리 효율을 높이는 시도가 있었습니다. 하지만 이런 방식의 보코더가 합성한 음성의 품질은 Autoregressive 모델이나 플로우 기반의 생성 모델flow-based generative model에 미치지 못했습니다.
이에 카카오엔터프라이즈는 음성 오디오의 주기적 신호를 구별해내는 방식으로 기존 제안된 모델보다 월등히 좋은 품질의 오디오를 빠르게 합성하는 HiFi-GAN을 제안했습니다.
카카오엔터프라이즈는 메모리 효율성 및 속도와 관련된 초매개변수hyperparameter를 조정하고, 이 값을 조합한 3가지 버전의 세부 모델로 실험을 진행했습니다. 첫 번째 버전은 인간과 비슷한 수준의 고품질 오디오를 실시간의 167.9배 속도로 합성합니다. 두번째 버전은 비교 모델 중 가장 적은 매개변수를 사용하면서도 가장 좋은 음질을 생성합니다. 세 번째 버전은 GPU에서 실시간의 1,186.8배, CPU에서 13.4배 더 빠르게 기존 모델과 비슷한 품질의 오디오를 합성합니다.
카카오엔터프라이즈는 이번 연구로 얻은 기술력과 경험을 바탕으로 음질 개선, 맥락에 따라 다양한 스타일의 발화 생성 등 다양한 태스크를 수행하는 오디오 합성 기술을 연구할 계획입니다.
Abstract
Several recent studies on speech synthesis have employed generative adversarial networks (GANs) to produce raw waveforms. Although such methods improve the sampling efficiency and memory usage, their sample quality has not yet reached that of autoregressive and flow-based generative models. In this study, we propose HiFi-GAN, which achieves both efficient and high-fidelity speech synthesis. As speech audio consists of sinusoidal signals with various periods, we demonstrate that modeling periodic patterns of an audio is crucial for enhancing sample quality. A subjective human evaluation (mean opinion score, MOS) of a single speaker dataset indicates that our proposed method demonstrates similarity to human quality while generating 22.05 kHz high-fidelity audio 167.9 times faster than real-time on a single V100 GPU. We further show the generality of HiFi-GAN to the mel-spectrogram inversion of unseen speakers and end-to-end speech synthesis. Finally, a small footprint version of HiFi-GAN generates samples 13.4 times faster than real time on CPU with comparable quality to an autoregressive counterpart.
Overall Architecture
HiFi-GAN consists of one generator and two discriminators: multi-scale and multi-period discrimina- tors. The generator and discriminators are trained adversarially, along with two additional losses for improving training stability and model performance.
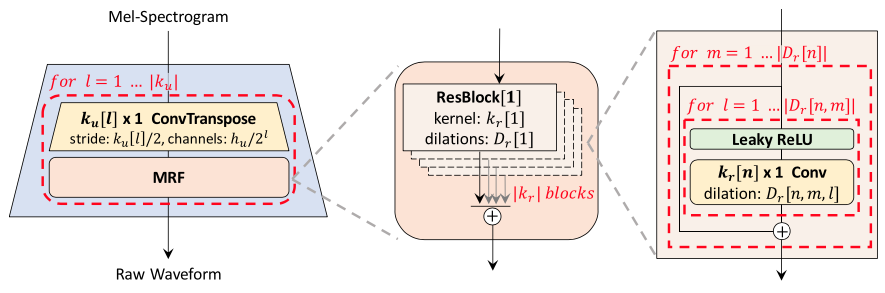
[ Figure 1 ] The generator upsamples mel-spectrograms up to \(\vert k_{u} \vert\) times to match the temporal resolution of raw waveforms. A MRF module adds features from \(\vert k_{r} \vert\) residual blocks of different kernel sizes and dilation rates. Lastly, the \(n\)-th residual block with kernel size \(k_{r}[n]\) and dilation rates \(D_{r}[n]\) in a MRF module is depicted.
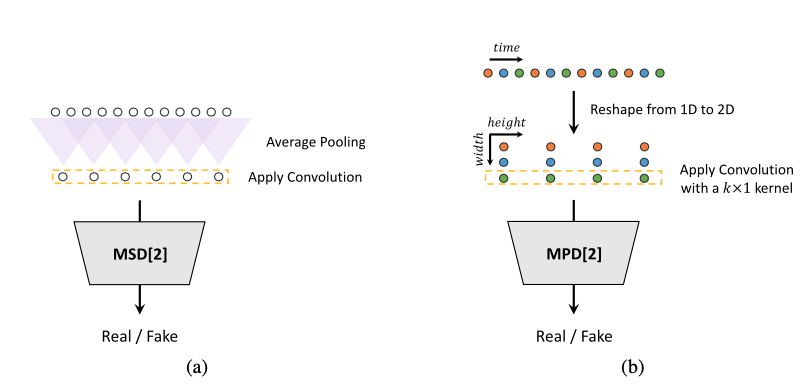
[ Figure 2 ] (a) The second sub-discriminator of the MSD. (b) The second sub-discriminator of the MPD with period 3.
Experiments
To evaluate the performance of our models in terms of both quality and speed, we performed the MOS test and the speed measurement. For easy comparison of audio quality, synthesis speed and model size, the results are compiled and presented in Table1. Remarkably, all variations of HiFi-GAN scored higher than the other model. Moreover, it shows a significant improvement in terms of synthesis speed.
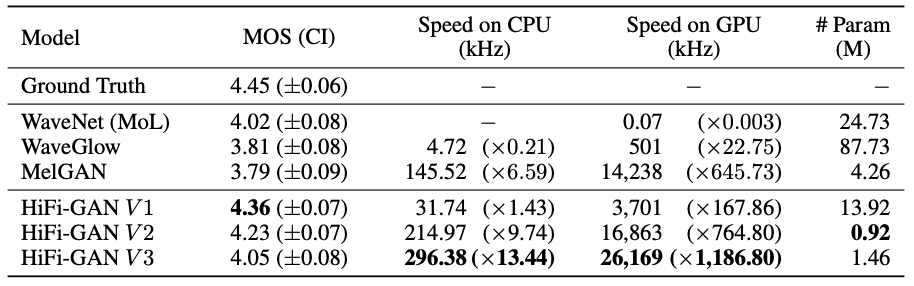
[ Table 1 ] Comparison of the MOS and the synthesis speed. Speed of n kHz means that the model can generate n × 1000 raw audio samples per second. The numbers in () mean the speed compared to real time.