NLP
Stable Style Transformer: Delete and Generate Approach with Encoder-Decoder for Text Style Transfer
이주성(카카오엔터프라이즈)International Conference on Natural Language Generation (INLG)
2020-12-15
카카오엔터프라이즈는 비병렬 데이터셋을 이용해 자연스러운 문장을 생성하는 새로운 텍스트 스타일 변환text style transfer 모델인 SSTStable Style Transformer를 제안했습니다. 텍스트 스타일 변환은 입력 문장의 내용content은 보전하면서, 문장의 속성attribute에 해당하는 값을 바꾸는 태스크를 가리킵니다.
SST의 스타일 변환은 두 단계를 걸쳐 진행됩니다. 첫 번째, 분류기를 통해 문장에서 속성을 표현하는 부분을 가리키는 토큰을 삭제합니다. 두 번째, 인코더와 디코더로 속성을 제외한 나머지 문장 토큰에 변환하려는 스타일을 합쳐서 문장을 생성합니다. 그 결과, 자동화된 평가 척도에서 문장이 안정적으로 합성됨을 확인할 수 있었습니다.
카카오엔터프라이즈는 텍스트 스타일 변환뿐만 아니라 사람의 감정이나 대화 상황을 이해하는 공감적 대화empathetic conversation, 데이터를 문장으로 표현하기data-to-text, 페르소나 채팅persona chat1과 같이 원하는 조건에 따라 문장을 생성하는 자연어 생성에 관한 다양한 연구를 진행할 계획입니다.
Abstract
Text style transfer is the task that generates a sentence by preserving the content of the input sentence and transferring the style. Most existing studies are progressing on non-parallel datasets because parallel datasets are limited and hard to construct. In this work, we introduce a method that follows two stages in non-parallel datasets. The first stage is to delete attribute markers of a sentence directly through a classifier. The second stage is to generate a transferred sentence by combining the content tokens and the target style. We experiment on two benchmark datasets and evaluate context, style, fluency, and semantic. It is difficult to select the best system using only these automatic metrics, but it is possible to select stable systems. We consider only robust systems in all automatic evaluation metrics to be the minimum conditions that can be used in real applications. Many previous systems are difficult to use in certain situations because performance is significantly lower in several evaluation metrics. However, our system is stable in all automatic evaluation metrics and has results comparable to other models. Also, we compare the performance results of our system and the unstable system through human evaluation.
Overall Architecture
Our approach consists of two stages: Delete and Generate framework in Fig. 1. The first stage is the Delete process with a pre-trained style classifier. The pre-trained style classifier finds and deletes tokens that contain a lot of style attributes. The second stage is encoding the content tokens and combining them with a target style to generate a sentence. Both the encoder and the decoder have the Transformer structure, which is better than RNN and robust to long dependency.
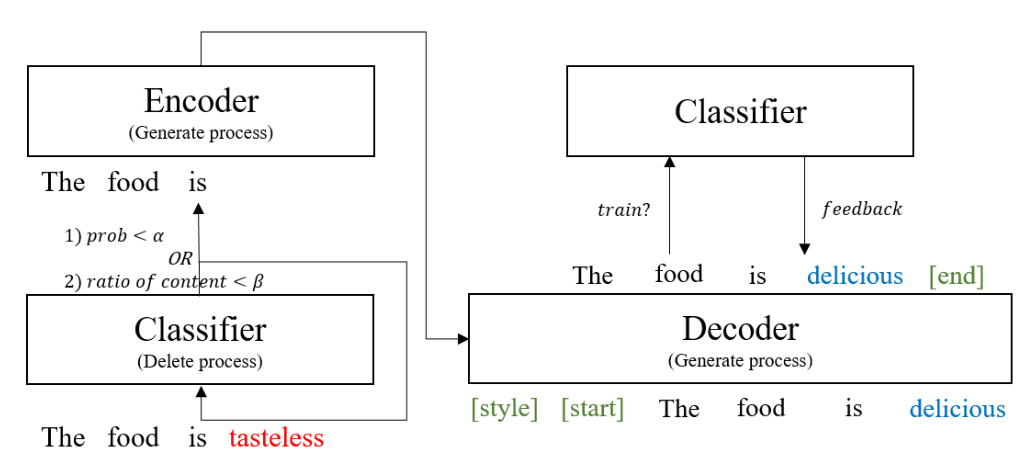
[ Figure 1 ] The proposed model framework consists of the Delete and Generate process. Experiments
We test our model on two datasets, YELP and AMAZON. The Yelp dataset is for business reviews, and the Amazon dataset is product reviews. Both datasets are labeled negative and positive and statistics are shown in Table 1.
