NLP
Sparse and Decorrelated Representations for Stable Zero-shot NMT
손보경(카카오엔터프라이즈), 류성원(카카오엔터프라이즈)Empirical Methods in Natural Language Processing (EMNLP) Findings of ACL
2020-11-16
카카오엔터프라이즈는 훈련 조건의 변화에도 강건한 제로샷 모델을 만들고자 SLNISparse coding through Local Neural Inhibition를 이용해 정규화regularization1를 시도했습니다. 그 결과, transformer 인코더를 구성하는 하위층에서 서로 무관하면서도 희소한 특징 벡터sparse and decorrelated representation가 생성됩니다. 카카오엔터프라이즈는 이 기법을 적용한 모델이 다양한 실험 조건 상에서 훈련된 방향의 번역 성능을 거의 그대로 유지하면서도, 제로샷에서 목표 언어의 문장을 안정적으로 생성해냄을 확인했습니다.
카카오엔터프라이즈는 후속 연구를 통해 제로샷 태스크가 훈련 조건 변화에 취약한 원인과 새로 제안한 기법의 문제 해결 원리를 파악하고, 번역 분야의 지속 학습continual learning2에 관한 새로운 탐색을 진행할 계획입니다.
Abstract
Using a single encoder and decoder for all directions and training with English-centric data is a popular scheme for multilingual NMT. However, zero-shot translation under this scheme is vulnerable to changes in training conditions, as the model degenerates by decoding non-English texts into English regardless of the target specifier token. We present that enforcing both sparsity and decorrelation on encoder intermediate representations with the SLNI regularizer efficiently mitigates this problem, without performance loss in supervised directions. Notably, effects of SLNI turns out to be irrelevant to promoting language-invariance in encoder representations.
Methods
SLNI is a regularizer that promotes sparse and decorrelated representations by penalizing correlation between neurons. We apply SLNI on the encoder-side. Outputs of every layer normalization(after both self-attention and position-wise feed-forward sublayers) are subject to regularization.
Experiments
Unlike the naive model, our model trained with SLNI shows stable performance across all training conditions, including the Compound setting where the naive model completely degenerates. Furthermore, there is no evident performance decrease in supervised directions.
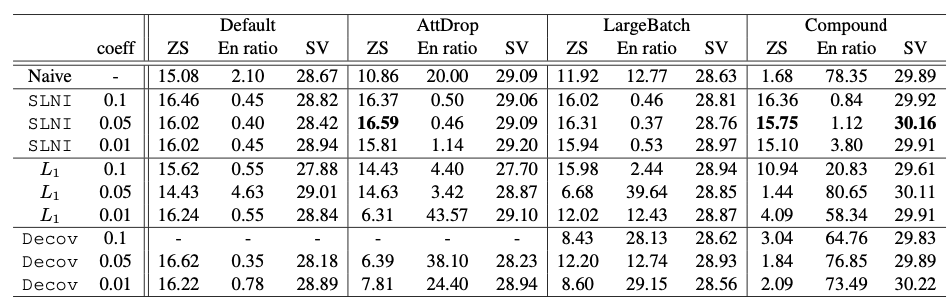
[ Table 1 ] Averaged BLEU scores for zero-shot(ZS) and supervised(SV) tasks, and ratio(%) of zero-shot outputs wrongly decoded into English.