NLP
An Evaluation Dataset and Strategy for Building Robust Multi-turn Response Selection Model
한기종(카카오엔터프라이즈), 이서진(SK텔레콤), 이우인(카카오엔터프라이즈), 이주성(카카오엔터프라이즈), 이동훈(카카오엔터프라이즈)Empirical Methods in Natural Language Processing (EMNLP)
2021-11-07
Abstract
Multi-turn response selection models have recently shown comparable performance to humans in several benchmark datasets. However, in the real environment, these models often have weaknesses, such as making incorrect predictions based heavily on superficial patterns without a comprehensive understanding of the context. For example, these models often give a high score to the wrong response candidate containing several keywords related to the context but using the inconsistent tense. In this study, we analyze the weaknesses of the open-domain Korean Multi-turn response selection models and publish an adversarial dataset to evaluate these weaknesses. We also suggest a strategy to build a robust model in this adversarial environment.
카카오엔터프라이즈에서는 실제 사람처럼 자연스러운 대화가 가능한 오픈 도메인 챗봇 (open domain Chatbot)을 연구하고 있습니다. 현재 해당 기술은 AI 스피커 ‘카카오미니’, 종합 업무 플랫폼 ‘카카오워크’, 카카오톡채널 ‘외개인아가’ 등에 적용되어 있는데요.
챗봇이 실제 사람처럼 자연스럽게 대화를 하기 위해서는 대화 맥락(context)에 맞는 답변을 하는 것이 중요합니다. 이를 위해서는 주어진 응답 후보에서 가장 적절한 답변을 선택하는 응답 선택(Response Selection) 태스크를 잘 수행해야 합니다. 본 연구에서는 보다 자연스러운 한국어 챗봇 시스템 구현을 위한 응답 선택 모델 구성 전략과 강건성 평가 데이터셋을 새롭게 제안하였고, 깃허브 상에 해당 데이터셋을 공개하였습니다.
1. 기존 Multi-turn Response Selection 모델 연구의 한계
최근에는 실제 사람과 유사한 수준의 대화 성능을 보여주는 응답 선택 모델 연구 결과들이 다수 발표되었습니다. 하지만 이를 실서비스 환경에서 적용했을 때, 대화 맥락을 포괄적으로 이해하여 답변을 도출하는 것이 아니라, 피상적인 패턴에 크게 의존하여 잘못된 답변을 하는 문제가 있었습니다. 예를 들어 실제 의미 상으로는 틀린 시제나 부정표현을 사용하여 잘못된 답이지만, 대화 맥락과 관련된 키워드를 많이 사용하여 높은 점수를 받아 일어나는 현상인데요.
본 연구에서는 이러한 오류 패턴을 7가지 유형으로 분류하고, 이를 판단할 수 있는 데이터셋과 해당 환경에서 효과적인 모델을 구축하기 위한 전략을 제안하였습니다.
2. 평가 데이터셋과 방법론 소개
먼저 카카오엔터프라이즈 연구팀이 구축한 취약점 평가 데이터셋(adversarial dataset)은 <표1>과 같이 총 2220개의 테스트 케이스로 구성되어 있습니다. 이 케이스를 각각 7가지 오류 유형으로 구분하였습니다. 해당 유형으로는 이전 문장을 반복(Repetition)하거나, 부정어(Negation) 또는 시제(Tense)를 잘못 사용한 경우, 주체/대상을 혼동한 경우(Subject-Object), 모순 어휘(Lexcial Contradiction)를 사용한 경우, 토픽에 따른 화용적 오류(Topic)가 발생한 경우 등이 있습니다. 내부 서비스 로그에서 잘못 응답되거나, 빈번하게 발생하는 오류를 기준으로 유형을 분석하였습니다.
