NLP
Capturing Speaker Incorrectness: Speaker-Focused Post-Correction for Abstractive Dialogue Summarization
이동엽(카카오), 임정우(고려대), 황태선(와이즈넛), 이찬희(고려대), 조승우(카카오엔터프라이즈), 박민건(마이크로소프트), 임희석(고려대)NewSum workshop, EMNLP
2021-11-10
Abstract
In this paper, we focus on improving the quality of the summary generated by neural abstractive dialogue summarization systems.
Even though pre-trained language models generate well-constructed and promising results, it is still challenging to summarize the conversation of multiple participants since the summary should include a description of the overall situation and the actions of each speaker.
This paper proposes self-supervised strategies for speaker-focused post-correction in abstractive dialogue summarization. Specifically, our model first discriminates which type of speaker correction is required in a draft summary and then generates a revised summary according to the required type.
Experimental results show that our proposed method adequately corrects the draft summaries, and the revised summaries are significantly improved in both quantitative and qualitative evaluations.
카카오엔터프라이즈에서는 마치 사람처럼 대화 맥락(context)을 이해하고, 그 내용을 자연스럽게 요약할 수 있는 자연어 처리 기술을 연구하고 있습니다. 본 글에서는 카카오, 카카오엔터프라이즈와 고려대, 와이즈넛, 마이크로소프트 공동 연구팀이 발표한 새로운 대화 생성 요약 방법론에 대해 소개드리고자 합니다.
1. 기존 대화 요약 기술의 한계
기존 트랜스포머 기반 사전훈련 언어모델(PLM; BERT, BART, T5)이 많은 발전을 거듭하여 뛰어난 성능을 보임에도 불구하고, 여전히 여러 화자의 대화를 요약하는 상황에서 한계점이 있었습니다.
최근 많이 활용되는 생성 요약(abstractive summarization) 방식은 대화 내용에서 중요한 핵심 문장 또는 단어구 몇가지를 그대로 뽑아 요약하는 추출 요약(extractive summarization)과 달리, 대화 문맥을 고려해 새로운 문장을 만들어냅니다. 긴 시간 다수의 화자가 대화한 내용으로부터 핵심 키워드를 선별하여 가독성 좋은 요약문을 만드는게 핵심인데요. 이때 문장 구조나 언급된 표현의 수정으로, 보다 자연스럽고 깔끔한 형태의 요약문을 만들 수 있습니다. 다만 모델이 재해석한 내용을 바탕으로 만들어지기 때문에 내용이 잘못 요약될 수 있는 문제(Factual Consistency)를 안고 있는데요.
실제 100개의 테스트셋을 직접 사람이 분석한 결과 53%가 내용에 오류가 있었고, 이 중 절반 이상이 화자와 관련된 오류였습니다. 예를 들어 <그림1>과 같이 화자 정보가 바뀌는 경우인데요. 주로 화자와 관련된 엔티티(entity)나 릴레이션(relation) 서술에 오류가 있는 경우가 많았습니다. 본 연구에서는 이같은 문제를 해결하고자, 화자 중심의 대화문 사후 편집(post-correction)을 통한 생성 요약 방법론을 새롭게 제안하였습니다.

표1. 화자와 관련된 대화 요약 오류 예시
2. Capturing Speaker Incorrectness 방법론 소개
해당 방법론의 가장 큰 특징은 대화 요약 태스크에서 화자 중심의 사후 편집 전략을 적용했다는 점입니다. 해당 모델은 초안 요약(draft summary) 단계에서 잘못 언급된 화자 오류 유형을 먼저 찾고, 어떤 유형으로 이를 수정해야 될지 판단합니다. 이후 빠져있는 화자명을 추가하거나, 잘못 언급된 화자를 삭제, 혹은 교체하는 방식으로 요약 내용을 수정합니다. 최종적으로 수정된 결과 예시는 <표2>와 같습니다.