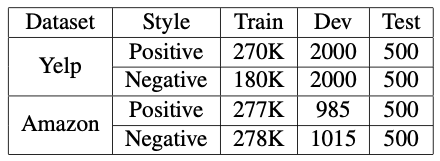
[ Table 1 ] (Sentiment) Dataset statistics
We show that filtering out unstable systems through human evaluation is expensive, so selecting a stable system through automatic evaluation can be helpful. The proposed direct and model-agnostic deletion method allows the classifier to intuitively delete attribute markers and easily handle the trade-off of content and style.
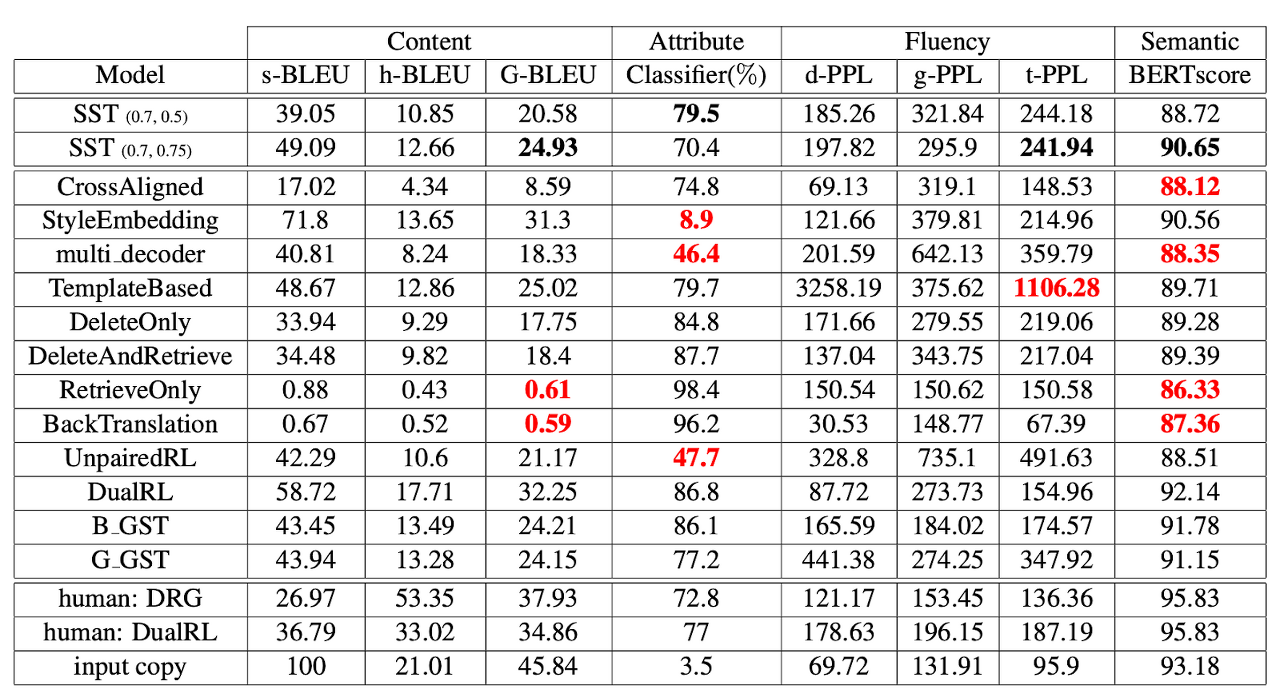
[ Table 2 ] Automatic evaluation results of the Yelp dataset (s: self, h: human, G: geometric mean, f: fine-tuned, p: pre-trained). The red indicates that the evaluation score is significantly worse than other systems. Our model is referred to as SST(α, β). The bold black indicates the better performance of our systems for the four metrics that determine it is a stable system.
Footnotes
-
시스템 설계자가 미리 정의한 고유 페르소나(인격)를 가진 가상의 상대와 대화를 나누는 태스크 ↩