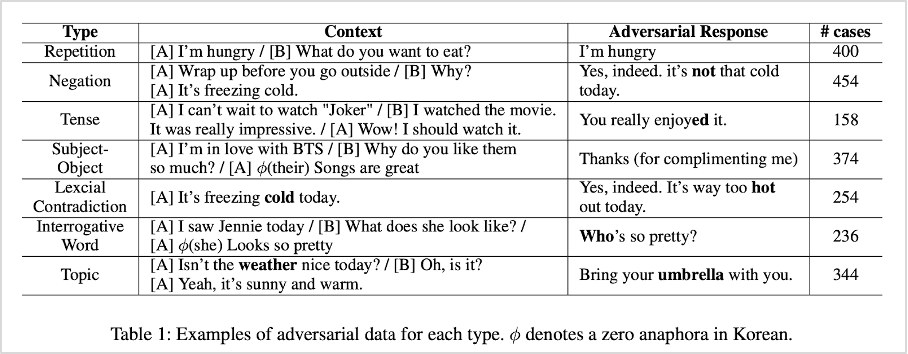
표1. 개별 오류 유형에 따른 평가 데이터셋 샘플
이 데이터셋은 실제 서비스 환경에서 오갈 수 있는 복잡한 응답에 대비하기 위해, 언어학 전문가의 상세한 지침 하에 어려운 답변으로 구성될 수 있게끔 수작업을 통해 구축되었습니다. 5명의 작업자(annotator)가 총 200개의 대화 세션을 작성하고, 각 세션에 대해 여러 개의 정답과 위 지침에 기반한 오답을 작성하였습니다.
또한, 강건한 모델을 구축하기 위한 두 가지의 전략을 제시하였습니다. 먼저 탈편향(debiasing) 전략입니다. 신경망(Neural Network)은 데이터의 쉽고 표층적인 패턴에 편향되게(biased) 학습되는 경향을 보입니다. 대화 데이터에서 적절한 답변은 보통 문맥에서 다룬 주제(Topic)에 기반하거나, 문맥에 나왔던 키워드들을 활용하는 경향을 보입니다. 본 연구팀은 모델이 주제와 키워드에 편향되게 학습되는 것을 취약점의 원인이라 보았습니다. 이에 DRiFt[1] 탈편향 알고리즘을 활용하여 <그림1>과 같이 전체적인 모델 구조를 설계하였고, 모델 성능을 향상시킬 수 있었습니다.
두 번째로는 멀티태스크 러닝과의 결합입니다. 최근 답변 선택 태스크에서는 UMS[2]와 같은 자기지도학습(Self-supervised Learning) 기반 멀티태스크 러닝을 활용한 기법이 우수한 성능을 보여주고 있습니다. 앞서 언급한 탈편향 기법과 UMS 기법을 결합하는 전략을 제시하여 더욱 향상된 성능을 얻을 수 있었습니다.
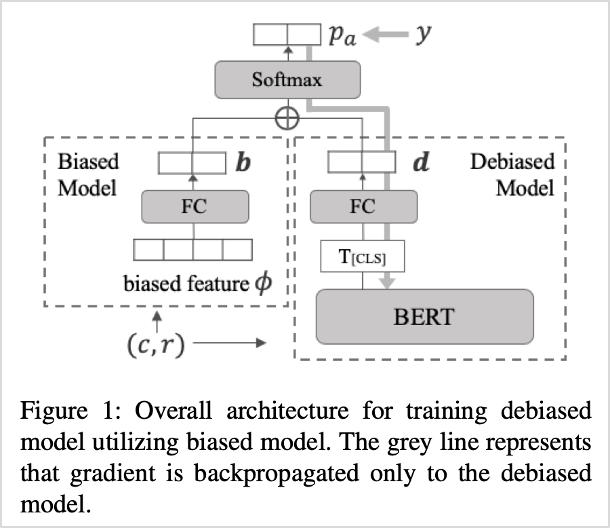
그림1. 전체적인 모델 구조
3. 성능 평가
실제 성능 평가는 아래 <표2>와 같은 데이터셋 구성으로 진행되었습니다. 각 데이터셋은 기존 학습 데이터와 동일한 방식으로 구축된 데이터(In-domain), 앞서 설명드린 연구팀이 새롭게 구축한 취약점 평가 데이터(Adv), 실제 서비스 환경과 동일한 방식의 데이터(Real)로 구성되었습니다.

