SPEECH/AUDIO
Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition
김의성(GIST/카카오엔터프라이즈), 송형찬(GIST), 신종원(GIST)SENSORS
2020-05-04
Abstract
In this paper, we propose a novel emotion recognition method based on the underlying emotional characteristics extracted from a conditional adversarial auto-encoder (CAAE), in which both acoustic and lexical features are used as inputs. The acoustic features are generated by calculating statistical functionals of low-level descriptors and by a deep neural network (DNN). These acoustic features are concatenated with three types of lexical features extracted from the text, which are a sparse representation, a distributed representation, and an affective lexicon-based dimensions. Two-dimensional latent representations similar to vectors in the valence-arousal space are obtained by a CAAE, which can be directly mapped into the emotional classes without the need for a sophisticated classifier. In contrast to the previous attempt to a CAAE using only acoustic features, the proposed approach could enhance the performance of the emotion recognition because combined acoustic and lexical features provide enough discriminant power. Experimental results on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) corpus showed that our method outperformed the previously reported best results on the same corpus, achieving 76.72% in the unweighted average recall.
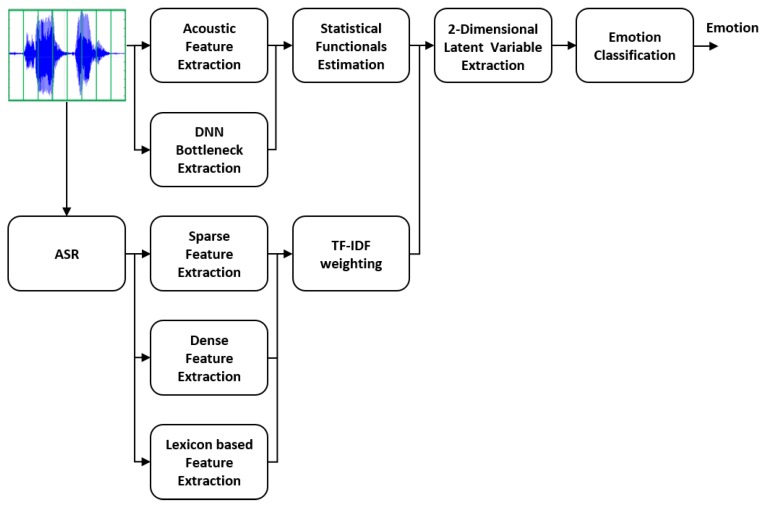
[ figure 1 ] Overview of the proposed multimodal emotion recognition framework integrating the acoustic and lexical features.