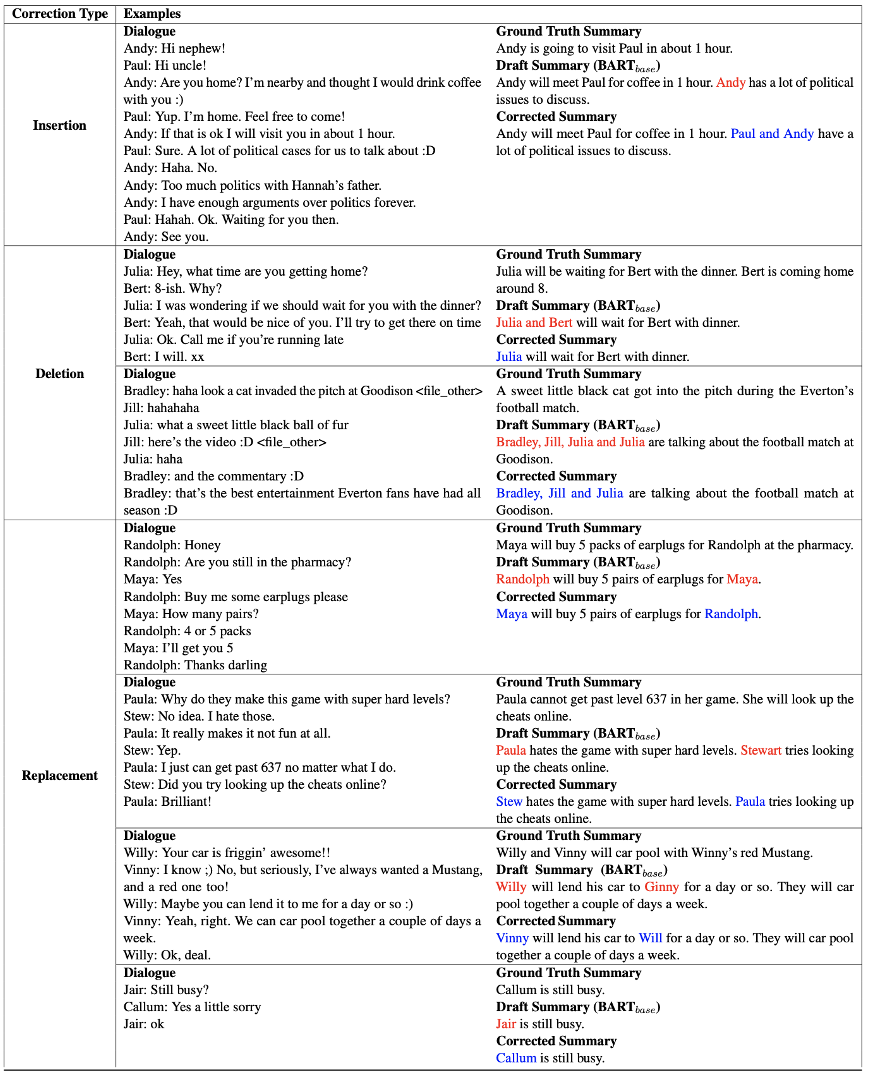
표2. 대화 교정 후 결과 예시 (빨간색 오류 부분을 파란색으로 수정)
일반적으로 생성 요약 학습에서는 레이블링된 요약문 데이터셋이 필요한데요. 해당 방법론에서는 자기지도학습(Self-supervised Learning) 전략을 사용하여 추가적인 어노테이션(annotation) 없이 학습 데이터를 구성하였습니다. 또한, 강건한 모델을 만들기 위해 학습 시에 대화 맥락과 초안 요약이 주어지면 화자 리스트를 구성하는 화자 생성기(speaker generator)를 보조 태스크로 진행하였습니다.
3. 성능 평가
실제 모델의 성능을 정량적, 정성적인 평가 기준으로 측정하였을 때, 초안 요약 결과와 수정된 요약 결과 모두에서 높은 성능을 보임을 확인하였습니다. 먼저 동일한 단어가 얼마나 많이 매칭되는지를 판단하는 기계 평가 메트릭 ROUGE 스코어를 활용했을 때, <표3>와 같은 성능 결과를 얻었습니다. 여기서 Correction Rate는 해당 모델에 의해 수정된 비율을 의미합니다.
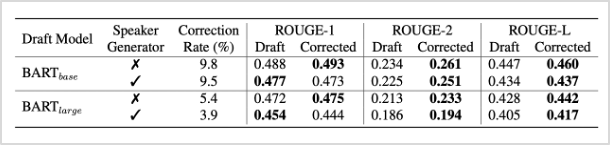
표3. 정량적인 성능 평가 결과 (ROUGE score)
ROUGE 스코어는 단어의 시멘틱 요소는 고려되지 않기 때문에, 정성적인 측면의 평가를 위해 Amazon Mechanical Turk(AMT)를 활용하여 <표3>과 같이 실제 사람의 평가를 진행하였습니다. 여기서도 우수한 성능을 보임을 확인할 수 있었습니다.
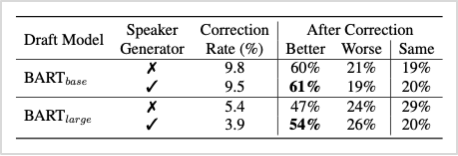
표4. 정성적인 성능 평가 결과 (Human Evaluation)
4. 향후 연구 계획
장시간의 대화를 요약하는 시스템은 회의록 작성 등 현재 다양한 분야에 활용되고 있습니다. 본 연구 결과는 카카오엔터프라이즈의 대화 요약 서비스의 적용되어 factual consistency 문제를 개선하는 데에 활용될 예정입니다. 앞으로도 카카오엔터프라이즈의 AI 연구와 서비스에 많은 관심 부탁드립니다. 감사합니다.
현재 카카오엔터프라이즈 AI Lab에서는 다양한 AI 연구와 서비스화를 함께 고민해나갈 여러분의 지원을 기다리고 있습니다. AI를 통해 더욱 가치있는 세상을 만들고, 꿈을 현실로 만들어가는 여정에 함께하세요!
👨🏻💻 인재영입