표2. 데이터셋 구성
<표3>과 같이 탈편향 기법(deb)과 UMS 방법론을 결합한 전략이 취약점 평가 데이터(Adversarial)에서 baseline 모델 대비 +7.8%의 상당한 높은 성능 향상을 보였습니다. 또한, 실제 환경과 유사한 데이터셋(Real Env.)에서도 본 연구팀이 제시한 전략이 +4.2%의 성능 향상을 보였습니다. 이를 통해 Adversarial한 환경에서의 강건성이 실제 환경에서도 유효함을 확인하였습니다.
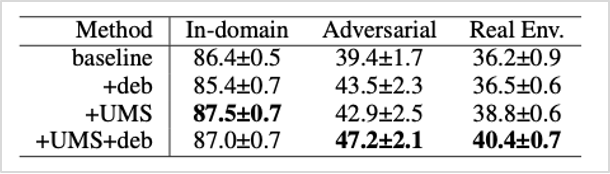
표3. 각 데이터셋과 방법론에 따른 성능 비교
<표4>는 본 연구팀이 제시한 전략이 기존 모델보다 잘 작동하는 예시입니다. 기존 baseline 모델은 단순히 ‘핸드폰’, ‘바꾸다’ 라는 키워드만 들어가있고, 문맥상 올바르지 않은 답변에 정답보다도 더 높은 0.998 이라는 점수를 주었습니다. 반면 제시한 전략을 활용하면 이와 같은 오답에 0.094라는 낮은 점수를 주는 것을 확인할 수 있었습니다.
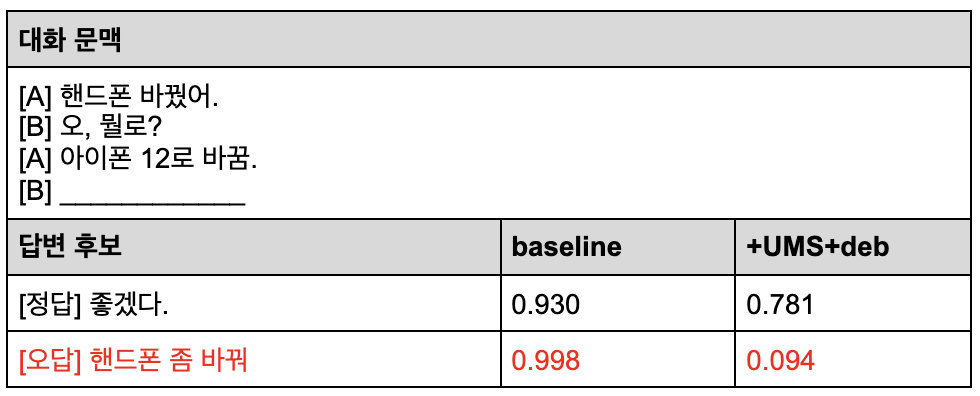
표4. 제안한 전략이 잘 작동하는 예시
4. 향후 연구 계획
현재 이 연구 결과는 외개인아가 챗봇의 답변 선택 로직에 적용되어 있습니다. 외개인아가는 대화 주제가 열려있는 비목적성 대화, 즉 일상 대화에 초점을 둔 챗봇입니다. 실제 사람 간의 대화를 살펴보면 일상 대화나 감정 교류 목적의 ‘스몰톡(small talk)’이 차지하는 비중이 높은데요. 카카오엔터프라이즈에서는 이러한 스몰톡에서 이전 대화 맥락을 반영하여 적절한 발화를 선택하는 기술을 지속적으로 연구해, 서비스를 고도화시켜 나갈 계획입니다. 앞으로도 카카오엔터프라이즈의 AI 연구와 서비스에 많은 관심 부탁드립니다. 감사합니다.
참조 문헌
[1] He et al., “Unlearn Dataset Bias in Natural Language Inference by Fitting the Residual”, EMNLP, 2019.
[2] Whang et al., “Do Response Selection Models Really Know What’s Next? Utterance Manipulation Strategies for Multi-turn Response Selection”, AAAI, 2021.
현재 카카오엔터프라이즈 AI Lab에서는 다양한 AI 연구와 서비스화를 함께 고민해나갈 여러분의 지원을 기다리고 있습니다. AI를 통해 더욱 가치있는 세상을 만들고, 꿈을 현실로 만들어가는 여정에 함께하세요!
👨🏻💻 인재채용